



发布时间:2025 年 5 月 21 日
Policybazaar 是印度领先的保险平台之一,拥有超过 9, 700 万注册客户。大约 80% 的客户每月都会在线访问 Policybazaar,因此其平台必须提供顺畅的用户体验。
Policybazaar 团队注意到,大量用户会在晚上(即客户服务团队的下班时间)访问他们的网站。Policybazaar 希望实现一项解决方案,让用户无需等到下一个工作日才能获得答案,也不必聘请夜间工作人员,而是能立即获得服务。
客户会对保险方案、保险方案的运作方式以及哪种保险方案能满足他们的需求提出很多问题。常见问题解答或基于规则的聊天机器人很难回答个性化问题。为了满足这些需求,该团队利用生成式 AI 实现了个性化帮助。
73%
用户发起了对话并参与了富有成效的对话
2 倍
与之前的号召性用语相比,点击率更高
10x
使用 WebGPU 加快推理速度
借助 Finova AI 获得个性化帮助
为了以英语和部分用户的印度原生语言提供个性化回答和更好的客户服务,Policybazaar 构建了一个名为 Finova AI 的保险助理聊天机器人,该机器人支持文本和语音。
我们为此做了很多工作。观看 2025 年 Google I/O 大会的“Web AI 在真实场景中的应用场景和策略”讲座,详细了解相关步骤。
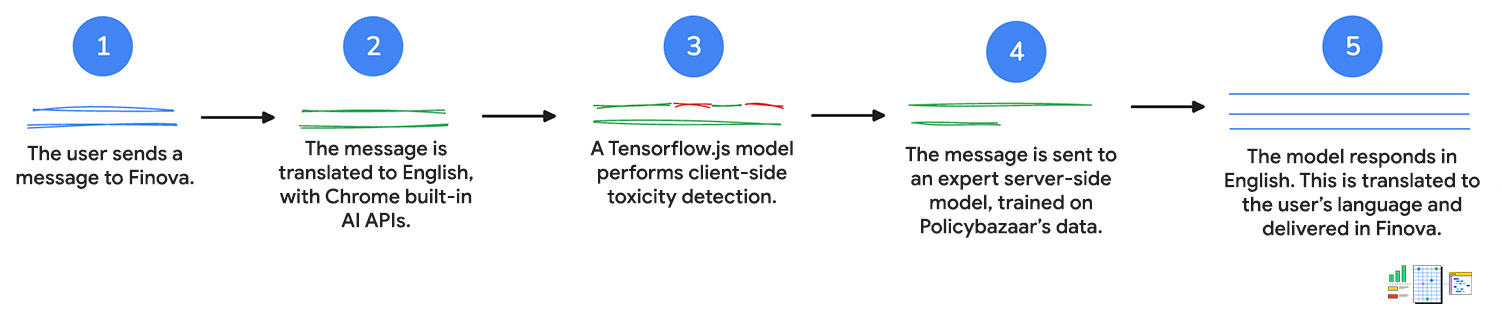
1. 用户输入
首先,客户通过文本或语音向聊天机器人发送消息。如果用户对聊天机器人说话,Web Speech API 会将语音转换为文本。
2. 翻译成英语
系统会将客户的消息发送到 Language Detector API。如果该 API 检测到印度语言,则会将输入发送到 Translator API 以翻译成英语。
这两个 API 都在客户端运行推理,这意味着用户输入内容在翻译期间不会离开设备。
3. 系统会使用毒性检测功能评估消息
客户端毒性检测模型用于评估客户的输入内容是否包含不当或攻击性字词。如果存在,系统会提示客户重新表述消息。如果消息包含有害语言,系统将不会继续执行下一步。
这有助于保持尊重对话,以便客户服务人员在必要时进行审核和跟进。
4. 向服务器发送请求
然后,系统会将经过翻译的查询传递给基于 Policybazaar 数据训练的服务器端模型,并返回对相应问题的英语回答。
客户可以获得个性化的解答和建议,以及有关产品的更复杂问题的解答。
5. 翻译成客户的语言
Translator API 用于翻译初始查询,并将查询翻译回 Language Detector API 检测到的客户语言。再次强调,这些 API 在客户端运行,因此所有工作都在用户设备上完成。这意味着,客户可以用自己的主要语言获取帮助,非英语人士也能使用聊天机器人。
混合架构
Finova AI 可在桌面平台和移动平台上运行,依靠多个模型生成最终结果。Policybazaar 构建了一种混合架构,其中部分解决方案在客户端运行,部分解决方案在服务器端运行。
无论您只使用一个模型还是多个模型,都可能出于多种原因而想要实现混合架构。
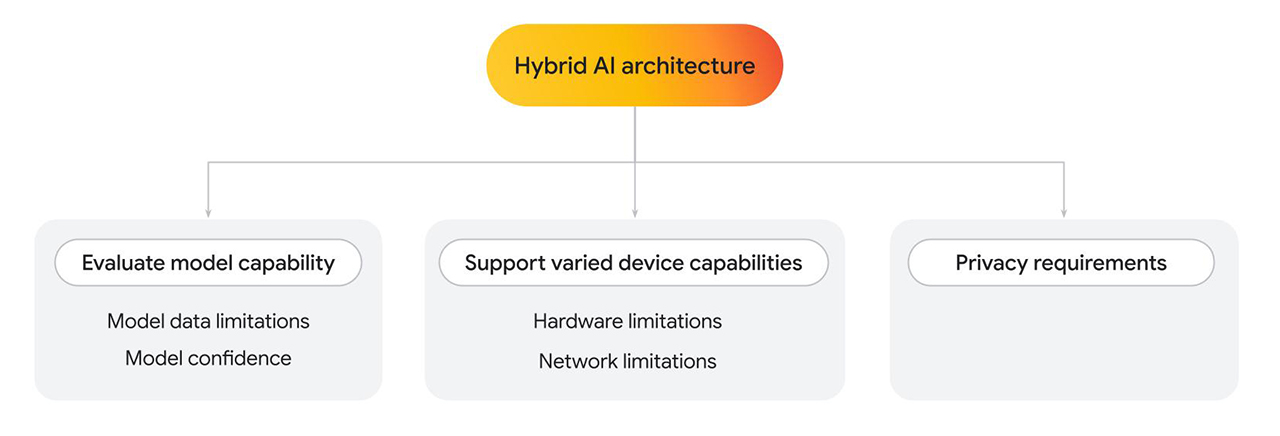
- 评估客户端模型功能。在需要时回退到服务器端。
- 模型数据限制:语言模型的大小差异很大,这也决定了其特定功能。例如,假设用户询问与您提供的服务相关的个人问题。如果客户端模型经过了特定领域的训练,或许可以回答该问题。不过,如果无法满足要求,您可以回退到服务器端实现,该实现是基于更复杂、更大的数据集训练的。
- 模型置信度:在分类模型(例如内容审核或欺诈检测)中,客户端模型可能会输出较低的置信度分数。在这种情况下,您可能需要回退到更强大的服务器端模型。
- 支持各种设备功能。
- 硬件限制:理想情况下,所有用户都应能够使用 AI 功能。实际上,用户使用各种各样的设备,并且并非所有设备都支持 AI 推理。如果设备无法支持客户端推理,您可以回退到服务器。通过这种方法,您可以提高功能的可访问性,同时尽可能降低费用和延迟时间。
- 网络限制:如果用户处于离线状态或网络不稳定,但在浏览器上有缓存的模型,您可以在客户端运行该模型。
- 隐私权要求。
- 您可能对应用有严格的隐私权要求。例如,如果用户体验流程的某个部分需要使用个人信息或人脸检测进行身份验证,请选择使用客户端模型在设备上处理数据,并将验证输出(例如通过或失败)发送到服务器端模型以执行后续步骤。
对于需要低延迟时间、高性价比和隐私保护的 Policybazaar,我们采用了客户端解决方案。当需要使用基于自定义数据训练的更复杂的模型时,则使用服务器端解决方案。
下面,我们来详细了解一下客户端模型实现。
客户端毒性检测
消息翻译后,客户的消息会传递给在桌面设备和移动设备上运行的客户端 TensorFlow.js 毒性检测模型。由于转写内容会转发给人工客服人员进行跟进,因此请务必避免使用粗俗字眼。系统会先在用户设备上分析消息,然后再将其发送到服务器,最后由人工客服人员进行处理。
此外,客户端分析还允许移除敏感信息。保护用户隐私是我们最重视的一项工作,而客户端推理有助于实现这一点。
每条消息都需要完成几个步骤。开启毒性检测后,除了语言检测和翻译之外,每条消息都需要多次往返服务器。通过在客户端执行这些任务,Policybazaar 可以显著降低预计的功能费用。
Policybazaar 从 WebGL 改用 WebGPU 后端(适用于受支持的浏览器),推理时间缩短了 10 倍。用户收到的反馈更快,可以更快地修改消息,从而提高互动度和客户满意度。
// Create an instance of the toxicity model.
const createToxicityModelInstance = async () => {
try {
//use WebGPU backend if available
if (navigator.gpu) {
await window.tf.setBackend('webgpu');
await window.tf.ready();
}
return await window.toxicity.load(0.9).then(model => {
return model;
}).catch(error => {
console.log(error);
return null;
});
} catch (er) {
console.error(er);
}
}
互动度和点击率较高
通过将多个模型与 Web API 相结合,Policybazaar 成功延长了客户服务时间。此功能的有限发布阶段的初步结果表明,用户互动度很高。
73% 打开聊天机器人的用户都参与了长达几分钟的多问题对话,因此跳出率较低。此外,试点计划还表明,这种新的客户帮助号召性用语的点击率提高了 2 倍,这表明客户成功与 Finova 互动,解决了他们的疑问。此外,将客户端毒性检测切换到 WebGPU 后端后,推理速度提高了 10 倍,从而缩短了用户反馈时间。
73%
用户发起了对话并参与了富有成效的对话
2 倍
与之前的号召性用语相比,点击率更高
10x
使用 WebGPU 加快推理速度
资源
如果您有兴趣使用客户端 AI 扩展您自己的 Web 应用的功能,请执行以下操作:
- 了解如何实现客户端毒性检测。
- 查看一系列客户端 AI 演示。
- 不妨了解 Mediapipe 和 Transformers.js。您可以使用预训练模型,并使用 JavaScript 将其集成到应用中。
- Chrome 开发者专区中的 AI 集合提供了有关在 Chrome 和其他平台上支持 AI 的技术的资源、最佳实践和最新动态。
- 了解 2025 年 I/O 大会上 Web AI 的真实案例。