

Data publikacji: 10 listopada 2025 r.
Po przeczytaniu artykułu o AI o odpowiedniej wielkości wiesz, że mniejsze modele są bardziej ekologiczne niż modele podstawowe. Zużywają mniej energii i mogą być uruchamiane na urządzeniu użytkownika, co zmniejsza opóźnienia i zwiększa wydajność.
Musisz to robić świadomie i wybrać odpowiedni model do swojego przypadku użycia.
Jak jednak określić, którego modelu potrzebujesz? Jednym ze sposobów jest określenie wskaźników sukcesu aplikacji, a następnie utworzenie prototypu z użyciem modelu podstawowego. W ostatnim czasie wiele modeli podstawowych, o których się mówi, to duże modele językowe (LLM). Modele podstawowe obejmują też jednak predykcyjną AI, która jest wyspecjalizowana i może lepiej pasować do Twojego zastosowania.
Po sprawdzeniu wyznaczników sukcesu wdróż mniejsze modele i przeprowadzaj testy, aż znajdziesz najmniejszy możliwy model, który przynosi wyniki spełniające Twoje kryteria sukcesu.
Twórz prototypy na dużą skalę, wdrażaj na małą
Aby wybrać odpowiedni model, wykonaj te czynności:
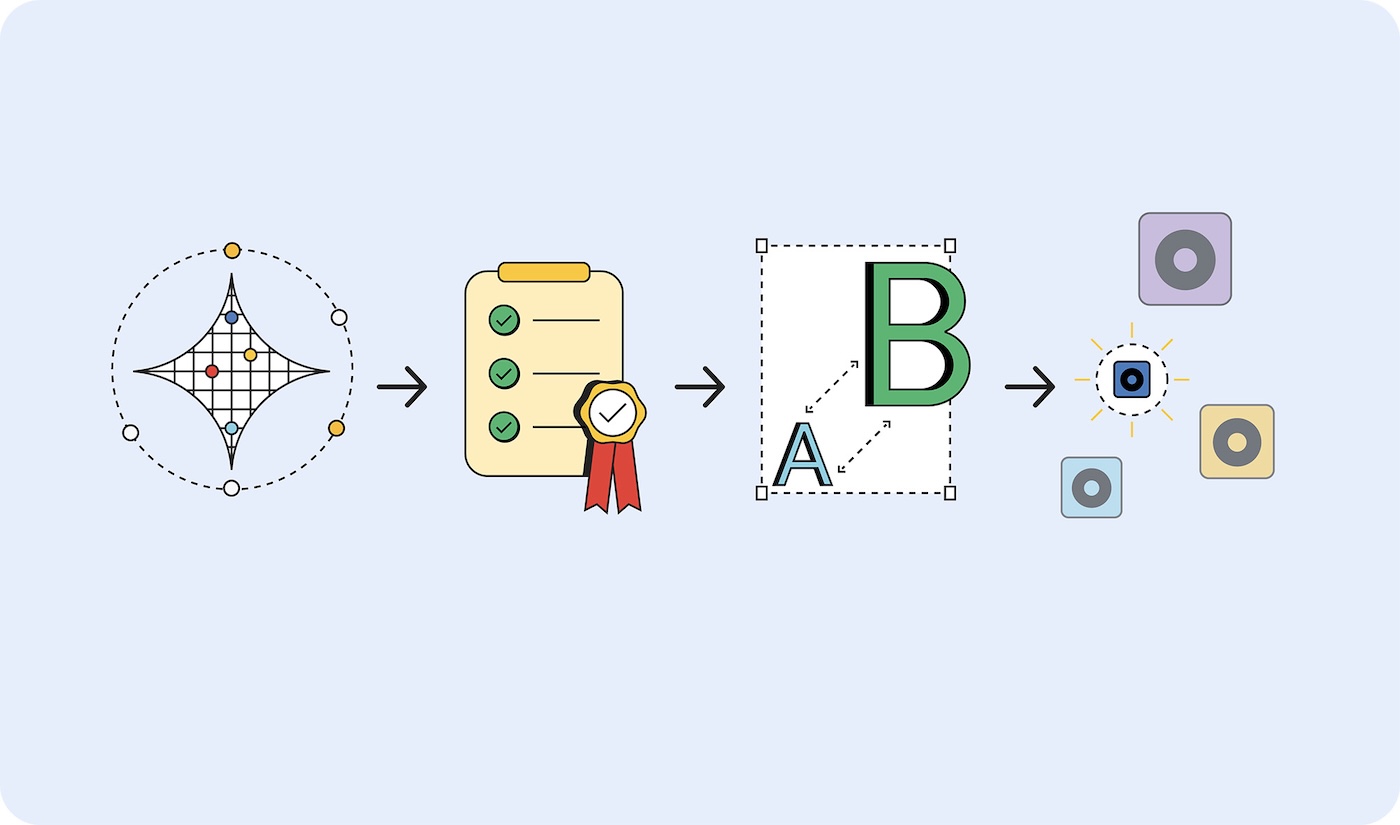
- Udowodnij, że zadanie jest możliwe do wykonania. Sprawdź, czy to, co chcesz osiągnąć, jest w ogóle możliwe, korzystając z największego dostępnego modelu. Może to być duży model językowy, np. Gemini 2.5 Pro, lub inny model podstawowy.
- Określ kryteria sukcesu. Zbierz zestaw danych wejściowych i idealnych danych wyjściowych. Na przykład aplikacja do tłumaczenia może przyjmować frazy w języku angielskim i zwracać te frazy przetłumaczone poprawnie na język hiszpański.
- Testuj od małych do dużych. Porównaj dane wyjściowe mniejszych modeli z kryteriami testu. Zacznij od najmniejszego modelu. Inżynieria promptów może pomóc Ci uzyskać lepsze wyniki. Możesz też użyć większego modelu do porównania wyników, aby uzyskać lepsze wyniki z mniejszego modelu.
- Wybierz najmniejszy model, który zapewnia akceptowalne odpowiedzi w Twoim przypadku użycia. Na przykład najmniejszy model, który prawidłowo tłumaczy.
Niezależnie od tego, gdzie jest hostowany model, jeśli jest wystarczająco mały, aby można go było używać na urządzeniu, lub nadal musi być hostowany na serwerze, bardziej wydajne jest używanie mniejszego modelu niż większego.
Typy modeli
Modele zostały podzielone na kategorie według rodzaju przetwarzanych danych: wizualnych, audio i tekstowych. Przedstawię Ci przykładowe przypadki użycia i niektóre z dostępnych modeli.
Przetwarzanie wizualne
Przetwarzanie wizualne może obejmować ocenę zdjęć lub filmów.
Klasyfikacja obrazów: używaj jej do wszystkiego, od generowania tekstu alternatywnego w celu zapewnienia zgodności z wymaganiami dotyczącymi ułatwień dostępu po filtrowanie treści, aby odrzucać nieodpowiednie obrazy, zanim dotrą do użytkowników. Wybierz tę klasyfikację obrazu, jeśli chcesz dowiedzieć się, co znajduje się na obrazie, bez weryfikacji przez człowieka.
Modele MobileNet, ResNeXt i ConvNeXt
Wykrywanie obiektów: tagowanie konkretnych obiektów na obrazach lub w strumieniach wideo, tworzenie interaktywnych doświadczeń AR, które reagują na obiekty w świecie rzeczywistym, lub budowanie systemów zarządzania zapasami, które mogą identyfikować i liczyć produkty. Wybierz wykrywanie obiektu, jeśli masz zdjęcie lub film przedstawiający obiekt nieożywiony.
Modele: modele wykrywania obiektów, takie jak YOLOv8 i DETR.
Wykrywanie pozycji ciała: używaj tej funkcji do sterowania interfejsem za pomocą gestów lub ruchów ciała, wirtualnego przymierzania ubrań oraz na platformach telemedycznych do monitorowania ruchów pacjentów i postępów w rehabilitacji. Wybierz wykrywanie pozycji ciała, gdy oceniasz zdjęcia lub filmy przedstawiające ciało osoby.
Modele, np. modele do szacowania pozycji, takie jak MoveNet i BlazePose.
Wykrywanie kluczowych punktów twarzy: używaj tej funkcji w bezpiecznych systemach uwierzytelniania za pomocą twarzy, do wykrywania emocji w celu personalizowania wrażeń użytkowników, do śledzenia ruchów oczu w celu zapewnienia dostępnych elementów sterujących oraz do filtrów zdjęć w czasie rzeczywistym lub aplikacji do upiększania. Wybierz ten model, jeśli oceniasz obrazy lub filmy przedstawiające twarz osoby.
Modele MediaPipe FaceMesh i OpenPose
Modele wykrywania pozycji dłoni: używaj ich w interfejsach bezdotykowych, w których użytkownicy poruszają się za pomocą gestów dłoni, w aplikacjach do tłumaczenia języka migowego na potrzeby ułatwień dostępu oraz w narzędziach kreatywnych, które reagują na ruchy dłoni podczas rysowania lub projektowania. Rozważ też używanie ich w środowiskach, w których dotykanie ekranów jest niepraktyczne (medycyna, gastronomia) lub gdy użytkownicy będą daleko od elementów sterujących, np. podczas prezentacji, w których prelegenci sterują slajdami za pomocą gestów.
Modele modele szacowania pozycji dłoni, takie jak MediaPipe Hands;
Rozpoznawanie pisma odręcznego: służy do przekształcania odręcznych notatek w tekst cyfrowy, który można przeszukiwać, przetwarzania danych wprowadzanych rysikiem w aplikacjach do robienia notatek oraz digitalizowania formularzy lub dokumentów przesłanych przez użytkowników.
Modele optycznego rozpoznawania znaków (OCR), takie jak MiniCPM-o, H2OVL-Mississippi i Surya.
Modele segmentacji obrazów: wybierz, kiedy ważne są spójne tła obrazów lub gdy wymagana jest edycja obrazów. Możesz ich na przykład używać do precyzyjnego usuwania tła, zaawansowanego sprawdzania treści w celu identyfikowania konkretnych obszarów problematycznych na obrazach oraz zaawansowanych narzędzi do edycji zdjęć, aby wyodrębniać poszczególne elementy, takie jak zdjęcia profilowe i zdjęcia produktów.
Modele Segment Anything (SAM), Mask R-CNN
Generowanie obrazów: umożliwia tworzenie nowych obrazów na żądanie bez konieczności wykupywania licencji. Modele te mogą służyć do tworzenia spersonalizowanych awatarów w profilach użytkowników, wariantów zdjęć produktów w katalogach e-commerce oraz niestandardowych wizualizacji w przypadku marketingowych lub związanych z tworzeniem treści procesów.
Modele modele dyfuzyjne, takie jak Nano Banana, Flux i Qwen Image
Przetwarzanie dźwięku
Wybierz model przetwarzania dźwięku dla plików audio.
Klasyfikacja dźwięku: używaj, gdy dźwięk musi zostać zidentyfikowany i opisany bez weryfikacji przez człowieka. Na przykład identyfikacja w czasie rzeczywistym muzyki w tle, dźwięków otoczenia lub treści mówionych w przesyłanych plikach multimedialnych, automatyczne tagowanie treści w bibliotekach audio i sterowanie interfejsem użytkownika za pomocą dźwięku.
Modele Wav2Vec2 i AudioMAE
Generowanie dźwięku: tworzenie treści audio na żądanie bez konieczności uzyskiwania licencji. Można jej na przykład używać do tworzenia niestandardowych efektów dźwiękowych na potrzeby interaktywnych stron internetowych, generowania muzyki w tle na podstawie preferencji użytkownika lub treści oraz tworzenia elementów marki audio, takich jak dźwięki powiadomień czy informacje zwrotne z interfejsu.
Modele Istnieją różne specjalistyczne modele generowania dźwięku. Zwykle są one bardzo szczegółowe, więc nie będę wymieniać modeli.
Zamiana tekstu na mowę (TTS): przekształcanie treści pisanych w spójny, naturalnie brzmiący głos, aby zapewnić zgodność z ułatwieniami dostępu, tworzyć narrację do treści edukacyjnych lub samouczków oraz budować wielojęzyczne interfejsy, które odczytują tekst w preferowanych językach użytkowników.
Modele Orpheus i Sesame CSM
Zamiana mowy na tekst: transkrypcja nagrań mowy, np. transkrypcja w czasie rzeczywistym podczas wydarzeń na żywo lub spotkań, nawigacja i wyszukiwanie sterowane głosem oraz automatyczne napisy do treści wideo ułatwiające dostępność.
Modele: Whisper Web Turbo, NVIDIA Canary i Kyutai
Przetwarzanie tekstu
Klasyfikacja języka naturalnego (NLP): używaj jej do automatycznego sortowania i kierowania dużych ilości tekstu, systemów tagowania i systemów moderowania. Tekst może pochodzić z wiadomości użytkowników lub zgłoszeń do działu pomocy, a jego analiza może służyć do wykrywania nastrojów w opiniach klientów lub wzmiankach w mediach społecznościowych oraz do filtrowania spamu lub nieodpowiednich treści, zanim dotrą one do innych użytkowników.
Modele BERT, DistilBERT i RoBERTa
Konwersacyjna AI: tworzenie interfejsów czatu i systemów konwersacyjnych. Czatboty obsługi klienta, osobiste asystenty AI i podobne interakcje konwersacyjne to jedne z najlepszych zastosowań dużych modeli językowych. Na szczęście istnieją modele językowe, które są wystarczająco małe, aby zmieścić się na urządzeniu, i które wymagają znacznie mniej energii do trenowania i generowania odpowiedzi.
Modele Gemma 2 27B, Llama 3.1 i Qwen2.5
Modele tłumaczeń: używaj ich, aby obsługiwać w aplikacji wiele języków. Modele językowe działające lokalnie mogą tłumaczyć język w czasie rzeczywistym, konwertować treści generowane przez użytkowników w wielu językach na potrzeby platform globalnych oraz umożliwiać prywatne tłumaczenie dokumentów, które zachowuje poufne treści na urządzeniu użytkownika.
Modele SLM, takie jak Gemma Nano, Granite 1.5B, GSmolLM3 i Qwen 3.4B
Odczytaj etykietę dotyczącą wartości odżywczych

Różne modele zużywają różne ilości tych zasobów, gdy są uruchamiane na różnych urządzeniach w różnych lokalizacjach. Nie ma jeszcze standardu pomiaru, do którego można by się odnieść, ale trwają prace nad umieszczeniem tych informacji na „etykietach” AI.
Karty modeli, wprowadzone przez Margaret Mitchell i jej współpracowników w Google w 2018 roku, to standardowe podejście do raportowania zamierzonego zastosowania modeli, ich ograniczeń, kwestii etycznych i wydajności. Obecnie wiele firm korzysta z formy kart modeli, m.in. Hugging Face, Meta i Microsoft.
Arkusz informacji o AI od IBM, który obejmuje cykl życia, odpowiedzialność, zarządzanie i zgodność, jest bardziej popularny w środowiskach korporacyjnych. Wymagają tego ramy prawne, takie jak akt UE o AI, platforma NIST do zarządzania ryzykiem związanym z AI i norma ISO 42001.
Google wezwał do zapewnienia przejrzystości kosztów wnioskowania w całej branży. Te dane można dodać do kart modeli i arkuszy informacyjnych. Firma Hugging Face dodała do kart modeli informacje o kosztach emisji dwutlenku węgla i podjęła działania mające na celu standaryzację pomiarów efektywności energetycznej w ramach inicjatywy AI Energy Score.
Promowanie odpowiednio dopasowanej AI
Odpowiednio dobrana AI to zrównoważone, skuteczne i praktyczne rozwiązanie dla Twoich klientów i Twojej firmy.
Możesz przyczynić się do rozwoju branży, wymagając od hostowanych modeli, które Twoja firma wdraża, ujawniania podstawowych wymagań dotyczących zasobów do trenowania i wnioskowania. Jeśli wystarczająca liczba klientów będzie domagać się przejrzystości, dostawcy z większym prawdopodobieństwem udostępnią te informacje.