

מבוא
Media Source Extensions (MSE) מספקות הרחבה של השמירה בזיכרון הזמני (באפרינג) ובקרה על ההפעלה של רכיבי HTML5 <audio> ו-<video>. הם פותחו במקור כדי להקל על שימוש בנגני וידאו שמבוססים על שידור דינמי שניתן להתאמה באמצעות HTTP (DASH), אבל בהמשך נראה איך אפשר להשתמש בהם גם לאודיו, במיוחד כדי לאפשר הפעלה רציפה.
סביר להניח שהאזנתם לאלבום מוזיקה שבו השירים זורמים בצורה חלקה בין הטראקים, ואולי אתם אפילו מאזינים לאחד כזה עכשיו. אומנים יוצרים חוויות של השמעה רציפה גם כבחירה אומנותית וגם כתוצר של תקליטי ויניל ותקליטורים, שבהם האודיו נכתב כזרם רציף אחד. לצערי, בגלל האופן שבו קודקים מודרניים של אודיו כמו MP3 ו-AAC פועלים, חוויית השמיעה החלקה הזו לרוב לא קיימת היום.
בהמשך נפרט למה, אבל בינתיים נתחיל בהדגמה. בהמשך מוצגות 30 השניות הראשונות של הסרט המעולה Sintel, שחולקו לחמישה קובצי MP3 נפרדים וחוברו מחדש באמצעות MSE. הקווים האדומים מציינים פערים שנוצרו במהלך היצירה (הקידוד) של כל קובץ MP3. תשמעו גליצ'ים בנקודות האלה.
איכס! זו לא חוויה טובה, ואנחנו יכולים להשתפר. בעזרת קובצי ה-MP3 שמופיעים בהדגמה שלמעלה, אפשר להשתמש ב-MSE כדי להסיר את הפערים המעצבנים האלה. הקווים הירוקים בהדגמה הבאה מציינים את המיקומים שבהם הקבצים אוחדו והפערים הוסרו. ב-Chrome 38 ואילך, ההפעלה תהיה חלקה.
יש מגוון דרכים ליצור תוכן ללא פערים. לצורך ההדגמה הזו, נתמקד בסוגי הקבצים שמשתמש רגיל עשוי להחזיק. שבו כל קובץ עבר קידוד בנפרד בלי להתייחס לקטעי האודיו שלפניו או אחריו.
הגדרה בסיסית
קודם נחזור אחורה ונסביר על ההגדרה הבסיסית של מכונת MediaSource.
תוספי Media Source, כפי שהשם מרמז, הם רק תוספים לרכיבי המדיה הקיימים. בדוגמה הבאה, אנחנו מקצים את Object URL, שמייצג את מופע MediaSource שלנו, למאפיין המקור של רכיב אודיו, בדיוק כמו שהייתם מגדירים כתובת URL רגילה.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
אחרי שמחברים את אובייקט MediaSource, הוא מבצע כמה פעולות אתחול ובסופו של דבר מפעיל אירוע sourceopen. בשלב הזה אפשר ליצור SourceBuffer. בדוגמה שלמעלה, אנחנו יוצרים audio/mpeg, שיכול לנתח ולפענח את פלחי ה-MP3 שלנו. יש סוגים אחרים שזמינים.
צורות גל חריגות
נחזור לקוד עוד מעט, אבל עכשיו נסתכל מקרוב על הקובץ שצירפנו, במיוחד על סופו. בהמשך מוצג תרשים של 3, 000 הדגימות האחרונות בממוצע בשני הערוצים מתוך sintel_0.mp3
המסלול. כל פיקסל בקו האדום הוא דגימה של נקודה צפה בטווח של [-1.0, 1.0].

למה יש כל כך הרבה דגימות שקטות (עם אפס צלילים)? הם למעשה נובעים מארטיפקטים של דחיסה שנוצרו במהלך הקידוד. כמעט כל מקודד מוסיף סוג כלשהו של ריפוד. במקרה הזה, LAME הוסיף בדיוק 576 דגימות ריפוד לסוף הקובץ.
בנוסף לריפוד בסוף, לכל קובץ נוסף ריפוד גם בהתחלה. אם נסתכל קדימה על
sintel_1.mp3
הטראק, נראה שיש עוד 576 דגימות של ריפוד בחלק הקדמי. כמות הריפוד משתנה בהתאם לקודד ולתוכן, אבל אנחנו יודעים את הערכים המדויקים על סמך metadata שכלול בכל קובץ.
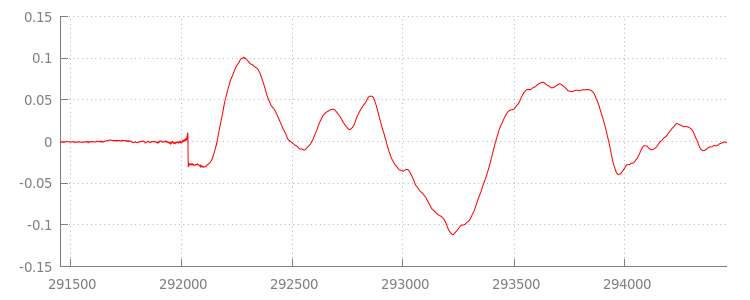
קטעי השקט בתחילת כל קובץ ובסופו הם אלה שגורמים לתקלות בין הפלחים בהדגמה הקודמת. כדי להשיג השמעה רציפה, צריך להסיר את קטעי השקט האלה. למרבה המזל, אפשר לעשות את זה בקלות באמצעות MediaSource. בהמשך נשנה את השיטה onAudioLoaded() כדי להשתמש בחלון הוספה ובהזזה של חותמת הזמן כדי להסיר את השקט הזה.
קוד לדוגמה
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
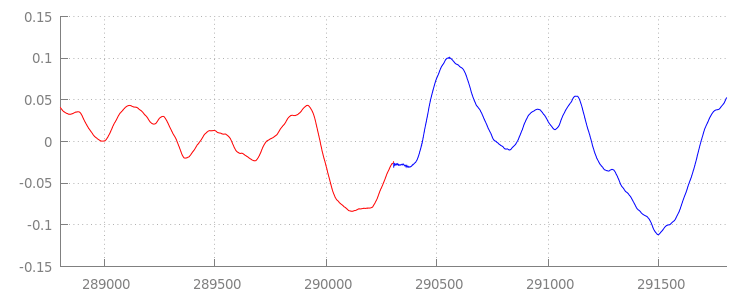
צורת גל חלקה
כדי לראות מה הקוד החדש והמבריק שלנו השיג, נבדוק שוב את צורת הגל אחרי שהוספנו את חלונות הצירוף. אפשר לראות למטה שהקטע השקט בסוף של sintel_0.mp3 (באדום) והקטע השקט בתחילת sintel_1.mp3 (בכחול) הוסרו, כך שנוצר מעבר חלק בין מקטעים.
סיכום
בשלב הזה, חיברנו את כל חמשת הקטעים בצורה חלקה לסרטון אחד, והגענו לסוף ההדגמה. לפני שנסיים, יכול להיות ששמת לב ששיטת onAudioLoaded() שלנו לא מתייחסת לקונטיינרים או לקודקים.
כלומר, כל הטכניקות האלה יעבדו בלי קשר לסוג הקונטיינר או הקודק. למטה אפשר להפעיל מחדש את הדמו המקורי של MP4 מפוצל שמוכן ל-DASH
במקום MP3.
אם אתם רוצים לקבל מידע נוסף, תוכלו לעיין בנספחים שבהמשך כדי לקבל הסבר מפורט יותר על יצירת תוכן ללא הפסקה ועל ניתוח מטא-נתונים. אפשר גם לעיין בקוד שמופיע ב-gapless.js כדי להבין איך ההדגמה הזו פועלת.
תודה על שקראת מידע זה!
נספח א': יצירת תוכן ללא פערים
יצירת תוכן ללא פערים יכולה להיות מסובכת. בהמשך נסביר איך ליצור את המדיה של Sintel שבה נעשה שימוש בהדגמה הזו. כדי להתחיל, תצטרכו עותק של פסקול FLAC ללא אובדן נתונים של הסרט Sintel. למען השקיפות, מצורף בהמשך קוד ה-SHA1. כדי להשתמש בכלים, תצטרכו את FFmpeg, MP4Box, LAME, וגם התקנה של OSX עם afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
קודם נפריד את 31.5 השניות הראשונות של טראק 1-Snow_Fight.flac. אנחנו רוצים גם להוסיף דהייה של 2.5 שניות שמתחילה אחרי 28 שניות, כדי למנוע קליקים אחרי שההפעלה מסתיימת. אפשר לבצע את כל הפעולות האלה באמצעות שורת הפקודה של FFmpeg שמופיעה בהמשך, ולשמור את התוצאות בקובץ sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
לאחר מכן, נחלק את הקובץ ל-5 קובצי wave באורך של 6.5 שניות כל אחד. הכי קל להשתמש ב-wave כי כמעט כל מקודד תומך בהעלאה שלו. שוב, אפשר לעשות את זה בדיוק באמצעות FFmpeg, ואז נקבל: sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav ו-sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
עכשיו ניצור את קובצי ה-MP3. ל-LAME יש כמה אפשרויות ליצירת תוכן ללא הפסקות. אם יש לכם שליטה בתוכן, כדאי להשתמש ב---nogap
עם קידוד אצווה של כל הקבצים כדי להימנע לחלוטין מריווח בין פלחים.
אבל לצורך ההדגמה הזו, אנחנו רוצים את הריווח הזה, ולכן נשתמש בקידוד VBR רגיל באיכות גבוהה של קובצי הגלים.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
זה כל מה שצריך כדי ליצור את קובצי ה-MP3. עכשיו נסביר איך יוצרים קובצי MP4 מפוצלים. אנחנו פועלים לפי ההוראות של Apple ליצירת מדיה שעברה מאסטרינג ל-iTunes. בהמשך נמיר את קובצי ה-WAV לקובצי CAF ביניים, לפי ההוראות, לפני שנקודד אותם כ-AAC במאגר MP4 באמצעות הפרמטרים המומלצים.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
עכשיו יש לנו כמה קובצי M4A שאנחנו צריכים לפרק בצורה מתאימה לפני שנוכל להשתמש בהם עם MediaSource. לצורך המאמר הזה, נשתמש בגודל מקטע של שנייה אחת. MP4Box
יכתוב כל קובץ MP4 מקוטע כ-sintel_#_dashinit.mp4 יחד עם מניפסט של MPEG-DASH (sintel_#_dash.mpd) שאפשר להתעלם ממנו.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
זהו! מעכשיו יש לנו קובצי MP4 ו-MP3 מפוצלים עם המטא-נתונים הנכונים שנדרשים להפעלה רציפה. פרטים נוספים על המטא-נתונים האלה מופיעים בנספח ב'.
נספח ב': ניתוח מטא-נתונים ללא פערים
בדומה ליצירת תוכן ללא פערים, ניתוח המטא-נתונים ללא פערים יכול להיות מסובך כי אין שיטה סטנדרטית לאחסון. בהמשך נסביר איך שני המקודדים הנפוצים ביותר, LAME ו-iTunes, שומרים את המטא-נתונים שלהם ללא הפסקה. נתחיל בהגדרת כמה שיטות עזר ומתאר של ParseGaplessData() שבהן השתמשנו למעלה.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
נתחיל עם פורמט המטא-נתונים של iTunes של אפל, כי הוא הכי קל לניתוח ולהסבר. בקובצי MP3 ו-M4A, iTunes (ו-afconvert) כותבים קטע קצר ב-ASCII, באופן הבא:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
המידע הזה נכתב בתוך תג ID3 במאגר MP3 ובתוך אטום של מטא-נתונים במאגר MP4. לצורך שלנו, אפשר להתעלם מהטוקן הראשון 0000000. שלושת הטוקנים הבאים הם הריפוד הקדמי, הריפוד האחורי ומספר הדגימות הכולל ללא ריפוד. אם מחלקים כל אחד מהערכים האלה בקצב הדגימה של האודיו, מקבלים את משך הזמן של כל אחד מהם.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
מצד שני, רוב מקודדי ה-MP3 בקוד פתוח יאחסנו את המטא-נתונים ללא הפסקה בכותרת Xing מיוחדת שמוצבת בתוך מסגרת MPEG שקטה (היא שקטה כדי שמפענחים שלא מבינים את הכותרת Xing פשוט ישמיעו שקט). לצערנו, התג הזה לא תמיד מופיע ויש לו מספר שדות אופציונליים. לצורך ההדגמה הזו, יש לנו שליטה במדיה, אבל בפועל נצטרך לבצע בדיקות רגישות נוספות כדי לדעת מתי מטא-נתונים ללא הפסקה זמינים בפועל.
קודם ננתח את מספר המדגם הכולל. לצורך הפשטות, נקרא את זה מהכותרת של Xing, אבל אפשר ליצור את זה מהכותרת הרגילה של MPEG audio.
אפשר לסמן כותרות ב-Xing באמצעות התג Xing או התג Info. בדיוק 4 בייטים אחרי התג הזה יש 32 ביטים שמייצגים את המספר הכולל של הפריימים בקובץ. אם נכפיל את הערך הזה במספר הדגימות לכל פריים, נקבל את המספר הכולל של הדגימות בקובץ.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
עכשיו, אחרי שיש לנו את המספר הכולל של הדגימות, אפשר להמשיך להקראה של מספר דגימות הריפוד. בהתאם למקודד, יכול להיות שהערך הזה ייכתב מתחת לתג LAME או Lavf שמוטמע בכותרת Xing. בדיוק 17 בייטים אחרי הכותרת הזו יש 3 בייטים שמייצגים את הריפוד הקדמי והאחורי, כל אחד ב-12 ביטים.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
כך קיבלנו פונקציה מלאה לניתוח רוב התוכן ללא הפסקות. עם זאת, יש הרבה מקרים חריגים, ולכן מומלץ לנקוט משנה זהירות לפני שמשתמשים בקוד דומה בסביבת הייצור.
נספח ג': על Garbage Collection
הזיכרון ששייך למופעים של SourceBuffer עובר איסוף אשפה באופן פעיל בהתאם לסוג התוכן, למגבלות הספציפיות לפלטפורמה ולמיקום ההפעלה הנוכחי. ב-Chrome, הזיכרון יפונה קודם ממאגרי נתונים זמניים שכבר הופעלו.
עם זאת, אם השימוש בזיכרון חורג מהמגבלות הספציפיות לפלטפורמה, המערכת תסיר זיכרון ממאגרי נתונים זמניים שלא הופעלו.
כשההפעלה מגיעה לפער בציר הזמן בגלל זיכרון שהוחזר, יכול להיות שיהיה גליץ אם הפער קטן מספיק, או שההפעלה תיעצר לגמרי אם הפער גדול מדי. אף אחת מהאפשרויות האלה לא מספקת חוויית משתמש טובה, ולכן חשוב להימנע מהוספה של יותר מדי נתונים בבת אחת ולהסיר באופן ידני טווחי זמן מציר הזמן של המדיה שכבר לא נחוצים.
אפשר להסיר טווחים באמצעות השיטה remove() בכל SourceBuffer, שמקבלת טווח [start, end] בשניות.
בדומה ל-appendBuffer(), כל remove() יפעיל אירוע updateend פעם אחת אחרי שהוא יושלם. אין להוציא פקודות אחרות של הסרה או הוספה עד שהאירוע מופעל.
ב-Chrome למחשב, אפשר לשמור בזיכרון בבת אחת כ-12 מגה-בייט של תוכן אודיו ו-150 מגה-בייט של תוכן וידאו. לא מומלץ להסתמך על הערכים האלה בדפדפנים או בפלטפורמות שונות. למשל, הם לא מייצגים מכשירים ניידים.
איסוף האשפה משפיע רק על נתונים שנוספו ל-SourceBuffers. אין מגבלות על כמות הנתונים שאפשר לשמור במאגר נתונים זמני במשתני JavaScript. במקרה הצורך, אפשר גם להוסיף מחדש את אותם נתונים באותו מיקום.