
設計上の決定は、AI システムの責任と安全性を直接的に左右します。たとえば、データソースの選択方法、モデルの動作の構成方法、AI の出力をユーザーに提示する方法などを決定します。これらの選択は、ユーザーと会社に現実世界での影響を及ぼします。
このモジュールでは、AI ガバナンスの 3 つの重要な側面について説明します。
- プライバシー: データを責任を持って処理し、収集される内容を説明し、ブラウザから送信される内容を最小限に抑えます。
- 公平性: モデルに差別的な動作(バイアス)がないか確認し、ユーザーが問題を報告できるループを構築します。
- 信頼と透明性: 透明性と調整された信頼性を実現するようにシステムを設計します。これにより、不確実性や潜在的な間違いがあっても、ユーザーはシステムから引き続きメリットを得ることができます。
各トピックについて、さまざまな AI プロダクトでどのように現れるかを説明します。次に、AI ソリューションの 3 つのレイヤ(データ、インテリジェンス、ユーザー エクスペリエンス)に分けて説明します。監視対象、問題への対処方法、効果的で軽量なガバナンスの維持方法について説明します。
プライバシー
実際の使用状況とインタラクションのデータは、あらゆる AI システムの中核であることがわかりました。データは、学習、評価、継続的な改善を推進します。適切なプライバシー対策を講じることで、データを安全に保ちながら、ユーザーが自分の情報を管理できるようにすることができます。
プライバシーに対する期待は、プロダクトやオーディエンスによって大きく異なります。一般消費者向け製品の場合、名前、メッセージ、閲覧履歴などの個人情報(PII)の保護が期待される傾向があります。エンタープライズ環境では、データ主権、機密性、知的財産の保護に重点が置かれます。
医療、金融、教育など、人々の生活や健康に影響を与える分野では、エンターテイメントなどリスクの低い分野よりも厳格なプライバシー保護が求められます。
AI システムのさまざまなコンポーネントでプライバシーを管理する方法を見てみましょう。
データ
AI システムを継続的に改善するには、入力、出力、フィードバック、エラーなど、ユーザー インタラクションに関するデータを収集します。この情報は、プロンプトの評価、モデルのファインチューニング、少数ショットの例に再利用できます。また、UX デザインにも役立ちます。
責任あるデータ収集のためのガイドラインは次のとおりです。
- 学習に必要なデータのみを収集する。AI を活用した商品検索では、検索結果を改善するためにユーザーの完全なプロフィールが必要になることはありません。ほとんどの場合、クエリ、クリック パターン、匿名化されたセッションデータを提供すれば十分です。
- 機密情報を削除します。外部モデルにデータを送信する前に、すべての PII(個人を特定できる情報)を削除します。匿名化、仮名化、集計を行うことで、これを行うことができます。
- 保持を制限する。ログとキャッシュされたデータは、目的を果たしたら削除します。保持期間を短くすることで、分析を妨げることなくリスクを軽減できます。
収集する情報、保持期間、その情報が必要な理由を文書化します。データフローを技術者以外のユーザーに明確に説明できない場合、そのフローは制御または正当化するには複雑すぎる可能性があります。
インテリジェンス
ユーザーが AI システムを操作する際に、プライベートな情報や機密情報を無意識のうちに、または不注意で入力してしまう可能性があります。このリスクは、ユーザーが入力する内容を制限できないオープンエンドのチャット インターフェースや書き込みインターフェースで特に高くなります。
特定の単語の送信をブロックすることはできますが、この情報はコンテキストに依存する可能性があります。モデルが外部プロバイダによって管理されるサーバーで実行されている場合、ユーザー入力がトレーニング データとして再利用される可能性があります。最終的に、モデルはプライベート テキスト、認証情報、その他の機密情報の断片を他のユーザーに公開する可能性があります。
推論中にプライバシー侵害を防ぐ方法は次のとおりです。
サードパーティ API を慎重に審査します。送信したデータがどうなるかを正確に把握する必要があります。入力はログに記録、保持、またはトレーニングに再利用されますか?不透明なサービスは避け、透明性の高いポリシーと制御を備えたプロバイダを選択します。
モデルを自分でトレーニングまたはファインチューニングする場合は、トレーニング データ内の機密情報を抽象化します。安易な学習に注意してください。たとえば、クレジット スコア アプリケーションでは、郵便番号によってモデルが人種や社会経済的ステータスについて仮定を行う可能性があります。これにより、不公平な予測が生じ、既存の不平等が強化される可能性があります。
機密性の高いドメインでは、クライアントサイド推論を優先します。これは、組み込みの AI、ブラウザ内のモデル、カスタムのクライアントサイド モデルで行うことができます。この選択肢については、次のモジュール プラットフォームの選択で詳しく説明します。
ユーザー エクスペリエンス
アプリケーション インターフェースは、ユーザーに何が起こっているかを示し、信頼を得て、ユーザーがデータを制御できるようにする機会を提供します。
- 透明性を保つ。「ローカルで処理済み」や「分析のために安全に送信済み」などの短いラベルをインターフェースに表示することで、ユーザーの信頼を得ることができます。オンデバイスとサーバーのどちらで分析が行われるかについて説明するツールチップなど、詳細情報を段階的に開示することを検討してください。
- コンテキスト内でリクエスト。同意が必要な場合は、同意を求めます。「おすすめ情報の精度を高めるために、過去の検索履歴を共有しますか?」というメッセージは、包括的なオプトインよりもはるかに意味があります。
- シンプルなコントロールを提供する。パーソナライズ、クラウドベースの機能、データ共有のオン / オフを切り替えるトグルをわかりやすく表示します。
- 可視性を付与。プライバシー ダッシュボードを組み込み、ユーザーがアプリを離れることなくデータを管理できるようにします。
- データを収集する理由を説明します。ユーザーは、データの使用方法を理解していれば、データを共有することに抵抗を感じない可能性があります。保持ポリシーと管理ポリシーについても同様です。
ウェブ AI におけるプライバシーは、単なるコンプライアンスのステップではなく、継続的な設計の考え方です。
- データ: 収集するデータを減らし、保護を強化します。
- インテリジェンス: 外部モデルによる機密データの記憶を軽減します。
- UX: ユーザーがプライバシーを透明かつ制御可能にできるようにします。
公平性
AI システムには、不公平な差別につながるバイアスが含まれている可能性があります。この傾向は、採用、法律、金融など、バイアスが実際のユーザーに直接影響する重要な意思決定を歪める可能性がある分野で特に顕著です。
たとえば、過去の採用データでトレーニングされた採用モデルは、特定の人口統計学的特徴を候補者の質の低さと関連付け、仕事に関連するスキルや経験を評価するのではなく、過小評価されているグループの応募者を意図せずにペナルティに処す可能性があります。
データ
トレーニング データは、現実世界のバイアスを反映し、新しいバイアスを導入することさえある、個別に分離された情報のセットです。データ関連のバイアスを透明化して管理可能にするための具体的な手順は次のとおりです。
- データソースとカバレッジを文書化します。モデルの欠点についてユーザーが理解できるよう、短いステートメントを公開します。たとえば、「このモデルは主に英語のコンテンツでトレーニングされており、技術的なテキストの表現は限られています。」
- 診断チェックを実行します。A/B テストを実施して、体系的な違いを明らかにします。たとえば、「彼女は素晴らしいリーダーです」、「彼は素晴らしいリーダーです」、「彼らは素晴らしいリーダーです」という文をシステムがどのように処理するかを比較します。感情やトーンのわずかな違いは、より深いバイアスを示している可能性があります。
- データセットにラベルを付ける。ドメイン、リージョン、形式レベルなどの軽量メタデータを追加して、今後の監査、フィルタリング、再調整を容易にします。
カスタムモデルをトレーニングまたはファイン チューニングする場合は、データセットのバランスを取ります。モデルの構築後にバイアスを修正するよりも、より広範な表現の方がスキューを効果的に軽減できます。
インテリジェンス
インテリジェンス レイヤでは、バイアスは学習された動作に変換されます。公平性と包括性を重視した出力を得るために、セーフガード、再ランキング ロジック、ハイブリッド ルールを追加できます。
- バイアスを定期的にテストする。バイアス検出フィルタを使用して、性別に関する用語や排他的なトーンなど、問題のある表現にフラグを設定します。時間の経過に伴うドリフトをモニタリングします。
- 予測モデルでは、機密データに注意してください。郵便番号、学歴、収入などの属性は、人種や階級などの機密性の高い特性を間接的にエンコードする可能性があります。
- 複数の出力を生成して比較する。中立性、多様性、トーンに基づいて結果をランク付けしてから、ユーザーと共有する出力を決定します。
- 公平性制約を適用するルールを追加します。たとえば、ステレオタイプを強化する出力や、多様な例を表現できない出力をブロックします。
ユーザー エクスペリエンス
ユーザー インターフェースで、モデルの推論について透明性を確保し、フィードバックを促します。
- AI 出力の根拠を提供する。たとえば、「以前の入力内容に基づいて、プロフェッショナルなトーンをおすすめします*」などです。これにより、ユーザーはシステムが隠れた判断ではなく、定義されたロジックに従っていることを確認できます。
- ユーザーが意味のある制御を行えるようにする。設定やプロンプトを通じてモデルの動作を調整できるようにします(たとえば、トーン、複雑さ、ビジュアル スタイルの設定を選択できるようにします)。
- バイアスや不正確さを報告しやすくします。問題を簡単に報告できるようにすれば、AI システムの改善に役立つ実際のデータをより多く取得できます。
- フィードバック ループを閉じます。ユーザー レポートが消えないようにします。このデータを再トレーニングまたはルールロジックにフィードバックし、進捗状況を明確に共有します。「おすすめの文化的な偏りを減らすために、モデレーションを更新しました。」
バイアスはデータから生まれ、モデルを通じて増幅され、ユーザー エクスペリエンスに現れます。この問題は、AI システムの 3 つのレベルすべてで対処できます。
- データ: データソースを透明でバランスの取れたものにします。
- インテリジェンス: 出力のバイアスを検出、テスト、軽減します。
- UX: ユーザーが制御とフィードバックを通じてバイアスを特定して修正できるようにします。
信頼と透明性
信頼は、ユーザーがプロダクトを使用、導入、推奨するかどうかを左右します。
ほとんどのユーザーは、予測可能なアプリケーションを期待しています。たとえば、ボタンをクリックすると、常に示されたアクションが実行され、同じ場所に移動します。AI はこの期待を裏切ります。AI の動作は非常に変動しやすく、予測できないことが多いためです。また、AI システムには、言語モデルが事実を誤認する、予測モデルがデータを誤ってラベル付けする、エージェントが不正行為を行うなど、本質的に失敗する可能性があります。
これらのエラーに対する最後の防衛線はユーザーです。
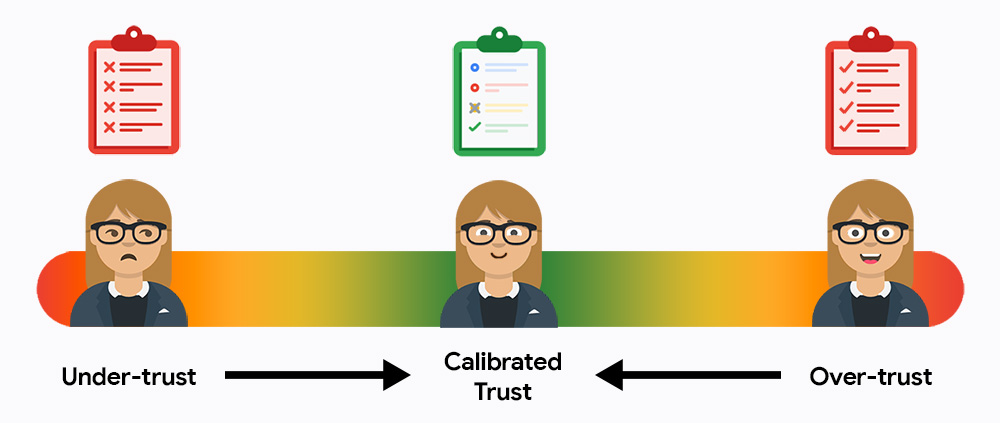
最初は、ユーザーはシステムを過小評価または過大評価する可能性があります。信頼度が低いとシステムを使用せず、信頼度が高いとエラーを確認せずに結果を完全に受け入れます。ユーザーを調整された信頼の中央値に引き込むことがタスクです。ユーザーは効率性を求めて AI を利用しながらも、最終結果に対する責任を負うことになります。
データ
データレイヤでは、データのカバレッジと出所を明確に説明することで信頼を構築します。
- データの出所とリネージを明示する。
- データの鮮度と未更新を文書化します。
- モデルが認識したコンテンツの種類と、モデルが苦手とする可能性のあるコンテンツ(英語以外の言語のデータなど)について説明します。
AI システムでインタラクションとフィードバックが蓄積されたら、データのバージョン管理されたスナップショットを維持して、出力がどのように進化したかを説明できるようにすることを検討してください。
インテリジェンス
インテリジェンス レイヤでは、説明可能性、信頼度指標、モジュラー設計を通じて信頼を管理できます。
- 状況に応じたタイムリーな説明を提供する。アクティブ ユーザーのパラドックスによると、マイクロ説明をコンテキスト内に直接埋め込む方が、ユーザーが AI システムを使用しながらその動作を理解できるため、効果的です。
- 制限事項と障害モードを事前に伝える。AI がつまずく可能性のある場所をユーザーに伝えます。たとえば、「ユーモアや専門用語は避けて、より良い結果を得てください。」短いコンテキスト キューは、フローを中断することなく透明性を提供します。
- 信頼度指標とフォールバック ロジックにより、不確実な状況でも AI の信頼性を維持できます。信頼度は、確率スコアや過去の成功率などのプロキシから推定できます。明らかに正しくない出力に対して安全なフォールバックを定義します。
- モジュール型アーキテクチャにより、AI の透明性が高まります。たとえば、文章作成アシスタントが文法、スタイル、トーンを別々のステップで処理する場合は、各段階で何が変更されたかを示します(「トーン: フォーマルではなくなった。複雑さ: 簡略化された」など)。
ユーザー エクスペリエンス
ユーザー エクスペリエンスは、信頼を構築し、調整するための広大なプレイグラウンドを提供します。試してみるべき手法とパターンを次に示します。
- 教育コンテンツを調整する。ユーザーが AI に精通しているとは限りません。パワーユーザー向けには簡潔なガイダンスを、初心者向けには詳細な説明を提供します。
- 段階的な開示を適用する。小さなキューから始めます。「これは自動的に生成されました」など、AI を使用したことを示すコピーを含め、ユーザーがクリックして詳細な分析情報を確認できるようにします。
- 結果を可視化してフィードバック ループを閉じます。ユーザーが AI の候補を評価、修正、オーバーライドした場合は、ユーザーの入力が今後の動作にどのように影響するかを伝えます。「簡潔な回答を希望されました。それに合わせてトーンを調整しました。」可視性はフィードバックを信頼に変えます。
- エラーを適切に処理する。システムが誤った結果を出力した場合や、信頼度の低い結果を出力した場合は、それを認め、ユーザーにレビューを委任します。たとえば、「この候補は意図と一致しない可能性があります。公開前に確認してください。」 ユーザーが再試行、編集、安全なフォールバックへの復元を行えるようにして、明確な解決策を提供します。
つまり、AI の不確実性と固有のエラーの可能性に対処するには、ユーザーが疑念や過度の依存から適切な信頼の調整へと移行できるようにします。
- データ: データの出所を明確にします。
- インテリジェンス: 推論をモジュール化して説明可能にします。
- UX: 段階的な明瞭さとフィードバックを考慮した設計。
要点
このモジュールでは、責任ある AI の 3 つの柱であるプライバシー、公平性、信頼性について説明しました。特に、始めたばかりの場合や、プロトタイプから本番環境への移行を試みている場合は、圧倒されるかもしれません。
最も重要な領域に重点を置き、AI ガバナンスに対する独自のアプローチを定義します。反復が鍵となります。リリースとユーザー フィードバックのラウンドを重ねるごとに、システムでガードレール、透明性、柔軟性を高める必要がある部分をより深く理解できるようになります。
リソース
このモジュールで取り上げたトピックに関するより高度なリソースは次のとおりです。
- AI アシスタントのプライバシーとセキュリティの比較では、AI のプライバシー ポリシーについて詳しく説明しています。
- LLM の記憶に関する論文。これは、モデルがトレーニング データから特定の機密情報を保持し、プロンプトで再現できるという、プライバシーに関する重大な障害モードです。
- 選択したモデルに直接関連付けられているリソースを確認します。たとえば、Google Cloud はセキュリティ リソースを提供します。
- 責任ある AI ツールキットには、このモジュールで取り上げたすべてのトピックに関するデベロッパー向けリソースが用意されています。
リソース
このモジュールで取り上げたトピックに関するより高度なリソースは次のとおりです。
- AI アシスタントのプライバシーとセキュリティの比較では、AI のプライバシー ポリシーについて詳しく説明しています。
- LLM の記憶に関する論文。これは、モデルがトレーニング データから特定の機密情報を保持し、その情報を再現するように促すことができるという、プライバシーに関する重大な障害モードです。
- 選択したモデルに直接関連付けられているリソースを確認します。たとえば、Google Cloud はセキュリティ リソースを提供します。
- 責任ある AI ツールキットには、このモジュールで取り上げたすべてのトピックに関するデベロッパー リソースが用意されています。
理解度を確認する
AI のデータ収集に関する推奨されるプライバシー対策は何ですか?
調整された信頼とは
「インテリジェンス」レイヤの公平性を確保するために、デベロッパーはどのような対策を講じることができますか?
信頼と透明性を高めるための UX 手法とは何ですか?