
अनुमान लगाने वाला (या विश्लेषण करने वाला) एआई, एल्गोरिदम का एक कलेक्शन होता है. इससे आपको मौजूदा डेटा को समझने और यह अनुमान लगाने में मदद मिलती है कि आगे क्या हो सकता है. अनुमान लगाने वाले एआई मॉडल, पिछले पैटर्न के आधार पर अलग-अलग तरह के विश्लेषण करना सीखते हैं. इससे उपयोगकर्ताओं को अपने डेटा को समझने में मदद मिलती है:
- क्लासिफ़िकेशन: डेटा में मौजूद पैटर्न के आधार पर, आइटम को पहले से तय की गई कैटगरी में ग्रुप करना. उदाहरण के लिए, कोई ऑनलाइन दुकान, वेबसाइट पर आने वाले लोगों को उनकी दिलचस्पी के हिसाब से कैटगरी में बांट सकती है. जैसे, रिसर्च, खरीदारी, और रिटर्न. इससे वह लोगों को उनकी दिलचस्पी के हिसाब से सुझाव दिखा सकती है.
- रिग्रेशन: इससे संख्यात्मक वैल्यू का अनुमान लगाया जा सकता है. जैसे, यूज़र ऐक्टिविटी की दर, सेशन की अवधि या कन्वर्ज़न की संभावना.
- सुझाव: किसी उपयोगकर्ता या कॉन्टेक्स्ट के हिसाब से सबसे काम के आइटम के सुझाव दें. "आपकी तरह के उपयोगकर्ताओं ने इन्हें भी देखा" या "आपकी प्रोग्रेस के आधार पर सुझाए गए ट्यूटोरियल" के बारे में सोचें.
- पूर्वानुमान और गड़बड़ी का पता लगाना: मॉडल, आने वाले समय में होने वाले इवेंट का अनुमान लगाता है. जैसे, ट्रैफ़िक में अचानक बढ़ोतरी. इसके अलावा, यह असामान्य व्यवहार की पहचान करता है. जैसे, पेमेंट से जुड़ी गड़बड़ियां या धोखाधड़ी.
कुछ प्रॉडक्ट पूरी तरह से अनुमान लगाने वाले एआई पर आधारित होते हैं. जैसे, संगीत खोजने के टूल. अन्य मामलों में, अनुमान लगाने वाले एआई से, तय किए गए अनुभव को बेहतर बनाया जाता है. जैसे, निजी सुझाव देने वाली स्ट्रीमिंग वेबसाइट. अनुमान लगाने वाले एआई का इस्तेमाल, कंपनी के अंदरूनी कामों को बेहतर बनाने के लिए भी किया जा सकता है. इसका इस्तेमाल, प्रॉडक्ट और उपयोगकर्ता के डेटा का विश्लेषण करने के लिए किया जा सकता है. इससे अहम जानकारी मिलती है और आने वाले समय में बेहतर फ़ैसले लेने में मदद मिलती है.
अनुमान लगाने वाले एआई का लूप
अनुमान लगाने वाले एआई सिस्टम को डेवलप करने के लिए, इन चरणों को बार-बार दोहराया जाता है: मौके की पहचान करना, डेटा तैयार करना, मॉडल को ट्रेन करना, मॉडल का आकलन करना, और मॉडल को डिप्लॉय करना.
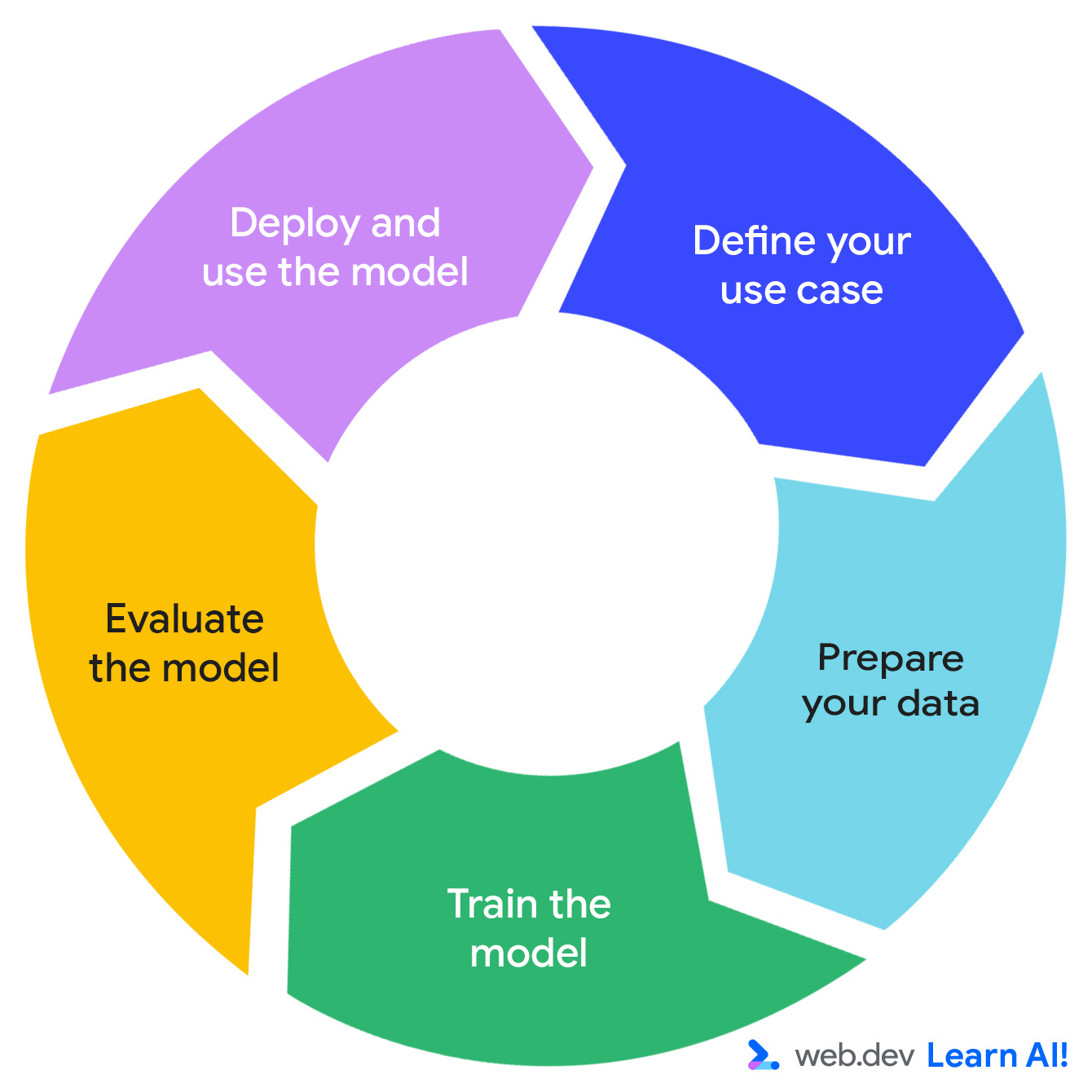
मान लें कि आपको सदस्यता पर आधारित किसी प्रॉडक्टिविटी ऐप्लिकेशन, Do All The Things पर काम करना है. आपके पास पहले से ही इस्तेमाल से जुड़ा डेटा इकट्ठा करने का विकल्प होता है. जैसे, पेज व्यू, सेशन की अवधि, सुविधा का इस्तेमाल, और सदस्यता रिन्यूअल. अब आपको डेटा से ज़्यादा काम की वैल्यू निकालनी है. यहां बताया गया है कि अनुमान लगाने वाले एआई के लूप में कैसे काम किया जाता है.
तय करें कि आपको डेटा का इस्तेमाल किस काम के लिए करना है
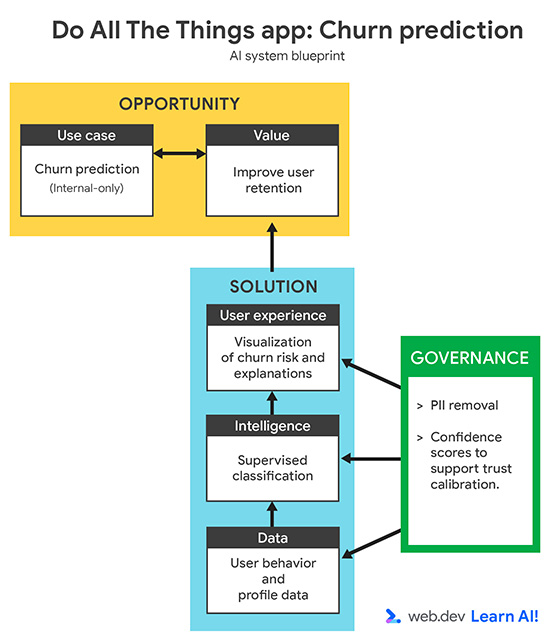
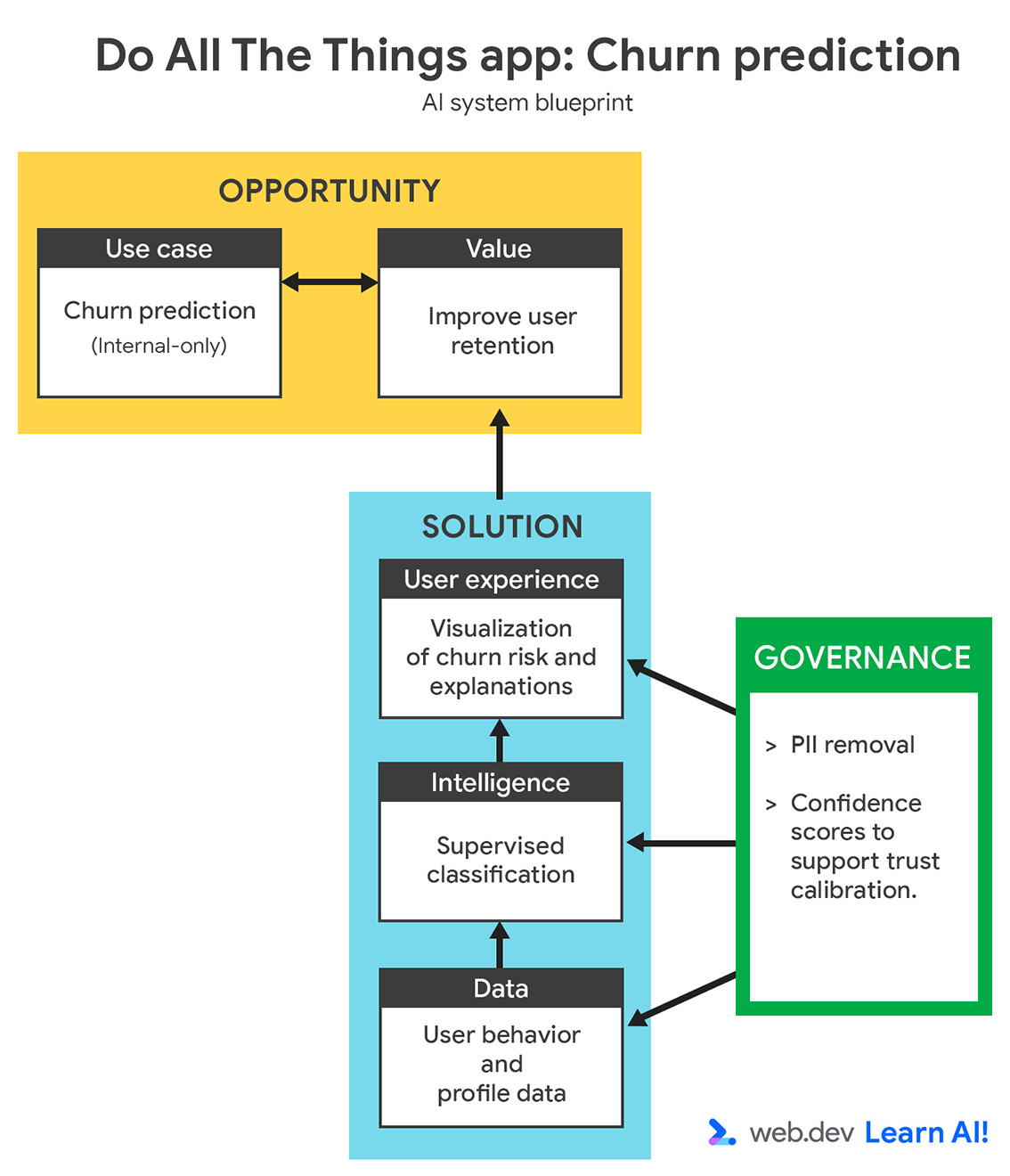{kind=link}
पिछले तीन महीनों में, आपके ऐप्लिकेशन को अनइंस्टॉल करने वाले लोगों की संख्या बढ़ी है. आपको सदस्यता रद्द करने वाले उपयोगकर्ताओं के लिए, एआई की मदद से अनुमान लगाने वाली सुविधा का इस्तेमाल करना है. इससे, सदस्यता रद्द करने से पहले ही उन उपयोगकर्ताओं की पहचान की जा सकेगी जिनके सदस्यता रद्द करने की संभावना है. इसका मकसद, आपकी ग्राहक सहायता टीम को शुरुआती सिग्नल देना है, ताकि वे जोखिम में पड़े उपयोगकर्ताओं को बनाए रखने के लिए, लक्षित और सक्रिय कार्रवाइयां कर सकें.
अनुमान लगाने वाले एआई के इस्तेमाल के उदाहरण को तय करते समय, सबसे पहले यह पुष्टि करें कि सवाल का जवाब डेटा की मदद से दिया जा सकता है. यह ऐसा डेटा हो सकता है जिसे आपने पहले ही इकट्ठा कर लिया है या ऐसा डेटा जिसे आने वाले समय में इकट्ठा किया जा सकता है. इस चरण में, अक्सर डोमेन के विशेषज्ञों के साथ मिलकर काम करना पड़ता है. जैसे, ग्राहक की सफलता, ग्रोथ या मार्केटिंग टीम. इससे यह पक्का किया जा सकता है कि अनुमान सही हो और उस पर कार्रवाई की जा सके.
समस्या के बारे में साफ़ तौर पर जानकारी देने से, इन बातों का पता चलता है:
- लक्ष्य: आपको कारोबार के किस नतीजे पर असर डालना है? उदाहरण के लिए, आपको ग्राहकों के जाने की दर कम करनी है. इसके लिए, आपको ग्राहकों से पहले ही संपर्क करना है.
- इनपुट डेटा: मॉडल, पुराने किन सिग्नल से सीखता है? उदाहरण के लिए, इस्तेमाल के पैटर्न, प्लान के टाइप, और सहायता से जुड़े इंटरैक्शन की जानकारी.
- आउटपुट: मॉडल क्या जनरेट करेगा? उदाहरण के लिए, आपको मॉडल से हर उपयोगकर्ता के लिए, चर्न की संभावना का स्कोर जनरेट कराना है.
- उपयोगकर्ता: अनुमान का इस्तेमाल कौन करता है या इस पर कार्रवाई कौन करता है? उदाहरण के लिए, यह डेटा ग्राहक की सफलता से जुड़े मैनेजर के लिए है.
- सक्सेस क्राइटेरिया: असर का आकलन कैसे किया जाता है? उदाहरण के लिए, अगर आपको यह पता लगाना है कि आपने चर्न रेट को कम किया है या नहीं, तो इसके लिए आपको उपयोगकर्ता बनाए रखने की दर को मेज़र करना होगा.
शुरुआत में इन बातों का पता लगाकर, इस आम समस्या से बचा जा सकता है: तकनीकी तौर पर बेहतर कस्टम मॉडल बनाना, लेकिन उसका कभी इस्तेमाल न करना.
डेटा तैयार करना
अपने मॉडल को काम के लर्निंग सिग्नल देने के लिए, आपको अपने पुराने डेटा को सटीक अनुमानों के साथ लेबल करना होगा. Do All The Things ऐप्लिकेशन इस्तेमाल करने वाले लोगों को "छोड़ दिया" या "नहीं छोड़ा" के तौर पर लेबल करो.
इसके बाद, ग्राहक की सफलता से जुड़ी टीम के साथ मिलकर काम करें. इससे यह पता लगाया जा सकेगा कि ग्राहक के व्यवहार से जुड़ी कौनसी सुविधाएं, ग्राहक के कारोबार छोड़ने की संभावना का अनुमान लगाने के लिए सबसे ज़्यादा काम की हैं. अपने डेटासेट को इन मुख्य सुविधाओं के हिसाब से छोटा करें और गैर-ज़रूरी फ़ील्ड हटाएं, ताकि आपके मॉडल को नॉइज़ से निपटने की ज़रूरत न पड़े. डेटा की निजता का ध्यान रखना न भूलें. व्यक्तिगत पहचान से जुड़ी जानकारी (पीआईआई), जैसे कि नाम या ईमेल पते हटाएं. साथ ही, सिर्फ़ एग्रीगेट किया गया व्यवहार डेटा सेव करें.
यहां दी गई टेबल में, आपके नतीजे वाले डेटासेट का एक हिस्सा दिखाया गया है:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | प्रीमियम | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | मुफ़्त में आज़माने की सुविधा | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | बिना किसी शुल्क के यह ऑफ़र पाएं | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | प्रीमियम | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | मुफ़्त में आज़माने की सुविधा | 4.2 | 2 | 1 | 3 | 1 |
इससे आपके मॉडल को साफ़ तौर पर संख्यात्मक और कैटगरी वाले इनपुट (जैसे, plan_type या avg_session_time) और साफ़ तौर पर टारगेट लेबल (churned) मिलते हैं.
कैटगरी को यूनीक न्यूमेरिक आइडेंटिफ़ायर में बदला जाना चाहिए.
आखिर में, अपने डेटासेट को तीन सबसेट में बांटें:
- ट्रेनिंग सेट (आम तौर पर 70 से 80%) का इस्तेमाल मॉडल को सिखाने के लिए किया जाता है,
- हाइपरपैरामीटर को ट्यून करने और ओवरफ़िटिंग को रोकने के लिए, पुष्टि करने वाला सेट (कभी-कभी इसे डेवलपमेंट सेट भी कहा जाता है).
- टेस्ट सेट का इस्तेमाल, यह आकलन करने के लिए किया जाता है कि मॉडल ने कभी न देखे गए डेटा पर कैसा परफ़ॉर्म किया है.
इससे आपका मॉडल, याद किए गए पुराने उदाहरणों पर भरोसा करने के बजाय, सामान्य फ़ैसले ले पाता है.
मॉडल को ट्रेनिंग देना
जनरेटिव एआई को अक्सर बड़े और पहले से ट्रेन किए गए मॉडल पर बनाया जाता है. हालांकि, अनुमान लगाने वाले ज़्यादातर एआई सिस्टम, खुद से ट्रेन किए गए मॉडल पर काम करते हैं. ऐसा इसलिए है, क्योंकि अनुमान लगाने वाले टास्क आपके प्रॉडक्ट और उपयोगकर्ताओं के हिसाब से तय किए जाते हैं. scikit-learn (Python), AutoML (नो-कोड या लो-कोड), या TensorFlow.js (JavaScript) जैसे टूल की मदद से, अनुमान लगाने वाले मॉडल को आसानी से ट्रेन किया जा सकता है और उनका आकलन किया जा सकता है. इसके लिए, आपको गणित के बारे में ज़्यादा जानकारी होने की ज़रूरत नहीं है.
उपयोगकर्ता के सदस्यता छोड़ने के उदाहरण में, हम साफ़ किए गए ट्रेनिंग सेट को सुपरवाइज़ किए गए वर्गीकरण एल्गोरिदम में डालते हैं. जैसे, लॉजिस्टिक रिग्रेशन या न्यूरल नेटवर्क. अपने डेटा के लिए सबसे सही विकल्प चुनने के लिए, कई विकल्पों को आज़माएं.
आपका मॉडल यह पता लगाता है कि ग्राहक के कारोबार से अलग होने के पैटर्न कौनसे हैं. आखिर में, यह हर उपयोगकर्ता को संभावना स्कोर असाइन कर सकता है. उदाहरण के लिए, इस बात की 72% संभावना है कि उपयोगकर्ता X अगले महीने सदस्यता रद्द कर देगा.
ट्रेनिंग के हर इटरेशन के बाद, पुष्टि करने वाले सेट का इस्तेमाल करके, नतीजे के तौर पर मिले मॉडल का आकलन करें. हाइपरपैरामीटर में बदलाव करके, मॉडल की परफ़ॉर्मेंस को बेहतर बनाया जा सकता है. हालांकि, अपने डेटासेट में ज़रूरी सुधार करके भी ऐसा किया जा सकता है.
मॉडल का आकलन करना
आपके डेटासेट में मौजूद लेबल, ग्राउंड ट्रूथ उपलब्ध कराते हैं. इनकी मदद से, मॉडल के आउटपुट की तुलना की जा सकती है. ट्रैक करने के लिए मुख्य मेट्रिक ये हैं:
- सटीकता: "छोड़ दिया" के तौर पर फ़्लैग किए गए सभी उपयोगकर्ताओं में से, कितने उपयोगकर्ताओं ने वाकई में सदस्यता छोड़ दी?
- रिकॉल: मॉडल ने, ऐप्लिकेशन या वेबसाइट का इस्तेमाल बंद करने वाले सभी उपयोगकर्ताओं में से कितने उपयोगकर्ताओं का पता लगाया?
- F1 स्कोर: यह एक ऐसा नंबर होता है जो सटीक और रीकॉल किए गए डेटा के बीच संतुलन बनाए रखता है. यह तब काम आता है, जब आपको एक को दूसरे की कीमत पर ज़्यादा ऑप्टिमाइज़ किए बिना, सटीकता का कुल मेज़रमेंट चाहिए.
बहुत ज़्यादा फ़ॉल्स पॉज़िटिव की वजह से, ग्राहकों को बनाए रखने की कोशिशें बेकार हो जाती हैं. वहीं, बहुत ज़्यादा फ़ॉल्स नेगेटिव की वजह से, ग्राहक कम हो जाते हैं. सही ट्रेड-ऑफ़, आपके कारोबार की प्राथमिकताओं पर निर्भर करता है. उदाहरण के लिए, अगर आपकी कंपनी को लगता है कि कुछ गलत अलार्म मिलने से, उपयोगकर्ताओं के जाने से पहले उन्हें पकड़ने की संभावना बढ़ जाती है, तो वह कुछ गलत अलार्म मिलने पर भी कार्रवाई नहीं करेगी.
मॉडल को डिप्लॉय और बनाए रखना
पुष्टि हो जाने के बाद, मॉडल को एपीआई या क्लाइंट-साइड की हल्की-फुल्की सेवा के तौर पर डिप्लॉय किया जा सकता है. इसे अपने आंकड़ों के डैशबोर्ड में इंटिग्रेट करें. यह हर दिन उपयोगकर्ताओं को स्कोर कर सकता है. साथ ही, चर्न के जोखिम को दिखाने वाले विज़ुअलाइज़ेशन को अपडेट कर सकता है. इससे आपकी टीम को, उपयोगकर्ताओं तक पहुंचने के लिए प्राथमिकता तय करने में मदद मिलती है. इसे सटीक और भरोसेमंद बनाए रखने के लिए, मशीन लर्निंग ऑपरेशन (एमएलऑप्स) टीमों से ये सबक लें:
- डेटा ड्रिफ्ट पर नज़र रखना: इससे यह पता चलता है कि उपयोगकर्ता के व्यवहार में कब बदलाव हुआ और आपका ट्रेनिंग डेटा अब असलियत को नहीं दिखाता.
- उदाहरण के लिए, यूज़र इंटरफ़ेस (यूआई) को फिर से डिज़ाइन करने के बाद, उपयोगकर्ता सुविधाओं के साथ अलग-अलग तरीके से इंटरैक्ट करते हैं. इससे, चर्न के अनुमान कम सटीक हो जाते हैं.
- गलतियों से सीखें: अनुमान के गलत होने की वजहों का पता लगाएं. साथ ही, अगले ट्रेनिंग साइकल को बेहतर बनाने के लिए, टारगेट किए गए उदाहरण जोड़ें.
- उदाहरण के लिए, मॉडल अक्सर पावर यूज़र को चर्न आउट के जोखिम के तौर पर फ़्लैग करता है, क्योंकि वे कई सहायता टिकट खोलते हैं. समीक्षा के बाद, ऐसी नई सुविधाएं जोड़ी जाती हैं जिनसे समस्या हल करने और उपयोगकर्ता के दिलचस्पी न दिखाने के बीच अंतर किया जा सकता है.
- मॉडल को नियमित तौर पर फिर से ट्रेन करें: अगर परफ़ॉर्मेंस स्थिर दिखती है, तब भी मॉडल को समय-समय पर रीफ़्रेश करें. इससे सीज़न के पैटर्न, प्रॉडक्ट अपडेट या कीमत में होने वाले बदलावों को ध्यान में रखा जा सकेगा.
- उदाहरण के लिए, सालाना प्लान लॉन्च करने के बाद मॉडल को फिर से ट्रेन किया जाता है. ऐसा इसलिए, क्योंकि कीमत के स्ट्रक्चर में बदलाव होने से, रिन्यूअल से पहले उपयोगकर्ताओं के व्यवहार में बदलाव होता है.
यह लाइफ़साइकल, अनुमान लगाने वाले एआई का मुख्य आधार है. MLflow और Weights & Biases जैसे टूल की मदद से, इस प्रोसेस को बिना एमएल की गहरी जानकारी के भी चलाया जा सकता है.
आम तौर पर होने वाली समस्याएं और उन्हें ठीक करने के तरीके
कभी-कभी गड़बड़ियां हो सकती हैं. हालांकि, परफ़ॉर्मेंस और उपयोगकर्ता के भरोसे को कम करने वाली सामान्य वजहों से बचा जा सकता है:
- खराब क्वालिटी का डेटा: अगर आपका इनपुट डेटा सही नहीं है या अधूरा है, तो आपको मिलने वाले अनुमान भी सही नहीं होंगे. डेटा को बेहतर बनाने के लिए, ट्रेनिंग से पहले अपने डेटा को विज़ुअलाइज़ करें और उसकी पुष्टि करें. पक्का करें कि आपके पास ज़रूरी लर्निंग सिग्नल हों और आपने छूटी हुई वैल्यू को मैनेज किया हो. प्रोडक्शन में डेटा क्वालिटी पर नज़र रखें.
ओवरफ़िटिंग: मॉडल, ट्रेनिंग डेटा पर बहुत अच्छा परफ़ॉर्म करता है, लेकिन नए मामलों में फ़ेल हो जाता है. इससे बचने के लिए, क्रॉस-वैलिडेशन, रेगुलराइज़ेशन, और होल्डआउट डेटा सेट का इस्तेमाल करें. इससे आपका मॉडल, ट्रेनिंग के उदाहरणों के अलावा अन्य उदाहरणों के लिए भी सामान्यीकरण कर पाता है.
डेटा में बदलाव: उपयोगकर्ता के व्यवहार और एनवायरमेंट में बदलाव होता है, लेकिन आपके मॉडल में नहीं. इस समस्या को कम करने के लिए, मॉडल को फिर से ट्रेन करने का शेड्यूल करें. साथ ही, मॉडल की परफ़ॉर्मेंस पर नज़र रखने की सुविधा चालू करें, ताकि यह पता चल सके कि मॉडल की परफ़ॉर्मेंस कब से खराब हो रही है.
खराब मेट्रिक: कुल सटीकता से हमेशा यह पता नहीं चलता कि आपके उपयोगकर्ताओं की प्राथमिकताएं क्या हैं. उदाहरण के लिए, कभी-कभी किसी खास गलती की "लागत" ज़्यादा मायने रखती है. धोखाधड़ी का पता लगाने के लिए, किसी धोखाधड़ी वाले मामले की पहचान न कर पाना (फ़ॉल्स नेगेटिव), किसी निर्दोष मामले को फ़्लैग करने (फ़ॉल्स पॉज़िटिव) से ज़्यादा खराब होता है. इस समस्या को कम करने के लिए, धोखाधड़ी का पता लगाने से जुड़े असल लक्ष्यों के साथ मेट्रिक को अलाइन करें.
इनमें से ज़्यादातर समस्याएं गंभीर नहीं होती हैं. अपने सिस्टम को धीरे-धीरे लॉन्च करें और समस्याओं को ठीक करें.
इस आसान और लचीले तरीके की सबसे अहम बात है कि इससे सिस्टम की परफ़ॉर्मेंस को मॉनिटर किया जा सकता है. अपने मॉडल का वर्शन बनाएं. साथ ही, मॉडल बनाने के लिए इस्तेमाल किए गए टूल और सटीक होने की विशेषताओं को लॉग करें. समय के साथ परफ़ॉर्मेंस को ट्रैक करें और निगरानी जारी रखें. जब कोई गड़बड़ी होती है, तो उपयोगकर्ताओं को पता चलने से पहले ही आपको इसकी जानकारी मिल जाएगी. साथ ही, आपको इसे ठीक करने का मौका भी मिल जाएगा.
आपके लिए अहम जानकारी
अनुमान लगाने वाला एआई, आपके मौजूदा डेटा को आने वाले समय के बारे में जानकारी में बदल देता है. इससे यह पता चलता है कि आगे क्या होने वाला है और कहां कार्रवाई करनी है. यह एआई का सबसे सटीक और मेज़र किया जा सकने वाला रूप है. उन समस्याओं पर फ़ोकस करें जिनके बारे में डेटा से पता चलता है. अपने प्रॉडक्ट को बेहतर बनाने के लिए, लगातार प्रयोग करते रहें. साथ ही, समय के साथ परफ़ॉर्मेंस को मॉनिटर करें.
हमारे अगले मॉड्यूल में, आपको जनरेटिव एआई के बारे में जानकारी मिलेगी. यह उपलब्ध डेटा के आधार पर, नया कॉन्टेंट बनाने में आपकी मदद करता है.
संसाधन
अगर आपको अनुमान लगाने वाले एआई के पीछे की गणित को समझना है, तो हमारा सुझाव है कि आप इन संसाधनों को देखें:
- क्लासिफ़िकेशन, लीनियर रिग्रेशन, और लॉजिस्टिक रिग्रेशन के बारे में मशीन लर्निंग क्रैश कोर्स.
- इस कोर्स की लेखक, याना लिपेंकोवा ने एआई प्रॉडक्ट डेवलपमेंट की कला: कारोबार को वैल्यू देना के चौथे चैप्टर में, अनुमान लगाने वाले एआई के बारे में ज़्यादा जानकारी दी है.
- आर्टिफ़िशियल इंटेलिजेंस: ए मॉडर्न अप्रोच स्टुअर्ट जोनाथन रसेल और पीटर नॉरविग की किताब. इस किताब को पहली बार 1995 में पब्लिश किया गया था. इसका सबसे नया एडिशन 2021 में पब्लिश हुआ था. इसे आम तौर पर, एआई इंजीनियरिंग प्रोग्राम में सिखाया जाता है.
- पैटर्न रिकग्निशन ऐंड मशीन लर्निंग क्रिस्टोफ़र एम. बिशप की किताब, जिसमें अनुमान लगाने वाले एआई के बारे में काफ़ी जानकारी दी गई है.
देखें कि आपको कितना समझ आया
अनुमान लगाने वाले एआई का मुख्य काम क्या है?
पैटर्न के आधार पर, आइटम को पहले से तय की गई कैटगरी में ग्रुप करने का काम किस टास्क में शामिल है?
"अनुमान लगाने वाले एआई लूप" में, आपको अपने डेटासेट को ट्रेनिंग, पुष्टि, और टेस्ट सेट में क्यों बांटना चाहिए?
कौनसी मेट्रिक, प्रिसिज़न और रीकॉल को बैलेंस करती है, ताकि सटीकता का आकलन किया जा सके?
डेटा ड्रिफ्ट क्या है और इसे कैसे कम किया जा सकता है?