
هوش مصنوعی پیشبینیکننده (یا تحلیلی) مجموعهای از الگوریتمها است که به شما در درک دادههای موجود و پیشبینی اتفاقات احتمالی بعدی کمک میکند. بر اساس الگوهای تاریخی، مدلهای هوش مصنوعی پیشبینیکننده، وظایف تحلیلی مختلفی را یاد میگیرند که به کاربران کمک میکند تا دادههای خود را درک کنند:
- طبقهبندی : اقلام را بر اساس الگوهای موجود در دادهها، در دستههای از پیش تعریفشده گروهبندی کنید. به عنوان مثال، یک فروشگاه آنلاین ممکن است بازدیدکنندگان را بر اساس قصد (تحقیق، خرید، مرجوعی) طبقهبندی کند، بنابراین میتواند توصیههای خود را بر این اساس تطبیق دهد.
- رگرسیون : مقادیر عددی مانند نرخ تعامل، مدت زمان جلسه یا احتمال تبدیل را پیشبینی کنید.
- پیشنهاد : مواردی را پیشنهاد دهید که بیشترین ارتباط را با یک کاربر یا زمینه خاص دارند. به این فکر کنید که «کاربرانی مانند شما نیز مشاهده کردهاند» یا «آموزشهای پیشنهادی بر اساس پیشرفت شما».
- پیشبینی و تشخیص ناهنجاری : این مدل رویدادهای آینده، مانند افزایش ناگهانی ترافیک، را پیشبینی میکند یا رفتارهای غیرمعمول، مانند ناهنجاریهای پرداخت یا کلاهبرداری را شناسایی میکند.
برخی از محصولات کاملاً مبتنی بر هوش مصنوعی پیشبینیکننده ساخته شدهاند، مانند ابزارهای کشف موسیقی. در برخی دیگر، هوش مصنوعی پیشبینیکننده، یک تجربه قطعی را بهبود میبخشد، مانند یک وبسایت پخش آنلاین با توصیههای شخصیسازیشده. هوش مصنوعی پیشبینیکننده همچنین میتواند یک توانمندساز داخلی قدرتمند باشد: میتوانید از آن برای تجزیه و تحلیل دادههای محصول و کاربر استفاده کنید تا بینشها را کشف کرده و اقدامات بعدی هوشمندانهتری را هدایت کنید.
حلقه پیشبینی هوش مصنوعی
توسعه یک سیستم هوش مصنوعی پیشبینیکننده از یک چرخه تکراری پیروی میکند: فرصت خود را تعریف کنید، دادههای خود را آماده کنید، مدل را آموزش دهید، مدل را ارزیابی کنید و مدل را مستقر کنید.
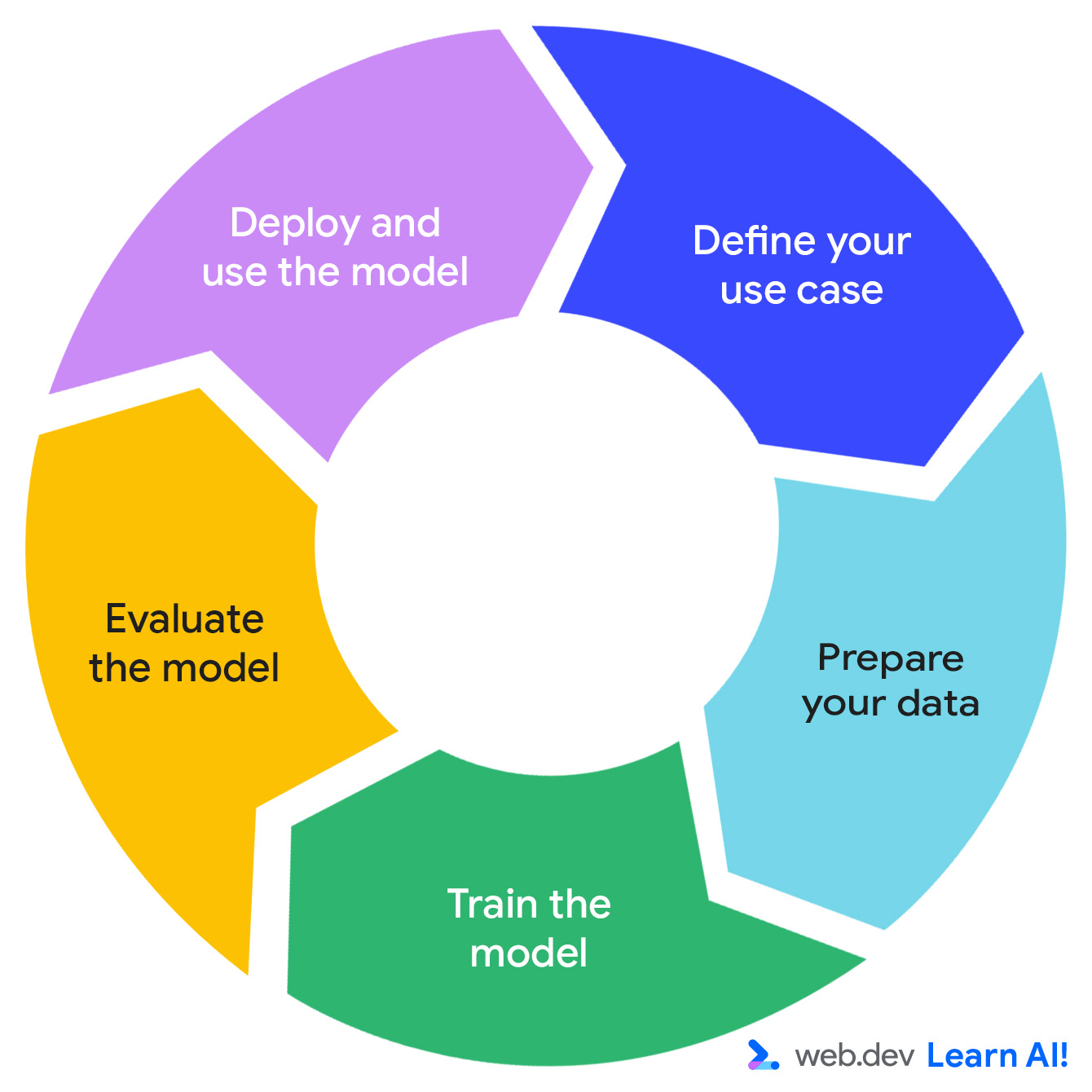
تصور کنید که روی یک اپلیکیشن بهرهوری مبتنی بر اشتراک به نام « همه کارها را انجام بده» کار میکنید. شما از قبل دادههای مربوط به میزان استفاده از اپلیکیشن مانند تعداد بازدید صفحات، مدت زمان استفاده، میزان استفاده از ویژگیها و تمدید اشتراک را جمعآوری کردهاید. اکنون میخواهید ارزش عملی بیشتری از این دادهها استخراج کنید. در اینجا نحوهی طی کردن حلقهی پیشبینی هوش مصنوعی را شرح میدهیم.
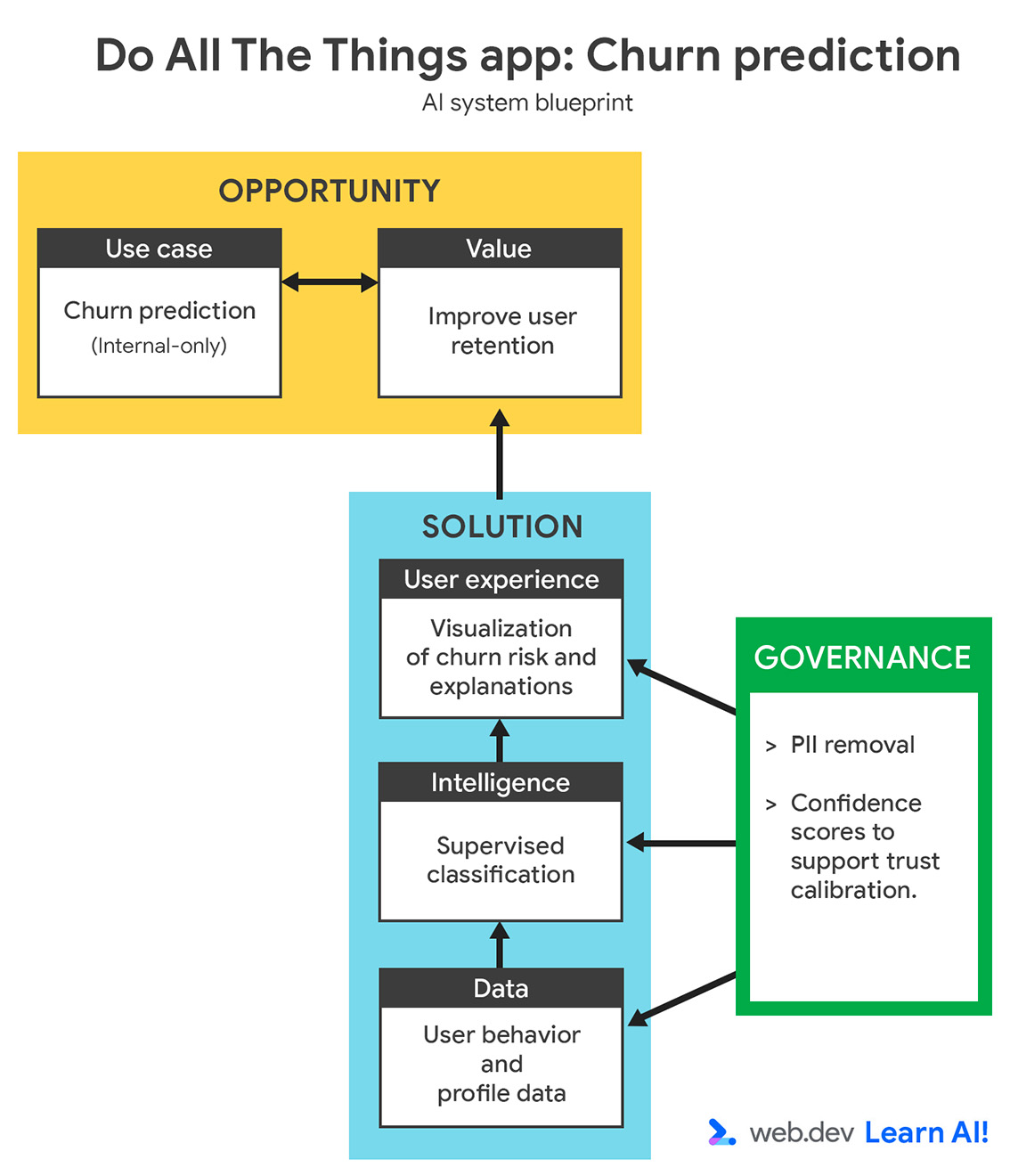
مورد استفاده خود را تعریف کنید
{kind=link}
نرخ ریزش شما در طول سه ماه گذشته افزایش یافته است. به جای واکنش نشان دادن پس از لغو عضویت کاربران، شما میخواهید از هوش مصنوعی پیشبینیکننده برای شناسایی کاربرانی که احتمال ریزش دارند، قبل از لغو عضویت، استفاده کنید. هدف این است که تیم موفقیت مشتری خود را با سیگنالهای اولیه پشتیبانی کنید تا بتوانند اقدامات هدفمند و پیشگیرانهای را برای حفظ کاربران در معرض خطر انجام دهند.
هنگام تعریف یک مورد استفاده پیشبینیکننده هوش مصنوعی، با اعتبارسنجی این موضوع شروع کنید که آیا سوال با دادهها قابل پاسخ است یا خیر. این دادهها میتوانند دادههایی باشند که قبلاً جمعآوری کردهاید یا دادههایی که میتوانید در آینده به طور واقعبینانه جمعآوری کنید. این مرحله اغلب نیاز به همکاری با متخصصان حوزه، مانند تیمهای موفقیت مشتری، رشد یا بازاریابی دارد تا اطمینان حاصل شود که پیشبینی هم معنادار و هم عملی است.
یک تعریف قوی از مسئله باید موارد زیر را مشخص کند:
- هدف : میخواهید بر کدام نتیجهی کسبوکار تأثیر بگذارید؟ برای مثال، میخواهید با فعال کردن ارتباطات پیشگیرانه، ریزش مشتری را کاهش دهید.
- دادههای ورودی : مدل از چه سیگنالهای تاریخی یاد میگیرد؟ برای مثال، شما الگوهای استفاده، انواع برنامهها و تعاملات پشتیبانی را ارائه میدهید.
- خروجی : مدل چه چیزی تولید خواهد کرد؟ برای مثال، شما میخواهید مدل برای هر کاربر یک امتیاز احتمال ریزش ایجاد کند.
- کاربر : چه کسی از پیشبینی استفاده میکند یا بر اساس آن عمل میکند؟ برای مثال، این دادهها برای مدیران موفقیت مشتری در نظر گرفته شده است.
- معیارهای موفقیت : چگونه تأثیر را اندازهگیری میکنید؟ برای مثال، شما نرخ حفظ مشتری را اندازهگیری میکنید تا مشخص شود که آیا ریزش مشتری را کاهش دادهاید یا خیر.
با شناسایی این جزئیات در ابتدا، میتوانید از یک تله رایج جلوگیری کنید: ساخت یک مدل سفارشی که از نظر فنی بینقص است، اما هرگز مورد استفاده قرار نمیگیرد.
آمادهسازی دادهها
برای ارائه سیگنالهای یادگیری مفید به مدل خود، باید دادههای تاریخی خود را با پیشبینیهای ایدهآل برچسبگذاری کنید. کاربران Do All The Things را به عنوان "حذفشده" یا "عدم حذفشده" برچسبگذاری کنید.
در مرحله بعد، با تیم موفقیت مشتری خود همکاری کنید تا مشخص کنید کدام ویژگیهای رفتاری بیشترین ارتباط را با پیشبینی ریزش مشتری دارند. مجموعه دادههای خود را به این ویژگیهای کلیدی محدود کنید و فیلدهای غیرضروری را حذف کنید تا مدل شما نیازی به سروکله زدن با نویز نداشته باشد. به یاد داشته باشید که حریم خصوصی دادهها را در نظر بگیرید. اطلاعات شخصی قابل شناسایی (PII)، مانند نام یا ایمیل را حذف کنید و فقط دادههای رفتاری تجمیعی را ذخیره کنید.
جدول زیر گزیدهای از مجموعه دادههای حاصل از شما را نشان میدهد:
user_id | plan_type | avg_session_time (min) | logins_last_30d | features_used | support_tickets | churned |
| ۰۰۱۲۳ | حق بیمه | ۱۲.۴ | ۲۲ | ۵ | 0 | 0 |
| ۰۰۱۲۴ | محاکمه | ۵.۸ | ۳ | ۱ | ۲ | ۱ |
| ۰۰۱۲۵ | رایگان | ۱۸.۱ | ۳۰ | ۷ | 0 | 0 |
| ۰۰۱۲۶ | حق بیمه | ۹.۷ | ۱۲ | ۴ | ۱ | 0 |
| ۰۰۱۲۷ | محاکمه | ۴.۲ | ۲ | ۱ | ۳ | ۱ |
این به مدل شما ورودیهای عددی و دستهبندیشدهی تمیز (مانند plan_type یا avg_session_time ) و یک برچسب هدف واضح ( churned ) میدهد. دستهبندیها باید به شناسههای عددی منحصر به فرد تبدیل شوند.
در نهایت، مجموعه دادههای خود را به سه زیرمجموعه تقسیم کنید:
- مجموعه آموزشی (معمولاً حدود ۷۰ تا ۸۰٪) برای آموزش مدل،
- مجموعه اعتبارسنجی (که گاهی اوقات مجموعه توسعه نیز نامیده میشود) برای تنظیم ابرپارامترها و جلوگیری از بیشبرازش.
- مجموعه تست برای ارزیابی عملکرد مدل روی دادههای کاملاً دیده نشده.
این به مدل شما کمک میکند تا به جای تکیه بر مثالهای تاریخی حفظشده، تصمیمات را تعمیم دهد.
مدل را آموزش دهید
برخلاف هوش مصنوعی مولد ، که اغلب بر اساس مدلهای بزرگ و از پیش آموزشدیده ساخته میشود، اکثر سیستمهای هوش مصنوعی پیشبینیکننده به مدلهای خودآموزشدیده متکی هستند. دلیل این امر آن است که وظایف پیشبینیکننده به شدت مختص محصول و کاربران شما هستند. ابزارهایی مانند scikit-learn (پایتون)، AutoML (بدون کد یا کم کد) یا TensorFlow.js (جاوااسکریپت) آموزش و ارزیابی مدلهای پیشبینیکننده را بدون نگرانی در مورد ریاضیات زیربنایی آسانتر میکنند.
در مثال ریزش، مجموعه آموزشی پاکسازیشده را به یک الگوریتم طبقهبندی نظارتشده، مانند رگرسیون لجستیک یا شبکه عصبی ، میدهیم. چندین گزینه را امتحان کنید تا مشخص شود کدام یک برای دادههای شما بهتر عمل میکند.
مدل شما یاد میگیرد که کدام الگوهای رفتاری با ریزش کاربران مرتبط هستند. در نهایت، میتواند به هر کاربر یک امتیاز احتمال اختصاص دهد. برای مثال، ۷۲٪ احتمال دارد که کاربر X ماه آینده از برنامه خارج شود.
پس از هر تکرار آموزش، مدل حاصل را با استفاده از مجموعه اعتبارسنجی ارزیابی کنید. عملکرد یک مدل را میتوان با تنظیم پارامترهای فوق ، و همچنین با ایجاد بهبودهای هدفمند در مجموعه دادههای خود، بهبود بخشید.
مدل را ارزیابی کنید
برچسبهای موجود در مجموعه دادههای شما، اطلاعات پایهای را ارائه میدهند که میتوانید خروجیهای مدل را با آنها مقایسه کنید. معیارهای کلیدی برای ردیابی عبارتند از:
- دقت : از بین تمام کاربرانی که به عنوان «حذفشده» علامتگذاری شدهاند، چند نفر واقعاً حذف شدهاند؟
- به یاد بیاورید : از بین تمام کاربرانی که از سیستم رویگردان شدند، مدل چند نفر را جذب کرد؟
- امتیاز F1 : یک عدد واحد که بین دقت و فراخوانی تعادل برقرار میکند و زمانی مفید است که میخواهید یک معیار کلی از دقت داشته باشید، بدون اینکه یکی را بیش از حد بهینه کنید و دیگری را از دست بدهید.
تعداد زیاد هشدارهای کاذب منجر به هدر رفتن تلاشهای حفظ مشتری میشود، در حالی که تعداد زیاد هشدارهای کاذب منجر به از دست دادن مشتریان میشود. انتخاب بین این دو مورد به اولویتهای تجاری شما بستگی دارد. به عنوان مثال، شرکت شما ممکن است ترجیح دهد با چند هشدار کاذب سر و کار داشته باشد اگر این کار احتمال شناسایی کاربران بیشتر قبل از ترک شرکت را افزایش میدهد.
استقرار و نگهداری مدل
پس از اعتبارسنجی، میتوانید مدل را با یک API یا به عنوان یک سرویس سبک سمت کلاینت که در داشبورد تحلیلی شما ادغام شده است، مستقر کنید. هر روز، میتواند به کاربران امتیاز دهد و تجسم ریسک ریزش را بهروزرسانی کند و به تیم شما اجازه دهد تا اولویتبندیهای مربوط به اطلاعرسانی را انجام دهد. برای حفظ دقت و قابلیت اطمینان آن، این درسها را از تیمهای عملیاتی یادگیری ماشین (MLops) بیاموزید:
- نظارت بر تغییر دادهها : تشخیص دهید چه زمانی رفتار کاربر تغییر میکند و دادههای آموزشی شما دیگر نشاندهنده واقعیت نیستند.
- برای مثال، پس از راهاندازی یک طراحی مجدد رابط کاربری (UI) اساسی، کاربران با ویژگیها به طور متفاوتی تعامل میکنند و این باعث میشود پیشبینیهای ریزش (rung prediction) دقت کمتری داشته باشند.
- از اشتباهات درس بگیرید : الگوهای رایج پشت پیشبینیهای اشتباه را شناسایی کنید و مثالهای هدفمندی برای بهبود چرخه آموزش بعدی اضافه کنید.
- برای مثال، این مدل اغلب کاربران حرفهای را به دلیل باز کردن تیکتهای پشتیبانی متعدد، در معرض ریسک ریزش قرار میدهد. پس از بررسی، ویژگیهای جدیدی اضافه میکنید که عیبیابی را از قطع همکاری متمایز میکند.
- آموزش مجدد منظم : حتی اگر عملکرد پایدار به نظر میرسد، مدل را به صورت دورهای بهروزرسانی کنید تا الگوهای فصلی، بهروزرسانیهای محصول یا تغییرات قیمت را در نظر بگیرید.
- برای مثال، شما مدل را پس از معرفی طرحهای سالانه، دوباره آموزش میدهید، زیرا ساختار قیمتگذاری نحوه رفتار کاربران را قبل از تمدید تغییر میدهد.
این چرخه حیات، ستون فقرات هوش مصنوعی پیشبینیکننده است. با ابزارهایی مانند MLflow و Weights & Biases ، میتوانید این فرآیند را بدون تخصص عمیق در زمینه یادگیری ماشین اجرا کنید.
مشکلات رایج و راهکارهای کاهش آنها
اگرچه گاهی اوقات خطاهایی رخ میدهد، میتوانید از علل ریشهای رایج که میتوانند عملکرد و اعتماد کاربر را تضعیف کنند، جلوگیری کنید:
- دادههای کمکیفیت : اگر دادههای ورودی شما نویزدار یا ناقص باشند، پیشبینیهای شما نیز ناقص خواهند بود. برای کاهش، مصورسازی و اعتبارسنجی دادهها قبل از آموزش، مطمئن شوید که سیگنالهای یادگیری مورد نیاز را دارید و مقادیر از دست رفته را مدیریت میکنید. کیفیت دادهها را در تولید نظارت کنید.
بیشبرازش : مدل روی دادههای آموزشی عملکرد بسیار خوبی دارد، اما در موارد جدید با شکست مواجه میشود. برای کاهش این مشکل، از اعتبارسنجی متقابل ، منظمسازی و مجموعه دادههای holdout استفاده کنید. این به مدل شما کمک میکند تا فراتر از نمونههای آموزشی تعمیم یابد.
رانش دادهها : رفتار و محیط کاربر تغییر میکند، اما مدل شما تغییر نمیکند. برای کاهش آن، آموزش مجدد را برنامهریزی کنید و نظارت را برای تشخیص زمان شروع افت دقت اضافه کنید.
معیارهای بد : دقت کلی همیشه منعکس کننده اولویتهای کاربران شما نیست. برای مثال، گاهی اوقات، "هزینه" یک اشتباه خاص اهمیت بیشتری دارد. در تشخیص تقلب، از دست دادن یک مورد تقلب (منفی کاذب) بسیار بدتر از علامت گذاری یک مورد بیگناه (مثبت کاذب) است. برای کاهش، معیارها را با اهداف دنیای واقعی برای تشخیص تقلب همسو کنید.
بیشتر این مشکلات مهلک نیستند. سیستم خود را به تدریج راهاندازی کنید و به محض بروز مشکلات، به آنها رسیدگی کنید.
کلید این رویکرد انعطافپذیر و کمحجم، قابلیت مشاهده است. مدلهای خود را نسخهبندی کنید، ویژگیهای دقت و ابزارهای مورد استفاده برای ساخت مدل را ثبت کنید، عملکرد را در طول زمان پیگیری کنید و نظارت را فعال نگه دارید. وقتی چیزی دچار انحراف یا مشکل میشود، میتوانید قبل از اینکه کاربران متوجه شوند، مشکل را تشخیص داده و برطرف کنید.
نکات مهم شما
هوش مصنوعی پیشبینیکننده، دادههای موجود شما را به پیشبینی تبدیل میکند و نشان میدهد که احتمالاً در مرحله بعد چه اتفاقی میافتد و کجا باید اقدام کرد. این ملموسترین و قابل اندازهگیریترین شکل هوش مصنوعی است. روی مشکلات تعریفشدهای که میتوانند در دادهها بیان شوند تمرکز کنید، همزمان با تکامل محصول خود، تکرار کنید و عملکرد را در طول زمان رصد کنید.
در ماژول بعدی ما، در مورد هوش مصنوعی مولد (generative AI) خواهید آموخت، که به شما کمک میکند بر اساس دادههای موجود، چیز جدیدی خلق کنید.
منابع
اگر به درک ریاضیات پشت هوش مصنوعی پیشبینیکننده علاقهمند هستید، توصیه میکنیم این منابع را مرور کنید:
- دورههای فشرده یادگیری ماشین در زمینه طبقهبندی ، رگرسیون خطی و رگرسیون لجستیک .
- نویسنده دوره شما، جانا لیپنکووا، در فصل ۴ کتاب «هنر توسعه محصول هوش مصنوعی: ارائه ارزش تجاری» درباره موضوع هوش مصنوعی پیشبینیکننده بیشتر نوشته است.
- هوش مصنوعی: رویکردی مدرن نوشتهی استوارت جاناتان راسل و پیتر نورویگ. این کتاب ابتدا در سال ۱۹۹۵ منتشر شد و آخرین ویرایش آن در سال ۲۰۲۱ منتشر شده است. این کتاب معمولاً در برنامههای مهندسی هوش مصنوعی تدریس میشود.
- تشخیص الگو و یادگیری ماشینی توسط کریستوفر ام. بیشاپ، برای رویکردی بسیار جامع و آکادمیک به یادگیری پیشبینیکننده هوش مصنوعی.
درک خود را بررسی کنید
عملکرد اصلی هوش مصنوعی پیشبین چیست؟
کدام وظیفه شامل گروهبندی اقلام در دستههای از پیش تعریفشده بر اساس الگوها است؟
در «حلقه هوش مصنوعی پیشبینیکننده»، چرا باید مجموعه دادهها را به مجموعههای آموزش، اعتبارسنجی و آزمایش تقسیم کنید؟
کدام معیار، دقت و فراخوانی را متعادل میکند تا معیاری کلی از دقت ارائه دهد؟