
W ostatnim module przedstawiliśmy omówienie web workerów. Web workerzy mogą poprawić szybkość reakcji na dane wejściowe, przenosząc kod JavaScript z głównego wątku do osobnych wątków web workerów. Może to pomóc w poprawie interaktywności do następnego wyrenderowania (INP) witryny, gdy masz do wykonania zadania, które nie wymagają bezpośredniego dostępu do głównego wątku. Sam przegląd nie wystarczy, dlatego w tym module przedstawiamy konkretny przypadek użycia Web Workera.
Jednym z takich przypadków użycia może być witryna, która musi usunąć metadane EXIF z obrazu – to nie jest tak odległa koncepcja. Witryny takie jak Flickr umożliwiają użytkownikom wyświetlanie metadanych Exif, aby poznać szczegóły techniczne dotyczące hostowanych przez nie obrazów, takie jak głębia kolorów, marka i model aparatu oraz inne dane.
Logika pobierania obrazu, przekształcania go w ArrayBuffer i wyodrębniania metadanych Exif może być jednak kosztowna, jeśli jest wykonywana w całości w głównym wątku. Na szczęście zakres instancji roboczej umożliwia wykonanie tej pracy poza głównym wątkiem. Następnie za pomocą potoku przesyłania wiadomości web workera metadane EXIF są przesyłane z powrotem do głównego wątku jako ciąg znaków HTML i wyświetlane użytkownikowi.
Jak wygląda wątek główny bez instancji roboczej
Najpierw zobaczmy, jak wygląda wątek główny, gdy wykonujemy tę pracę bez web workera. Aby to zrobić, wykonaj te czynności:
- Otwórz nową kartę w Chrome i otwórz Narzędzia deweloperskie.
- Otwórz panel wydajności.
- Otwórz stronę https://chrome.dev/learn-performance-exif-worker/without-worker.html.
- W panelu wydajności kliknij Nagrywaj w prawym górnym rogu okienka Narzędzi deweloperskich.
- Wklej w polu ten link do obrazu lub inny wybrany przez siebie link do obrazu zawierającego metadane Exif i kliknij przycisk Pobierz ten plik JPEG.
- Gdy interfejs zostanie wypełniony metadanymi Exif, ponownie kliknij Nagrywaj, aby zatrzymać nagrywanie.
{kind=link}
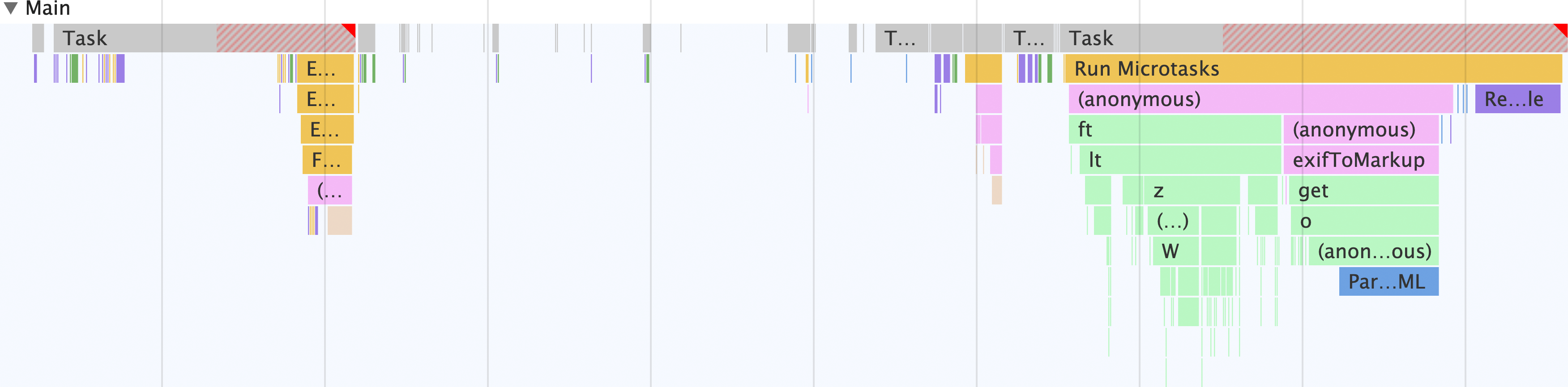
Pamiętaj, że oprócz innych wątków, które mogą być obecne, np. wątków rasteryzatora itp., wszystko w aplikacji odbywa się w wątku głównym. W głównym wątku wykonane zostaną te działania:
- Formularz przyjmuje dane wejściowe i wysyła żądanie
fetch, aby pobrać początkową część obrazu zawierającą metadane EXIF. - Dane obrazu są przekształcane w
ArrayBuffer. - Skrypt
exif-readersłuży do wyodrębniania metadanych Exif z obrazu. - Metadane są pobierane w celu utworzenia ciągu HTML, który następnie wypełnia przeglądarkę metadanych.
Porównaj to teraz z implementacją tego samego działania, ale z użyciem web workera.
Jak wygląda wątek główny z instancją roboczą
Teraz, gdy wiesz już, jak wygląda wyodrębnianie metadanych Exif z pliku JPEG w głównym wątku, zobacz, jak to wygląda, gdy w grę wchodzi worker internetowy:
- Otwórz inną kartę w Chrome i otwórz na niej Narzędzia deweloperskie.
- Otwórz panel wydajności.
- Otwórz stronę https://chrome.dev/learn-performance-exif-worker/with-worker.html.
- W panelu wydajności kliknij przycisk nagrywania w prawym górnym rogu okienka Narzędzi deweloperskich.
- Wklej ten link do obrazu w polu i kliknij przycisk Pobierz ten plik JPEG!.
- Gdy interfejs zostanie wypełniony metadanymi Exif, kliknij ponownie przycisk nagrywania, aby zatrzymać nagrywanie.
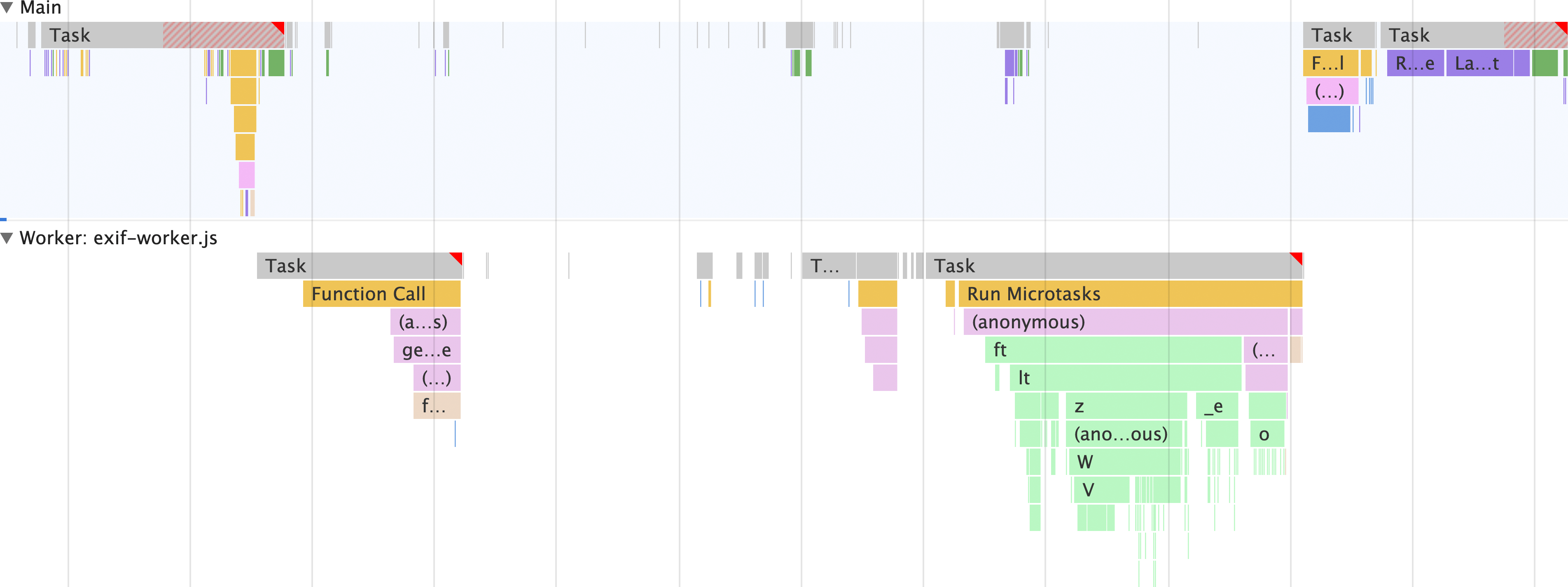
Na tym polega moc web workera. Zamiast wykonywać wszystko w głównym wątku, wszystko oprócz wypełniania przeglądarki metadanych kodem HTML jest wykonywane w osobnym wątku. Oznacza to, że wątek główny może wykonywać inne zadania.
Największą zaletą jest to, że w przeciwieństwie do wersji tej aplikacji, która nie korzysta z procesu roboczego, skrypt exif-reader nie jest ładowany w głównym wątku, ale w wątku procesu roboczego. Oznacza to, że pobieranie, analizowanie i kompilowanie skryptu exif-reader odbywa się poza wątkiem głównym.
Teraz przejdźmy do kodu web workera, który to wszystko umożliwia.
Przyjrzyjmy się kodowi instancji roboczej
Nie wystarczy zobaczyć, jaką różnicę wprowadza web worker. Warto też zrozumieć – przynajmniej w tym przypadku – jak wygląda ten kod, aby wiedzieć, co jest możliwe w zakresie web workera.
Zacznij od kodu głównego wątku, który musi wystąpić, zanim web worker będzie mógł wejść do akcji:
// scripts.js
// Register the Exif reader web worker:
const exifWorker = new Worker('/js/with-worker/exif-worker.js');
// We have to send image requests through this proxy due to CORS limitations:
const imageFetchPrefix = 'https://res.cloudinary.com/demo/image/fetch/';
// Necessary elements we need to select:
const imageFetchPanel = document.getElementById('image-fetch');
const imageExifDataPanel = document.getElementById('image-exif-data');
const exifDataPanel = document.getElementById('exif-data');
const imageInput = document.getElementById('image-url');
// What to do when the form is submitted.
document.getElementById('image-form').addEventListener('submit', event => {
// Don't let the form submit by default:
event.preventDefault();
// Send the image URL to the web worker on submit:
exifWorker.postMessage(`${imageFetchPrefix}${imageInput.value}`);
});
// This listens for the Exif metadata to come back from the web worker:
exifWorker.addEventListener('message', ({ data }) => {
// This populates the Exif metadata viewer:
exifDataPanel.innerHTML = data.message;
imageFetchPanel.style.display = 'none';
imageExifDataPanel.style.display = 'block';
});
Ten kod jest wykonywany w głównym wątku i konfiguruje formularz tak, aby wysyłać adres URL obrazu do procesu roboczego. Kod web workera zaczyna się od instrukcji importScripts, która wczytuje zewnętrzny skrypt exif-reader, a następnie konfiguruje potok przesyłania wiadomości do wątku głównego:
// exif-worker.js
// Import the exif-reader script:
importScripts('/js/with-worker/exifreader.js');
// Set up a messaging pipeline to send the Exif data to the `window`:
self.addEventListener('message', ({ data }) => {
getExifDataFromImage(data).then(status => {
self.postMessage(status);
});
});
Ten fragment kodu JavaScript konfiguruje potok przesyłania wiadomości, tak aby po przesłaniu przez użytkownika formularza z adresem URL pliku JPEG adres URL docierał do procesu roboczego.
Następnie ten fragment kodu wyodrębnia metadane Exif z pliku JPEG, tworzy ciąg HTML i wysyła go z powrotem do elementu window, aby ostatecznie wyświetlić go użytkownikowi:
// Takes a blob to transform the image data into an `ArrayBuffer`:
// NOTE: these promises are simplified for readability, and don't include
// rejections on failures. Check out the complete web worker code:
// https://chrome.dev/learn-performance-exif-worker/js/with-worker/exif-worker.js
const readBlobAsArrayBuffer = blob => new Promise(resolve => {
const reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.readAsArrayBuffer(blob);
});
// Takes the Exif metadata and converts it to a markup string to
// display in the Exif metadata viewer in the DOM:
const exifToMarkup = exif => Object.entries(exif).map(([exifNode, exifData]) => {
return `
<details>
<summary>
<h2>${exifNode}</h2>
</summary>
<p>${exifNode === 'base64' ? `<img src="data:image/jpeg;base64,${exifData}">` : typeof exifData.value === 'undefined' ? exifData : exifData.description || exifData.value}</p>
</details>
`;
}).join('');
// Fetches a partial image and gets its Exif data
const getExifDataFromImage = imageUrl => new Promise(resolve => {
fetch(imageUrl, {
headers: {
// Use a range request to only download the first 64 KiB of an image.
// This ensures bandwidth isn't wasted by downloading what may be a huge
// JPEG file when all that's needed is the metadata.
'Range': `bytes=0-${2 ** 10 * 64}`
}
}).then(response => {
if (response.ok) {
return response.clone().blob();
}
}).then(responseBlob => {
readBlobAsArrayBuffer(responseBlob).then(arrayBuffer => {
const tags = ExifReader.load(arrayBuffer, {
expanded: true
});
resolve({
status: true,
message: Object.values(tags).map(tag => exifToMarkup(tag)).join('')
});
});
});
});
Jest to dość długi tekst, ale ten przypadek użycia jest dość złożony w przypadku instancji roboczych.
Wyniki są jednak warte wysiłku i nie ograniczają się tylko do tego przypadku użycia.
Web workerów możesz używać do różnych celów, np. do izolowania wywołań fetch i przetwarzania odpowiedzi czy przetwarzania dużych ilości danych bez blokowania głównego wątku. To tylko kilka przykładów.
Podczas zwiększania wydajności aplikacji internetowych zacznij myśleć o wszystkim, co można rozsądnie zrobić w kontekście Web Workera. Korzyści mogą być znaczne i przynieść ogólną poprawę komfortu użytkowników Twojej witryny.