
Bevor Sie KI-Funktionen nutzen, müssen Sie die Plattform auswählen, auf der sie gehostet werden. Ihre Entscheidung wirkt sich auf die Geschwindigkeit, die Kosten, die Skalierbarkeit und die Vertrauenswürdigkeit Ihres KI-Systems aus. Sie haben folgende Optionen zur Auswahl:
- Clientseitige KI: Wird direkt im Browser ausgeführt. Das bedeutet, dass Daten privat auf dem Gerät des Nutzers bleiben können und es keine Netzwerklatenz gibt. Damit clientseitige KI gut funktioniert, sind jedoch sehr spezifische, genau definierte Anwendungsfälle erforderlich.
- Serverseitige KI: Wird in der Cloud ausgeführt. Es ist sehr leistungsfähig und skalierbar, aber in Bezug auf Latenz und Kosten teurer.
Jede Option hat Vor- und Nachteile. Die richtige Einrichtung hängt von Ihrem Anwendungsfall, den Fähigkeiten Ihres Teams und Ihren Ressourcen ab. Sie könnten beispielsweise ein Tool zur Zusammenfassung anbieten, das lokal ausgeführt wird, damit Nutzer persönliche Fragen stellen können, ohne personenidentifizierbare Informationen verwalten zu müssen. Ein Kundenservicemitarbeiter könnte jedoch hilfreichere Antworten geben, wenn er ein cloudbasiertes Modell verwendet, das Zugriff auf eine große Datenbank mit Ressourcen hat.
In diesem Modul erfahren Sie, wie Sie Folgendes tun:
- Vergleichen Sie die Vor- und Nachteile von client- und serverseitiger KI.
- Wählen Sie eine Plattform aus, die zu Ihrem Anwendungsfall und den Fähigkeiten Ihres Teams passt.
- Entwickeln Sie Hybridsysteme, die KI auf dem Client und Server bieten, damit Ihr Produkt mit Ihnen wachsen kann.
Optionen ansehen
Bei der Bereitstellung von KI-Plattformen sind zwei Hauptachsen zu berücksichtigen. Zur Auswahl stehen:
- Wo wird das Modell ausgeführt?: Wird es clientseitig oder serverseitig ausgeführt?
- Anpassbarkeit: Wie viel Kontrolle haben Sie über das Wissen und die Funktionen des Modells? Wenn Sie das Modell steuern können, d. h. die Modellgewichte ändern können, können Sie das Verhalten an Ihre spezifischen Anforderungen anpassen.
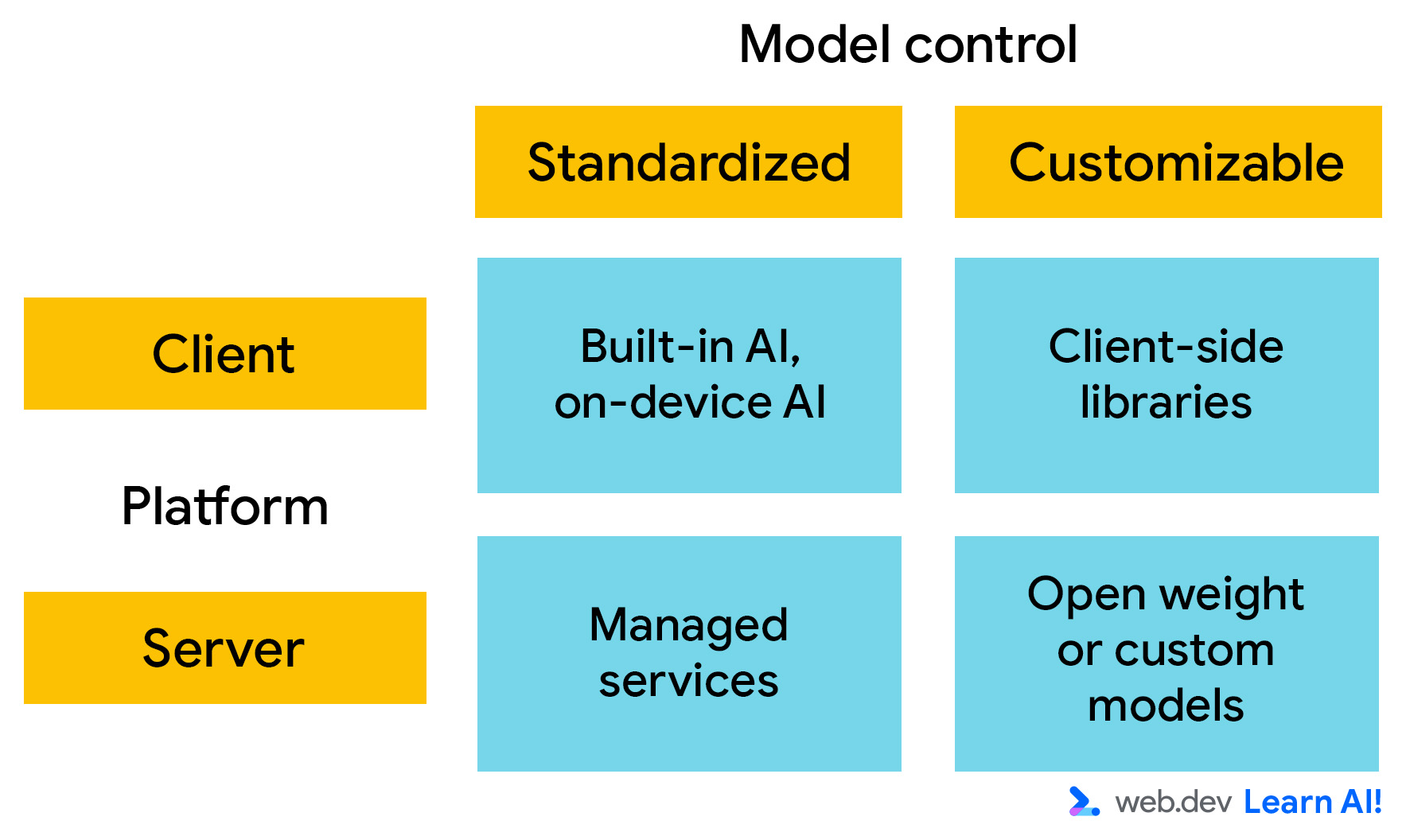
Clientseitige KI
Clientseitige KI wird im Browser ausgeführt und die Berechnungen erfolgen lokal auf dem Gerät des Nutzers. Sie müssen keine Rechenleistung für die Inferenz bereitstellen und die Daten verbleiben auf dem Gerät des Nutzers. Das macht es schnell, privat und geeignet für einfache, interaktive Anwendungen.
Clientseitige Modelle sind jedoch in der Regel recht klein, was ihre Fähigkeiten und Leistung einschränken kann. Sie eignen sich am besten für hochspezialisierte Aufgaben wie die Erkennung schädlicher Inhalte oder die Sentimentanalyse. Häufig handelt es sich dabei um Aufgaben mit vorausschauender KI mit einem begrenzten Ausgabebereich.
Dazu haben Sie zwei Möglichkeiten:
- Integrierte KI: In Browser wie Google Chrome und Microsoft Edge werden KI-Modelle integriert. Sie sind über JavaScript-Aufrufe zugänglich und müssen weder eingerichtet noch gehostet werden. Sobald das Modell heruntergeladen wurde, kann es von allen Websites aufgerufen werden, die es verwenden.
- Benutzerdefinierte Modelle: Sie können clientseitige Bibliotheken wie Transformers.js und MediaPipe verwenden, um Modelle in Ihre Anwendung einzubinden. Das bedeutet, dass Sie die Modellgewichte steuern können. Das bedeutet aber auch, dass jeder Nutzer Ihrer Website Ihr benutzerdefiniertes Modell herunterladen muss. Selbst die kleinsten KI-Modelle sind im Kontext einer Website groß.
Serverseitige KI
Bei serverseitiger KI ruft Ihre Webanwendung eine API auf, um Eingaben an das KI-Modell zu senden und dessen Ausgaben zu empfangen. Diese Einrichtung unterstützt größere, komplexere Modelle und ist unabhängig von der Nutzerhardware.
Die beiden Kategorien für serverseitige KI sind:
- Verwaltete Dienste: Diese Modelle werden von einem Drittanbieter in Rechenzentren gehostet, z. B. Gemini 3 und GPT-5. Der Modelleigentümer stellt eine API für den Zugriff auf das Modell bereit. Sie können also modernste Modelle mit minimalem Aufwand einsetzen. Sie eignen sich ideal für schnelles Prototyping, offene Gespräche und allgemeine Schlussfolgerungen. Die Skalierung eines verwalteten Dienstes kann jedoch teuer sein.
- Selbst gehostete Modelle: Sie können Modelle mit offenen Gewichten wie Gemma oder Llama auf Ihrer eigenen Infrastruktur oder in einem verwalteten Container wie Vertex AI oder Hugging Face Inference bereitstellen. So können Sie von der Vorabtrainingsphase des Modells profitieren, die vom Modellentwickler durchgeführt wurde, behalten aber die Kontrolle über das Modell, die Daten für das Feinabstimmungstraining und die Leistung.
Anfangsplattform auswählen
Sehen Sie sich die architektonischen Merkmale der KI-Plattformen an und analysieren Sie die Kompromisse, um über die Ersteinrichtung zu entscheiden.
Architekturanforderungen definieren
Bei jeder Entscheidung müssen Sie Kompromisse eingehen. Sehen Sie sich die wichtigsten Merkmale an, die die Kosten und den Wert Ihrer KI-Plattform bestimmen:
- Modellleistung: Wie gut das Modell ohne Optimierung für eine Vielzahl von Nutzern und Aufgaben funktioniert. Das hängt oft mit der Modellgröße zusammen.
- Anpassungsmöglichkeiten: Das Ausmaß, in dem Sie das Verhalten und die Architektur des Modells optimieren, ändern oder steuern können.
- Genauigkeit: Die allgemeine Qualität und Zuverlässigkeit der Vorhersagen oder Generierungen des Modells.
- Datenschutz: Das Ausmaß, in dem Nutzerdaten lokal und unter Nutzerkontrolle bleiben.
- Fixkosten: Die wiederkehrenden Ausgaben, die für den Betrieb des KI-Systems unabhängig von der Nutzung erforderlich sind, einschließlich der Bereitstellung und Wartung der Infrastruktur.
- Kosten pro Anfrage: Die zusätzlichen Kosten für jede eingehende Anfrage.
- Kompatibilität: Wie weit funktioniert der Ansatz browser-, geräte- und umgebungsübergreifend ohne Fallback-Logik?
- Nutzerfreundlichkeit: Ob Nutzer zusätzliche Schritte ausführen müssen, um das KI-System zu verwenden, z. B. ein Modell herunterladen.
- Entwicklerfreundlichkeit: Wie schnell und einfach die meisten Entwickler das Modell bereitstellen, einbinden und verwalten können, ohne spezielle KI-Expertise.
In der folgenden Tabelle finden Sie ein Beispiel für Schätzungen, wie gut die einzelnen Plattformen für die einzelnen Kriterien abschneiden. Dabei ist 1 der niedrigste und 5 der höchste Wert.
| Kriterien | Client | Server | ||
| Integrierte KI oder auf dem Gerät | Benutzerdefiniertes Modell | Verwalteter Dienst | Selbst gehostetes Modell | |
| Modellleistung |
Warum 2 Sterne für die Leistungsfähigkeit des Modells?Die integrierte und On-Device-KI verwendet kleine, vorinstallierte Browsermodelle, die für bestimmte, aufgabenspezifische Funktionen optimiert sind und nicht für offene Unterhaltungen oder Schlussfolgerungen. |
Warum 3 Sterne für die Leistungsfähigkeit des Modells?Benutzerdefinierte clientseitige Bibliotheken bieten mehr Flexibilität als integrierte KI, aber Sie sind weiterhin durch Downloadgröße, Speicherlimits und Nutzerhardware eingeschränkt. |
Warum 4 Sterne für die Modellleistung?Mit verwalteten Diensten und Self-Hosting haben Sie Zugriff auf große, hochmoderne Modelle, die in der Lage sind, komplexe Schlussfolgerungen zu ziehen, lange Kontexte zu verarbeiten und ein breites Aufgabenspektrum abzudecken. |
|
| Anpassbarkeit |
Warum nur ein Stern für die Anpassbarkeit?Bei integrierten Modellen ist kein Zugriff auf Modellgewichte oder Trainingsdaten möglich. Das Verhalten von Gemini kann hauptsächlich durch Prompt Engineering angepasst werden. |
Warum 5 Sterne für Anpassbarkeit?Mit dieser Option haben Sie die Kontrolle über die Modellauswahl und die Gewichte. Viele clientseitige Bibliotheken ermöglichen auch das Feinabstimmen und Trainieren von Modellen. |
Warum nur ein Stern für die Anpassbarkeit?Verwaltete Dienste stellen leistungsstarke Modelle zur Verfügung, bieten aber nur minimale Kontrolle über ihr internes Verhalten. Die Anpassung ist in der Regel auf Prompts und Eingabekontext beschränkt. |
Warum 5 Sterne für Anpassbarkeit?Bei selbst gehosteten Modellen haben Sie die vollständige Kontrolle über Modellgewichte, Trainingsdaten, Feinabstimmung und Bereitstellungskonfiguration. |
| Genauigkeit |
Warum 2 Sterne für die Richtigkeit?Die Genauigkeit integrierter Modelle ist für Aufgaben mit einem klaren Fokus ausreichend, aber die begrenzte Modellgröße und Generalisierung verringern die Zuverlässigkeit bei komplexen oder differenzierten Eingaben. |
Warum 3 Sterne für die Richtigkeit?Die Genauigkeit benutzerdefinierter clientseitiger Modelle kann bei der Modellauswahl verbessert werden. Die Leistung ist jedoch weiterhin durch die Modellgröße, die Quantisierung und die Hardwarevariabilität des Clients eingeschränkt. |
Warum 5 Sterne für Richtigkeit?Verwaltete Dienste bieten in der Regel eine relativ hohe Genauigkeit, da sie von großen Modellen, umfangreichen Trainingsdaten und kontinuierlichen Verbesserungen des Anbieters profitieren. |
Warum 4 Sterne für die Richtigkeit?Die Genauigkeit kann hoch sein, hängt aber vom ausgewählten Modell und vom Aufwand für die Optimierung ab. Die Leistung kann hinter verwalteten Diensten zurückbleiben. |
| Netzwerklatenz |
Warum 5 Sterne für die Netzwerklatenz?Die Verarbeitung erfolgt direkt auf dem Gerät des Nutzers. |
Warum 2 Sterne für die Netzwerklatenz?Es gibt einen Roundtrip zu einem Server. |
||
| Datenschutz |
Warum 5 Sterne für Datenschutz?Nutzerdaten sollten standardmäßig auf dem Gerät verbleiben, um die Offenlegung von Daten zu minimieren und die Einhaltung des Datenschutzes zu vereinfachen. |
Warum 2 Sterne für Datenschutz?Nutzereingaben müssen an externe Server gesendet werden, was das Risiko der Offenlegung von Daten und die Compliance-Anforderungen erhöht. Es gibt jedoch spezielle Lösungen, um Datenschutzprobleme zu minimieren, z. B. Private AI Compute. |
Warum 3 Sterne für Datenschutz?Die Daten unterliegen weiterhin der Kontrolle Ihrer Organisation, verlassen aber das Gerät des Nutzers und erfordern eine sichere Verarbeitung und Compliance-Maßnahmen. |
|
| Fester Preis |
Warum 5 Sterne für Festpreis?Die Modelle werden auf den vorhandenen Geräten der Nutzer ausgeführt, sodass keine zusätzlichen Infrastrukturkosten anfallen. |
Warum 5 Sterne für Festpreis?Bei den meisten APIs werden die Gebühren nutzungsbasiert berechnet. Es gibt also keine festen Kosten. |
Warum zwei Sterne für Festpreis?Zu den Fixkosten gehören Infrastruktur-, Wartungs- und Betriebskosten. |
|
| Cost-per-Request |
Warum 5 Sterne für die Kosten pro Anfrage?Da die Inferenz auf dem Gerät des Nutzers ausgeführt wird, fallen keine Kosten pro Anfrage an. |
Warum 2 Sterne für die Kosten pro Anfrage?Bei verwalteten Diensten wird in der Regel pro Anfrage abgerechnet. Die Kosten für die Skalierung können beträchtlich sein, insbesondere bei hohem Traffic-Aufkommen. |
Warum 3 Sterne für die Kosten pro Anfrage?Keine direkten Kosten pro Anfrage. Die effektiven Kosten pro Anfrage hängen von der Infrastrukturnutzung ab. |
|
| Kompatibilität |
Warum 2 Sterne für die Kompatibilität?Die Verfügbarkeit variiert je nach Browser und Gerät. Für nicht unterstützte Umgebungen sind Fallbacks erforderlich. |
Warum nur 1 Stern für die Kompatibilität?Die Kompatibilität hängt von den Hardwarefunktionen und der Laufzeitunterstützung ab, was die Reichweite auf verschiedenen Geräten einschränkt. |
Warum 5 Sterne für die Kompatibilität?Serverseitige Plattformen sind für alle Nutzer weitgehend kompatibel, da die Inferenz serverseitig erfolgt und Clients nur eine API nutzen. |
|
| Nutzerfreundlichkeit |
Warum 3 Sterne für Nutzerfreundlichkeit?Sobald die Funktion verfügbar ist, funktioniert sie in der Regel nahtlos. Für die integrierte KI ist jedoch ein anfänglicher Modelldownload und Browserunterstützung erforderlich. |
Warum nur 2 Sterne für Nutzerfreundlichkeit?Nutzer können aufgrund von Downloads oder nicht unterstützter Hardware mit Verzögerungen rechnen. |
Warum 4 Sterne für Nutzerfreundlichkeit?Funktioniert sofort, ohne dass Downloads oder Geräteanforderungen erforderlich sind, und bietet so eine reibungslose Nutzererfahrung. Bei einer schlechten Netzwerkverbindung kann es jedoch zu Verzögerungen kommen. |
|
| Entwicklerfreundlichkeit |
Warum 5 Sterne für Entwicklerfreundlichkeit?Die integrierte KI erfordert nur eine minimale Einrichtung, keine Infrastruktur und wenig KI-Fachwissen. Sie lässt sich also einfach integrieren und verwalten. |
Warum nur 2 Sterne für Entwicklerfreundlichkeit?Erfordert die Verwaltung von Modellen, Runtimes, Leistungsoptimierung und Kompatibilität auf verschiedenen Geräten. |
Warum 4 Sterne für Entwicklerfreundlichkeit?Verwaltete Dienste vereinfachen die Bereitstellung und Skalierung. Sie erfordern jedoch weiterhin eine API-Integration, Kostenmanagement und Prompt Engineering. |
Warum nur einen Stern für Entwicklerfreundlichkeit?Eine benutzerdefinierte serverseitige Bereitstellung erfordert erhebliches Fachwissen in den Bereichen Infrastruktur, Modellverwaltung, Monitoring und Optimierung. |
| Wartungsaufwand |
Warum 4 Sterne für Wartungsaufwand?Browser kümmern sich um Modellupdates und ‑optimierung, aber Entwickler müssen sich an die sich ändernde Verfügbarkeit anpassen. |
Warum 2 Sterne für Wartungsaufwand?Erfordert fortlaufende Updates für Modelle, Leistungsoptimierung und Kompatibilität, da sich Browser und Geräte weiterentwickeln. |
Warum 5 Sterne für Wartungsaufwand?Die Wartung wird vom Anbieter übernommen. |
Warum 2 Sterne für Wartungsaufwand?Erfordert kontinuierliche Wartung, einschließlich Modellupdates, Infrastrukturverwaltung, Skalierung und Sicherheit. |
Kompromisse analysieren
Um den Entscheidungsprozess zu veranschaulichen, fügen wir Example Shoppe, einer mittelgroßen E-Commerce-Plattform, ein weiteres Feature hinzu. Sie möchten die Kosten für den Kundenservice außerhalb der Geschäftszeiten senken und entscheiden sich daher, einen KI-basierten Assistenten zu entwickeln, der Nutzerfragen zu Bestellungen, Rückgaben und Produkten beantwortet.
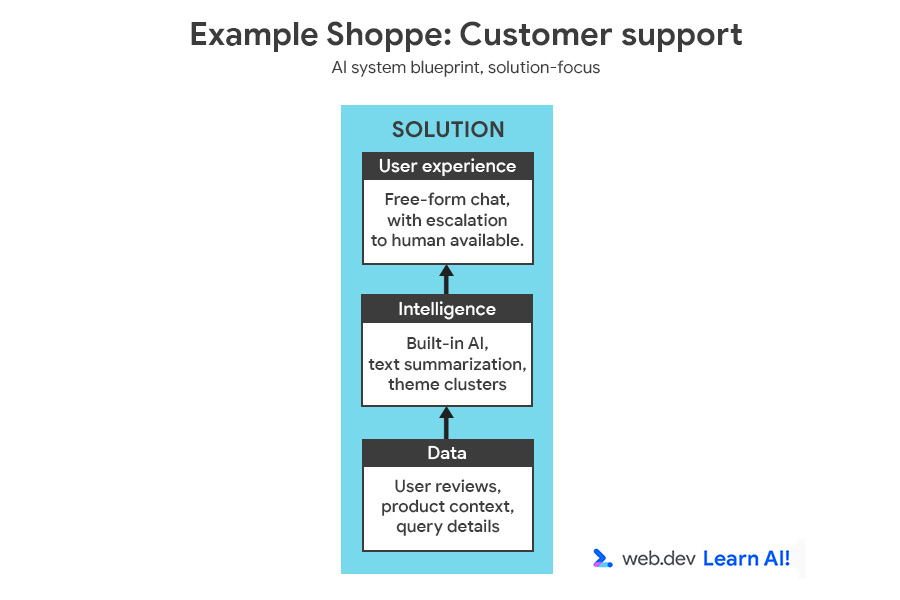
Sie können sich den vollständigen Blueprint für das KI-System mit der Problemstellung und der Lösung ansehen.
{kind=link}
Analysieren Sie das Szenario aus zwei Perspektiven: Anforderungen des Anwendungsfalls und geschäftliche oder teambezogene Einschränkungen.
| Anforderung | Analyse | Kriterien | Auswirkungen |
| Hohe Genauigkeit und Vielseitigkeit | Nutzer stellen verschiedene komplexe Fragen zu Bestellungen, Produkten und Rückgaben. | Modellleistung, ‑genauigkeit | Erfordert ein Large Language Model (LLM). |
| Datenpräzision | Es muss Fragen zu Unternehmensdaten, Produkten und Richtlinien beantworten können. | Anpassbarkeit | Erfordert die Aufnahme von Daten, z. B. RAG, aber kein Modell-Finetuning. |
| Anforderung | Analyse | Kriterien | Auswirkungen |
| Nutzerbasis | Hunderttausende von Nutzern | Skalierbarkeit, Kompatibilität | Erfordert eine Architektur, die hohen, zuverlässigen Traffic verarbeiten kann. |
| Fokus nach der Einführung | Das Team wird nach der Einführung von Version 1 an anderen Projekten arbeiten. | Wartungsaufwand | Sie benötigen eine Lösung, die nur minimalen Wartungsaufwand erfordert. |
| Expertise des Teams | Erfahrene Webentwickler mit begrenzten KI‑/ML-Kenntnissen | Entwicklerfreundlichkeit | Die Lösung muss ohne spezielle KI-Kenntnisse einfach bereitgestellt und integriert werden können. |
Nachdem Sie Ihre Kriterien priorisiert haben, können Sie in der Tabelle zur Schätzung von Kompromissen nachsehen, welche Plattform Ihren wichtigsten Kriterien entspricht:
Aus dieser Aufschlüsselung geht klar hervor, dass Sie serverseitige KI und wahrscheinlich einen verwalteten Dienst verwenden sollten. So erhalten Sie ein vielseitiges Modell für komplexe Kundenfragen. Der Wartungs- und Entwicklungsaufwand wird minimiert, da Infrastruktur, Modellqualität und Betriebszeit an den Anbieter ausgelagert werden.
Die Anpassungsmöglichkeiten sind zwar begrenzt, aber für ein Webentwicklungsteam mit wenig Erfahrung im Bereich Modellentwicklung ist das ein lohnender Kompromiss.
Mit einer RAG-Einrichtung (Retrieval-Augmented Generation) können Sie dem Modell zur Inferenzzeit den relevanten Kontext bereitstellen.
Hybride KI
Ausgereifte KI-Systeme werden selten auf einer einzelnen Plattform oder mit einem Modell ausgeführt. Stattdessen verteilen sie KI-Arbeitslasten, um die Kompromisse zu optimieren.
Chancen für hybride KI erkennen
Nach dem Launch sollten Sie Ihre Anforderungen anhand von realen Daten und Feedback verfeinern. In unserem Beispiel, Example Shoppe, warten Sie einige Monate, um die Ergebnisse zu analysieren. Sie stellen Folgendes fest:
- Etwa 80% der Anfragen sind Wiederholungen („Wo ist meine Bestellung?“, „Wie kann ich das zurückgeben?“). Das Senden dieser Anfragen an einen verwalteten Dienst verursacht viel Aufwand und Kosten.
- Nur 20% der Anfragen erfordern eine ausführlichere Argumentation und eine offene, interaktive Unterhaltung.
Ein schlankes lokales Modell könnte Nutzereingaben klassifizieren und Routineanfragen wie „Welche Rückgabebedingungen gelten?“ beantworten. Sie können komplexe, seltene oder mehrdeutige Fragen an das serverseitige Modell weiterleiten.
Durch die Implementierung von KI auf Server- und Clientseite können Sie Kosten und Latenz reduzieren und gleichzeitig bei Bedarf auf leistungsstarke Schlussfolgerungen zugreifen.
Arbeitslast verteilen
Wenn Sie dieses Hybridsystem für Example Shoppe erstellen möchten, sollten Sie zuerst das Standardsystem definieren. In diesem Fall ist es am besten, clientseitig zu beginnen. Die Anwendung sollte in zwei Fällen an die serverseitige KI weitergeleitet werden:
- Kompatibilitätsbasierter Fallback: Wenn das Gerät oder der Browser des Nutzers die Anfrage nicht verarbeiten kann, sollte ein Fallback zum Server erfolgen.
- Eskalierung basierend auf der Funktion: Wenn die Anfrage zu komplex oder zu offen für das clientseitige Modell ist (gemäß vordefinierten Kriterien), sollte sie an ein größeres serverseitiges Modell eskaliert werden. Sie könnten ein Modell verwenden, um die Anfrage als häufig (Aufgabe wird clientseitig ausgeführt) oder ungewöhnlich (Anfrage wird an das serverseitige System gesendet) zu klassifizieren. Wenn das clientseitige Modell beispielsweise feststellt, dass sich die Frage auf ein ungewöhnliches Problem bezieht, z. B. eine Erstattung in einer anderen Währung.
Flexibilität führt zu mehr Komplexität
Wenn Sie Arbeitslasten auf zwei Plattformen verteilen, sind Sie flexibler, aber es wird auch komplexer:
- Orchestrierung: Zwei Ausführungsumgebungen bedeuten mehr bewegliche Teile. Sie benötigen Logik für Routing, Wiederholungsversuche und Fallbacks.
- Versionsverwaltung: Wenn Sie dasselbe Modell auf verschiedenen Plattformen verwenden, muss es in beiden Umgebungen kompatibel bleiben.
- Prompt-Engineering und Kontext-Engineering: Wenn Sie auf jeder Plattform unterschiedliche Modelle verwenden, müssen Sie für jedes Modell Prompt-Engineering durchführen.
- Monitoring: Logs und Messwerte sind aufgeteilt und erfordern zusätzlichen Aufwand für die Vereinheitlichung.
- Sicherheit: Sie verwalten zwei Angriffsflächen. Sowohl lokale als auch Cloud-Endpunkte müssen gehärtet werden.
Das ist ein weiterer Kompromiss, den Sie in Betracht ziehen sollten. Wenn Sie ein kleines Team haben oder eine nicht unbedingt erforderliche Funktion entwickeln, sollten Sie diese Komplexität möglicherweise nicht hinzufügen.
Wichtige Erkenntnisse
Ihre Plattformauswahl wird sich wahrscheinlich weiterentwickeln. Beginnen Sie mit dem Anwendungsfall, richten Sie sich nach den Erfahrungen und Ressourcen Ihres Teams und iterieren Sie, wenn sowohl Ihr Produkt als auch Ihre KI-Reife wachsen. Ihre Aufgabe ist es, die richtige Mischung aus Geschwindigkeit, Datenschutz und Kontrolle für Ihre Nutzer zu finden und dann flexibel zu entwickeln. So können Sie sich an sich ändernde Anforderungen anpassen und von zukünftigen Plattform- und Modellupdates profitieren.
Ressourcen
- Da die Auswahl von Plattform und Modell voneinander abhängt, finden Sie hier weitere Informationen zur Modellauswahl.
- Informationen zu Hybrid- und clientseitiger KI
Wissen testen
Was sind die beiden wichtigsten Überlegungen bei der Auswahl einer KI-Plattform für Ihre Anwendung?
Wann ist ein serverseitig verwalteter Dienst wie Gemini Pro die beste Wahl für Ihre Plattform?
Was ist der Hauptvorteil der Implementierung eines hybriden KI-Systems?