

公開日: 2025 年 11 月 10 日
適切なサイズの AI について学習すると、基盤モデルよりも小さいモデルの方が持続可能性が高いことがわかります。消費電力が少なく、ユーザーのデバイスで実行することもできるため、レイテンシが短縮され、パフォーマンスの高いエクスペリエンスを提供できます。
意図的に、ユースケースに適したモデルを選択する必要があります。
では、必要なモデルをどのように判断すればよいのでしょうか?1 つのアプローチは、アプリケーションの成功指標を決定し、基盤モデルでプロトタイプを作成することです。最近、ニュースで取り上げられている基盤モデルの多くは大規模言語モデル(LLM)ですが、基盤モデルには予測 AI も含まれています。予測 AI は特殊化されており、ユースケースに適している場合があります。
成功指標を検証したら、より小さなモデルでデプロイし、成功基準を満たす結果を生成する最小のモデルが見つかるまでテストします。
プロトタイプは大きく、デプロイは小さく
適切なサイズのモデルを選択する手順は次のとおりです。
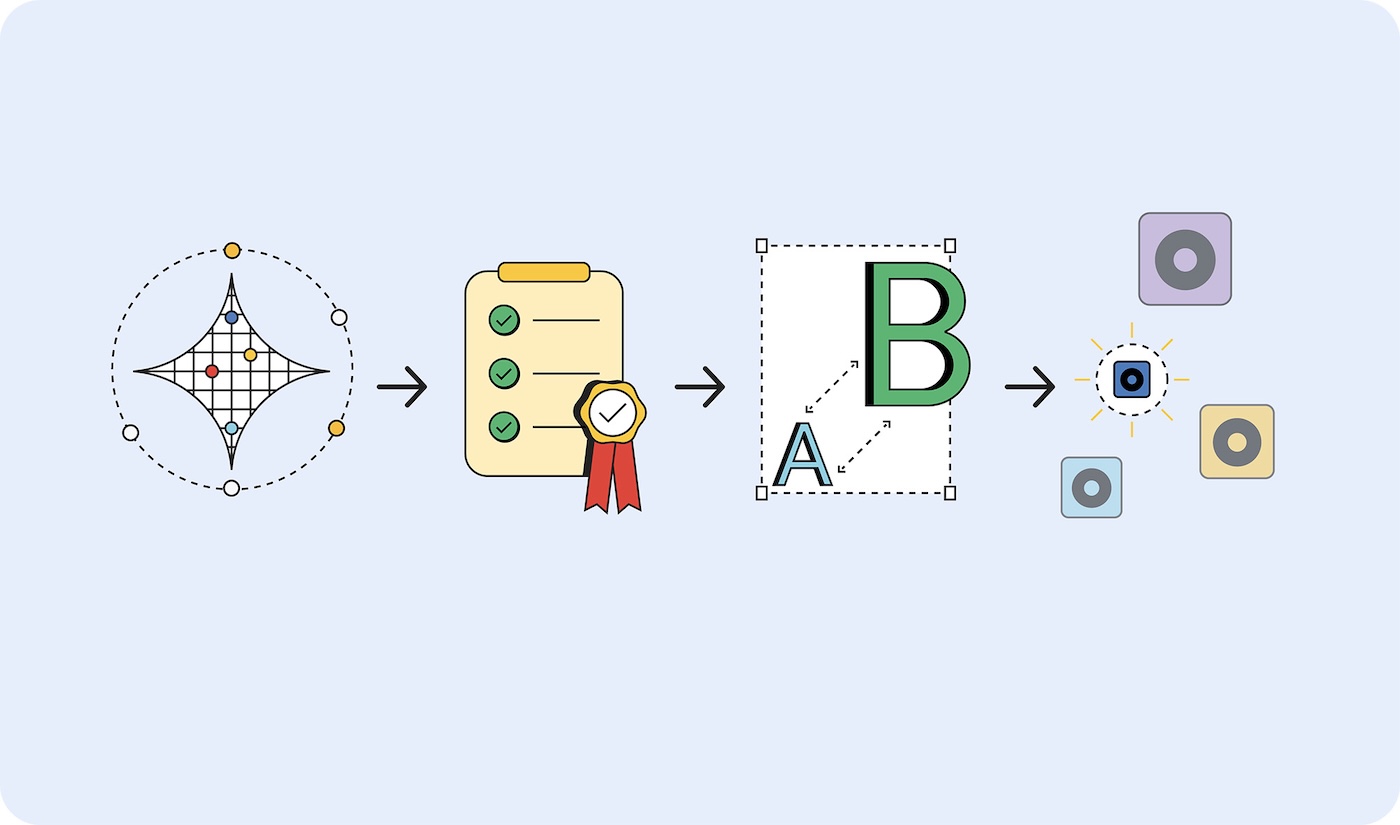
- タスクが実行可能であることを証明します。可能な限り最大のモデルを使用して、達成しようとしていることが可能かどうかをテストします。これは、Gemini 2.5 Pro などの大規模言語モデルや、別の基盤モデルである可能性があります。
- 成功基準を設定する。入力と理想的な出力のセットを収集します。たとえば、翻訳アプリでは、英語のフレーズを入力すると、そのフレーズがスペイン語に正しく翻訳されて出力されます。
- 小規模から大規模までテストする。小規模なモデルの出力をテスト基準と比較します。最小のモデルから順に試してください。プロンプト エンジニアリングは、より良い結果を得るのに役立ちます。より大きなモデルを呼び出して出力を比較することもできます。これにより、小さなモデルからより良い結果を得ることができます。
- ユースケースで許容できるレスポンスが得られる最小のモデルを選択します。たとえば、翻訳を正しく出力する最小のモデルなどです。
モデルがオンデバイスでホストされるほど小さいか、サーバーでホストする必要があるかに関係なく、大規模なモデルよりも小規模なモデルを使用する方が効率的です。
モデルタイプ
モデルは、処理するデータ(画像、音声、テキスト)ごとに分類されています。ユースケースの例と利用可能なモデルの一部について説明します。
視覚処理
視覚処理は、静止画または動画の評価です。
画像分類: アクセシビリティ準拠のための代替テキストの生成から、コンテンツ スクリーニング、ユーザーに届く前に不適切な画像をフィルタリングするまで、あらゆる用途に使用します。この画像分類は、人間によるレビューなしで画像の内容を理解する必要がある場合に使用します。
モデル: MobileNet、ResNeXt、ConvNeXt
オブジェクト検出: 画像や動画ストリーム内の特定のオブジェクトにタグを付け、現実世界のオブジェクトに反応するインタラクティブな AR エクスペリエンスを作成したり、アイテムを識別してカウントできる在庫管理システムを構築したりできます。無生物の画像や動画がある場合は、オブジェクト検出を選択します。
モデル: YOLOv8 や DETR などのオブジェクト検出モデル
身体のポーズ検出: ジェスチャーや身体の動きによるインターフェース制御、衣料品のバーチャル試着、患者の動きやリハビリの進捗状況をモニタリングする遠隔医療プラットフォームなどに使用します。人物の身体の画像や動画を評価する場合は、身体のポーズの検出を選択します。
モデル MoveNet や BlazePose などのポーズ推定モデル
顔のキーポイント検出: 安全な顔認証システム、ユーザー エクスペリエンスをパーソナライズするための感情検出、アクセシビリティ コントロールのための目の動きのトラッキング、リアルタイムの写真フィルタや美容アプリに使用します。人物の顔の画像や動画を評価する場合は、このモデルを選択します。
モデル: MediaPipe FaceMesh と OpenPose
手のポーズ検出モデル: ユーザーが手のジェスチャーで操作するタッチフリー インターフェース コントロール、アクセシビリティのための手話翻訳アプリ、手の動きに反応して描画やデザインを行うクリエイティブ ツールなどに使用します。また、画面に触れることが難しい環境(医療、食品サービス)や、ユーザーがコントロールから離れている場合(プレゼンテーションでスピーカーがジェスチャーでスライドを操作する場合など)での使用も検討してください。
モデル: MediaPipe Hands などの手のポーズ推定モデル。
手書き文字認識: 手書きメモを検索可能なデジタル テキストに変換したり、メモアプリのタッチペン入力を処理したり、ユーザーがアップロードしたフォームやドキュメントをデジタル化したりするために使用します。
モデル: MiniCPM-o、H2OVL-Mississippi、Surya などの光学式文字認識(OCR)モデル。
画像セグメンテーション モデル: 一貫した画像の背景が重要な場合や、画像編集が必要な場合に選択します。たとえば、背景の正確な削除、画像内の特定の懸念領域を特定するための高度なコンテンツ スクリーニング、プロフィール写真や商品写真などの特定の要素を分離するための高度な写真編集ツールなどに使用できます。
モデル: Segment Anything(SAM)、Mask R-CNN
画像生成: ライセンスを取得せずに、オンデマンドで新しい画像を作成するために使用します。これらのモデルは、ユーザー プロフィール用のパーソナライズされたアバター、e コマース カタログ用の商品画像のバリエーション、マーケティングやコンテンツ作成のワークフロー用のカスタム ビジュアルの作成に使用できます。
モデル: Nano Banana、Flux、Qwen Image などの拡散モデル
音声処理
音声ファイルの音声処理モデルを選択します。
音声分類: 人間のレビューなしで音声を識別して説明する必要がある場合に使用します。たとえば、メディア アップロードでのバックグラウンド ミュージック、環境音、音声コンテンツのリアルタイム識別、オーディオ ライブラリの自動コンテンツ タグ付け、音ベースのユーザー インターフェース コントロールなどです。
モデル: Wav2Vec2 と AudioMAE
音声生成: ライセンスを取得せずに、オンデマンドで音声コンテンツを作成します。たとえば、インタラクティブなウェブ エクスペリエンス用のカスタム効果音の作成、ユーザーの好みやコンテンツに基づくバックグラウンド ミュージックの生成、通知音やインターフェース フィードバックなどのオーディオ ブランディング要素の作成などに使用できます。
モデル: さまざまな特殊な音声生成モデルがあります。これらは非常に具体的なものであるため、モデルは記載しません。
テキスト読み上げ(TTS): アクセシビリティのコンプライアンスを遵守するために、記述されたコンテンツを自然な音声に変換します。教育コンテンツやチュートリアルのナレーションを作成したり、ユーザーが希望する言語でテキストを読み上げる多言語インターフェースを構築したりできます。
モデル: Orpheus と Sesame の CSM
音声文字変換(STT): ライブイベントや会議のリアルタイム文字起こし、音声制御によるナビゲーションと検索機能、動画コンテンツのアクセシビリティのための自動字幕生成など、人間の音声の録音を文字起こしします。
モデル Whisper Web Turbo、NVIDIA Canary、Kyutai
テキスト処理
自然言語分類(NLP): 大量のテキスト、タグ付けシステム、モデレーション システムを自動的に分類して転送するために使用します。テキストは、ユーザー メッセージやサポート チケット、顧客フィードバックやソーシャル メディアでの言及の感情分析、他のユーザーに届く前にスパムや不適切なコンテンツをフィルタリングするなどの用途に使用できます。
モデル BERT、DistilBERT、RoBERTa
会話型 AI: チャット インターフェースと会話型システムを構築します。顧客サポートの chatbot、パーソナル AI アシスタントなど、会話型インタラクションは LLM の最適なユースケースの一部です。幸いなことに、デバイスに収まるほど小さく、トレーニングやプロンプトに必要なエネルギーがはるかに少ない言語モデルがあります。
モデル Gemma 2 27B、Llama 3.1、Qwen2.5
翻訳モデル: アプリケーションで複数の言語をサポートするために使用します。ローカル言語モデルは、リアルタイムの言語翻訳、グローバル プラットフォーム向けの複数の言語にわたるユーザー生成コンテンツの変換、ユーザーのデバイスで機密性の高いコンテンツを保持するプライベート ドキュメント翻訳を処理できます。
モデル: Gemma Nano、Granite 1.5B、GSmolLM3、Qwen 3.4B などの SLM
栄養成分表示を読む

モデルによって、異なるロケーションの異なるハードウェアで実行されるときに消費するリソースの量が異なります。まだベンチマークとなる測定基準はありませんが、この情報を AI の「栄養成分表示」に記載しようという動きがあります。
モデルカードは、2018 年に Google の Margaret Mitchell 氏らが導入したもので、モデルの用途、制限事項、倫理的考慮事項、パフォーマンスを報告するための標準化されたアプローチです。現在、Hugging Face、Meta、Microsoft など、多くの企業がモデルカードの形式を使用しています。
IBM の AI Factsheets は、ライフサイクル、説明責任、ガバナンス、コンプライアンスを網羅しており、エンタープライズ環境でより広く利用されています。EU AI 法、NIST AI リスク管理フレームワーク、ISO 42001 などの規制フレームワークでは、このドキュメントが求められています。
Google は、業界全体で推論費用の透明性を高めるよう呼びかけました。これらの数値は、モデルカードやファクトシートに追加できます。Hugging Face は、モデルカードに炭素コストを追加し、AI エネルギー スコア イニシアチブでエネルギー効率の測定を標準化する取り組みを行っています。
適切なサイズの AI を推進する
適切なサイズの AI は、お客様とビジネスにとって持続可能で、パフォーマンスが高く、実用的な選択肢です。
企業が採用するホスト型モデルにベースラインのトレーニングと推論のリソース要件を開示することを義務付けることで、業界を前進させることができます。十分な数のユーザーが透明性を求めている場合、プロバイダは詳細を公開する可能性が高くなります。