
Tus decisiones de diseño determinan directamente la responsabilidad y la seguridad de tu sistema de IA. Por ejemplo, decides cómo seleccionar las fuentes de datos, configurar el comportamiento del modelo o presentar los resultados de la IA a los usuarios. Estas elecciones tienen consecuencias en el mundo real para tus usuarios y tu empresa.
En este módulo, abordaremos tres dimensiones fundamentales de la gobernanza de la IA:
- Privacidad: Maneja los datos de forma responsable, explica qué se recopila y minimiza lo que sale del navegador.
- Imparcialidad: Verifica si tus modelos tienen un comportamiento discriminatorio (sesgo) y crea bucles que permitan a los usuarios marcar problemas.
- Confianza y transparencia: Diseña tu sistema para que sea transparente y genere confianza calibrada, de modo que los usuarios sigan beneficiándose de él a pesar de la incertidumbre y los posibles errores.
Para cada tema, explicamos cómo se manifiesta en diferentes productos basados en IA. Luego, lo desglosamos en las tres capas de tu solución de IA: datos, inteligencia y experiencia del usuario. Aprenderás qué debes tener en cuenta, cómo abordar los problemas y cómo mantener una administración eficaz y ligera.
Privacidad
Aprendiste que los datos reales de uso y de interacción son el núcleo de cualquier sistema de IA. Los datos impulsan el aprendizaje, la evaluación y la mejora continua. Las buenas prácticas de privacidad te permiten mantener esos datos seguros y, también, brindarles a los usuarios control sobre su información.
Las expectativas de privacidad varían mucho según el producto y el público. En los productos de consumo, las expectativas suelen incluir la protección de la información de identificación personal (PII) de las personas, como nombres, mensajes y comportamiento de navegación. En la configuración empresarial, el enfoque se centra en la soberanía, la confidencialidad y la protección de la propiedad intelectual de los datos.
Los sectores que afectan el bienestar o la calidad de vida de las personas, como la atención médica, las finanzas y la educación, exigen medidas de protección de la privacidad más estrictas que las áreas de menor riesgo, como el entretenimiento.
Veamos cómo se puede administrar la privacidad en los diferentes componentes de tu sistema de IA.
Datos
Para mejorar continuamente tu sistema de IA, puedes recopilar datos sobre las interacciones de los usuarios, incluidas las entradas, los resultados, los comentarios y los errores. Esta información se puede reutilizar para la evaluación, el ajuste del modelo o los ejemplos con pocos ejemplos en las instrucciones. También puede servir de base para tu diseño de UX.
Estos son algunos lineamientos para la recopilación responsable de datos:
- Recopila solo lo necesario para el aprendizaje. Es posible que una búsqueda de productos potenciada por IA no necesite el perfil completo de un usuario para mejorar los resultados. En la mayoría de los casos, es suficiente con proporcionar la búsqueda, los patrones de clics y los datos de sesión anonimizados.
- Elimina la información sensible. Quita toda la PII (información de identificación personal) antes de enviar datos a modelos externos. Puedes hacerlo con la anonimización, la seudonimización o la agregación.
- Limitar la retención Borra los registros y los datos almacenados en caché una vez que hayan cumplido su propósito. Los ciclos de retención cortos reducen el riesgo sin bloquear la información.
Documenta qué información recopilas, durante cuánto tiempo la conservas y por qué es necesaria. Si no puedes explicar claramente tus flujos de datos a un usuario no técnico, es probable que los flujos sean demasiado complejos para controlarlos o justificarlos.
Inteligencia
Cuando los usuarios interactúan con tu sistema de IA, es posible que ingresen información privada o sensible sin saberlo o por descuido. Este riesgo es especialmente alto en las interfaces de escritura o chat de respuesta abierta, en las que no puedes restringir lo que escriben los usuarios.
Si bien es posible que puedas evitar que se envíen ciertas palabras, esta información puede ser sensible según el contexto. Si tu modelo se ejecuta en un servidor administrado por un proveedor externo, es posible que este reutilice la entrada del usuario como datos de entrenamiento. Con el tiempo, el modelo podría revelar fragmentos de texto privado, credenciales o detalles confidenciales a otros usuarios.
Estas son algunas formas de protegerte contra las filtraciones de privacidad durante la inferencia:
Analiza las APIs de terceros con cuidado. Debes saber exactamente qué sucede con los datos que envías. ¿Se registran, conservan o reutilizan las entradas para el entrenamiento? Evita los servicios opacos y prefiere los proveedores con políticas y controles transparentes.
Si entrenas o ajustas modelos por tu cuenta, abstrae los detalles sensibles de tus datos de entrenamiento. Ten cuidado con el aprendizaje de atajos. Por ejemplo, en una aplicación de calificación crediticia, los códigos postales pueden llevar al modelo a hacer suposiciones sobre la raza o el nivel socioeconómico. Esto puede generar predicciones injustas y reforzar las desigualdades existentes.
En los dominios sensibles, se prefiere la inferencia del cliente. Esto puede hacerse con la IA integrada, un modelo en el navegador o un modelo personalizado del cliente. Obtendrás más información sobre esta elección en el próximo módulo, cómo elegir una plataforma.
Experiencia del usuario
La interfaz de tu aplicación te brinda la oportunidad de mostrarles a los usuarios lo que sucede, ganarte su confianza y darles control sobre sus datos:
- Sé transparente. Las etiquetas cortas en tu interfaz, como "Se procesó de forma local" o "Se envió de forma segura para su análisis", pueden ayudarte a generar confianza. Considera agregar una divulgación progresiva para obtener más detalles, como cuadros de información que expliquen cuándo se realiza el análisis en el dispositivo y cuándo en un servidor.
- Solicitar en contexto. Solicita el consentimiento cuando sea pertinente. "¿Quieres compartir tus búsquedas anteriores para mejorar las recomendaciones?" es mucho más significativa que una habilitación general.
- Ofrece controles simples. Agrega botones de activación claramente visibles para la personalización, las funciones basadas en la nube o el uso compartido de datos.
- Brinda visibilidad. Incluye un pequeño panel de privacidad para que los usuarios puedan administrar sus datos sin salir de la app.
- Explica por qué recopilas datos. Es posible que los usuarios estén más dispuestos a compartir datos si comprenden cómo se usarán. Lo mismo se aplica a tus políticas de administración y retención.
La privacidad en la IA web no es un solo paso de cumplimiento, sino una mentalidad de diseño continua:
- Datos: Recopila menos y protege más.
- Inteligencia: Mitiga la memorización de datos potencialmente sensibles por parte de modelos externos.
- UX: Haz que la privacidad sea transparente y controlable para los usuarios.
Equidad
Los sistemas de IA pueden tener sesgos que generen discriminación injusta. Esto es especialmente cierto en dominios como la contratación, el derecho y las finanzas, en los que el sesgo puede distorsionar decisiones críticas que afectan directamente a personas reales.
Por ejemplo, un modelo de contratación entrenado con datos históricos de reclutamiento podría asociar ciertas características demográficas con una menor calidad de los candidatos, lo que penalizaría involuntariamente a los solicitantes de grupos subrepresentados, en lugar de evaluar las habilidades y la experiencia relevantes para el trabajo.
Datos
Tus datos de entrenamiento son un conjunto de fragmentos de información aislados individualmente que pueden reflejar sesgos del mundo real e incluso introducir sesgos nuevos. Estos son los pasos prácticos para que el sesgo relacionado con los datos sea transparente y fácil de administrar:
- Documenta tus fuentes de datos y tu cobertura. Publica una declaración breve para ayudar a los usuarios a comprender las limitaciones del modelo. Por ejemplo, "Este modelo se entrenó principalmente con contenido en inglés, con una representación limitada de texto técnico".
- Ejecuta verificaciones de diagnóstico. Usa pruebas A/B para revelar diferencias sistemáticas. Por ejemplo, compara cómo tu sistema maneja "Ella es una gran líder", "Él es un gran líder" y "Ellos son grandes líderes". Las pequeñas discrepancias en el sentimiento o el tono pueden indicar un sesgo más profundo.
- Etiqueta tus conjuntos de datos. Agrega metadatos livianos, como el dominio, la región y el nivel de formalidad, para que las auditorías, los filtros y el reequilibrio futuros sean sencillos.
Si entrenas o ajustas modelos personalizados, equilibra tus conjuntos de datos. Una representación más amplia reduce el sesgo de manera más eficaz que corregir el sesgo después de que se compila el modelo.
Inteligencia
En la capa de inteligencia, el sesgo se convierte en comportamiento aprendido. Puedes agregar medidas de protección, lógica de reordenamiento o reglas híbridas para orientar los resultados hacia la equidad y la inclusión:
- Realiza pruebas de sesgo con regularidad. Usa filtros de detección de sesgos para marcar frases problemáticas, como detectar términos con sesgo de género o un tono excluyente. Supervisa la desviación con el tiempo.
- En el caso de los modelos predictivos, ten cuidado con los datos sensibles. Los atributos, como el código postal, la educación o los ingresos, pueden codificar de forma indirecta rasgos sensibles, como la raza o la clase.
- Genera y compara varios resultados. Clasifica los resultados según la neutralidad, la diversidad y el tono antes de determinar qué resultado compartir con el usuario.
- Agrega reglas para aplicar restricciones de equidad. Por ejemplo, bloquear los resultados que refuerzan estereotipos o no representan ejemplos diversos.
Experiencia del usuario
En tu interfaz de usuario, sé transparente sobre el razonamiento del modelo y fomenta los comentarios:
- Proporcionar explicaciones para los resultados de la IA Por ejemplo, "Se recomienda un tono profesional según tus entradas anteriores*." Esto ayuda a los usuarios a ver que el sistema sigue una lógica definida, no un juicio oculto.
- Bríndales a los usuarios un control significativo. Permitirles ajustar el comportamiento del modelo a través de la configuración o las instrucciones (por ejemplo, elegir el tono, la complejidad o las preferencias de estilo visual)
- Facilitar la denuncia de sesgos o imprecisiones Cuanto más fácil sea marcar un problema, más datos del mundo real obtendrás para mejorar tu sistema de IA.
- Cierra el ciclo de comentarios. No permitas que desaparezcan los informes de los usuarios. Vuelve a ingresar estos datos en la lógica de reentrenamiento o de reglas, y comparte el progreso de forma visible: "Actualizamos nuestra moderación para reducir el sesgo cultural en las recomendaciones".
El sesgo nace en los datos, se amplifica a través de los modelos y se manifiesta en la experiencia del usuario. Puedes abordar este problema en los tres niveles de tu sistema de IA:
- Datos: Haz que las fuentes de datos sean transparentes y equilibradas.
- Inteligencia: Detecta, prueba y mitiga los sesgos en los resultados.
- UX: Empoderar a los usuarios para que identifiquen y corrijan el sesgo a través del control y los comentarios
Confianza y transparencia
La confianza determina si las personas usan, adoptan y recomiendan tu producto.
La mayoría de los usuarios esperan aplicaciones predecibles. Por ejemplo, los clics en los botones siempre realizan la acción indicada y llevan al mismo lugar. La IA rompe esta expectativa, ya que su comportamiento es muy variable y, a menudo, impredecible. Además, los sistemas de IA tienen un potencial inherente de falla: los modelos de lenguaje alucinan hechos, los modelos predictivos etiquetan mal los datos y los agentes se descontrolan.
Tus usuarios son la última línea de defensa contra estos errores.
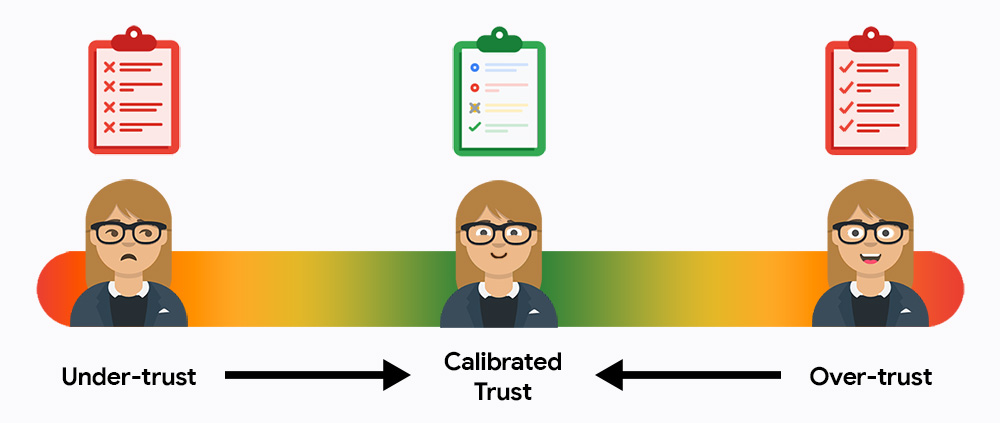
Al principio, es probable que los usuarios confíen demasiado o demasiado poco en tu sistema. La confianza insuficiente significa que no usarán el sistema, y la confianza excesiva significa que aceptarán los resultados por completo, sin verificar si hay errores. Tu tarea es atraer a los usuarios al punto medio ideal de la confianza calibrada, en el que confían en la IA para lograr eficiencia y, al mismo tiempo, se responsabilizan de los resultados finales.
Datos
En la capa de datos, la confianza se genera explicando claramente la cobertura y la procedencia de tus datos:
- Sé explícito sobre el origen y el linaje de los datos.
- Documenta la actualidad y la inactividad de los datos.
- Describe qué tipos de contenido ha visto el modelo y dónde puede tener dificultades, como los datos en idiomas distintos del inglés.
A medida que tu sistema de IA acumule interacciones y comentarios con el tiempo, considera mantener instantáneas versionadas de los datos para poder explicar cómo evolucionaron los resultados.
Inteligencia
En la capa de inteligencia, puedes administrar la confianza a través de la explicabilidad, los indicadores de confianza y el diseño modular:
- Proporcionar explicaciones contextuales y oportunas Según la paradoja del usuario activo, es mejor incorporar microexplicaciones en contexto, directamente en las interacciones, para que los usuarios comprendan lo que hace el sistema de IA mientras lo usan.
- Comunica las limitaciones y los modos de falla por adelantado. Indicar a los usuarios dónde podría tener dificultades la IA Por ejemplo, "Evita el humor o la jerga del dominio para obtener mejores resultados". Las pistas contextuales breves brindan transparencia sin interrumpir el flujo.
- Los indicadores de confianza y la lógica de resguardo mantienen la confiabilidad de la IA en situaciones de incertidumbre. Puedes estimar la confianza a partir de indicadores, como las puntuaciones de probabilidad o los porcentajes de éxito anteriores. Define alternativas seguras para los resultados que son claramente incorrectos.
- Las arquitecturas modulares hacen que la IA sea más transparente. Por ejemplo, si un asistente de escritura maneja la gramática, el estilo y el tono en pasos separados, indica qué cambió en cada etapa: "Tono: menos formal; complejidad: simplificada".
Experiencia del usuario
La experiencia del usuario te brinda un amplio campo de juego para generar y calibrar la confianza. Estas son algunas técnicas y patrones que puedes probar:
- Adapta el contenido educativo. No supongas que tus usuarios saben usar la IA. Proporciona orientación sencilla para usuarios avanzados y explicaciones detalladas para principiantes.
- Aplica la divulgación progresiva. Comienza con pistas pequeñas. Incluye texto que indique que usaste IA, como "Se generó automáticamente", y permite que los usuarios hagan clic para obtener más información.
- Cierra los circuitos de retroalimentación con resultados visibles. Cuando los usuarios califican, corrigen o anulan una sugerencia de IA, comparte cómo su entrada da forma al comportamiento futuro: "Preferiste respuestas concisas. Se ajustó el tono según corresponda". La visibilidad convierte los comentarios en confianza.
- Aborda los errores con facilidad. Cuando tu sistema cometa un error o proporcione un resultado con un nivel de confianza bajo, reconócelo y delega una revisión al usuario. Por ejemplo, "Es posible que esta sugerencia no coincida con tu intención. Revisa antes de publicar". Proporciona un camino claro para avanzar, ya que permite que el usuario vuelva a intentarlo, edite o revierta a una alternativa segura.
En resumen, para abordar la incertidumbre y el potencial de error inherente de la IA, guía a los usuarios desde la duda o la dependencia excesiva hasta la calibración adecuada de la confianza:
- Datos: Sé transparente sobre la procedencia de los datos.
- Inteligencia: Haz que el razonamiento sea modular y explicable.
- UX: Diseña para ofrecer claridad y comentarios progresivos.
Tus conclusiones
En este módulo, exploramos tres pilares fundamentales de la IA responsable: la privacidad, la equidad y la confianza. Esto puede ser abrumador, sobre todo cuando recién comienzas o intentas dar el salto del prototipo a la producción.
Enfoca tus esfuerzos en las áreas más críticas y define tu propio enfoque para la gobernanza de la IA. La iteración es clave. Cada lanzamiento y ronda de comentarios de los usuarios mejorará tu comprensión de dónde tu sistema necesita más protecciones, transparencia o flexibilidad.
Recursos
Estos son algunos recursos más avanzados sobre los temas que se abordan en este módulo:
- En AI Assistant Privacy and Security Comparison, se proporciona un análisis detallado de las políticas de privacidad de la IA.
- Un documento sobre la memorización de LLM, un modo de falla de privacidad crítico en el que un modelo retiene información específica y sensible de sus datos de entrenamiento, y se le puede solicitar que la reproduzca.
- Revisa los recursos asociados directamente con el modelo que elijas. Por ejemplo, Google Cloud proporciona recursos de seguridad.
- El kit de herramientas de IA responsable ofrece recursos para desarrolladores sobre todos los temas que abordamos en este módulo.
Recursos
Estos son algunos recursos más avanzados sobre los temas que se abordan en este módulo:
- Comparación de la privacidad y la seguridad de AI Assistant: Proporciona un análisis detallado de las políticas de privacidad de la IA.
- Un documento sobre la memorización de LLM, un modo de falla de privacidad crítico en el que un modelo retiene y se le puede solicitar que reproduzca información específica y sensible de sus datos de entrenamiento.
- Revisa los recursos asociados directamente con el modelo que elijas. Por ejemplo, Google Cloud proporciona recursos de seguridad.
- El kit de herramientas de IA responsable ofrece recursos para desarrolladores sobre todos los temas que abordamos en este módulo.
Verifica tus conocimientos
¿Cuál es una práctica de privacidad recomendada en relación con la recopilación de datos para la IA?
¿Qué es la confianza calibrada?
Para garantizar la equidad en la capa de "Inteligencia", ¿qué acción pueden tomar los desarrolladores?
¿Qué técnica de UX se puede usar para generar confianza y transparencia?