
Vorhersage-KI (oder analytische KI) ist eine Sammlung von Algorithmen, mit denen Sie vorhandene Daten analysieren und vorhersagen können, was als Nächstes wahrscheinlich passieren wird. Anhand historischer Muster lernen prädiktive KI-Modelle verschiedene Analyseaufgaben, die Nutzern helfen, ihre Daten zu verstehen:
- Klassifizierung: Gruppieren von Elementen in vordefinierten Kategorien basierend auf Mustern in den Daten. Ein Onlineshop kann Besucher beispielsweise nach Intention (Recherche, Kauf, Retouren) klassifizieren, um seine Empfehlungen entsprechend anzupassen.
- Regression: Numerische Werte wie die Interaktionsrate, die Sitzungsdauer oder die Conversion-Wahrscheinlichkeit vorhersagen.
- Empfehlung: Schlagen Sie Elemente vor, die für einen bestimmten Nutzer oder Kontext am relevantesten sind. Denken Sie an „Nutzer wie Sie haben sich auch angesehen“ oder „Empfohlene Tutorials basierend auf Ihrem Fortschritt“.
- Prognosen und Anomalieerkennung: Das Modell sagt zukünftige Ereignisse wie eine Traffic-Spitze voraus oder erkennt ungewöhnliches Verhalten wie Zahlungsanomalien oder Betrug.
Einige Produkte basieren vollständig auf prädiktiver KI, z. B. Tools zur Musikerkennung. In anderen Fällen verbessert vorausschauende KI eine deterministische Erfahrung, z. B. auf einer Streaming-Website mit personalisierten Empfehlungen. Vorhersagende KI kann auch ein leistungsstarker interner Enabler sein: Sie können damit Produkt- und Nutzerdaten analysieren, um Erkenntnisse zu gewinnen und fundiertere nächste Schritte zu planen.
Der Predictive AI-Zyklus
Die Entwicklung eines KI-Systems für Vorhersagen folgt einem iterativen Zyklus: Definieren Sie Ihre Möglichkeiten, bereiten Sie Ihre Daten vor, trainieren Sie das Modell, bewerten Sie das Modell und stellen Sie das Modell bereit.
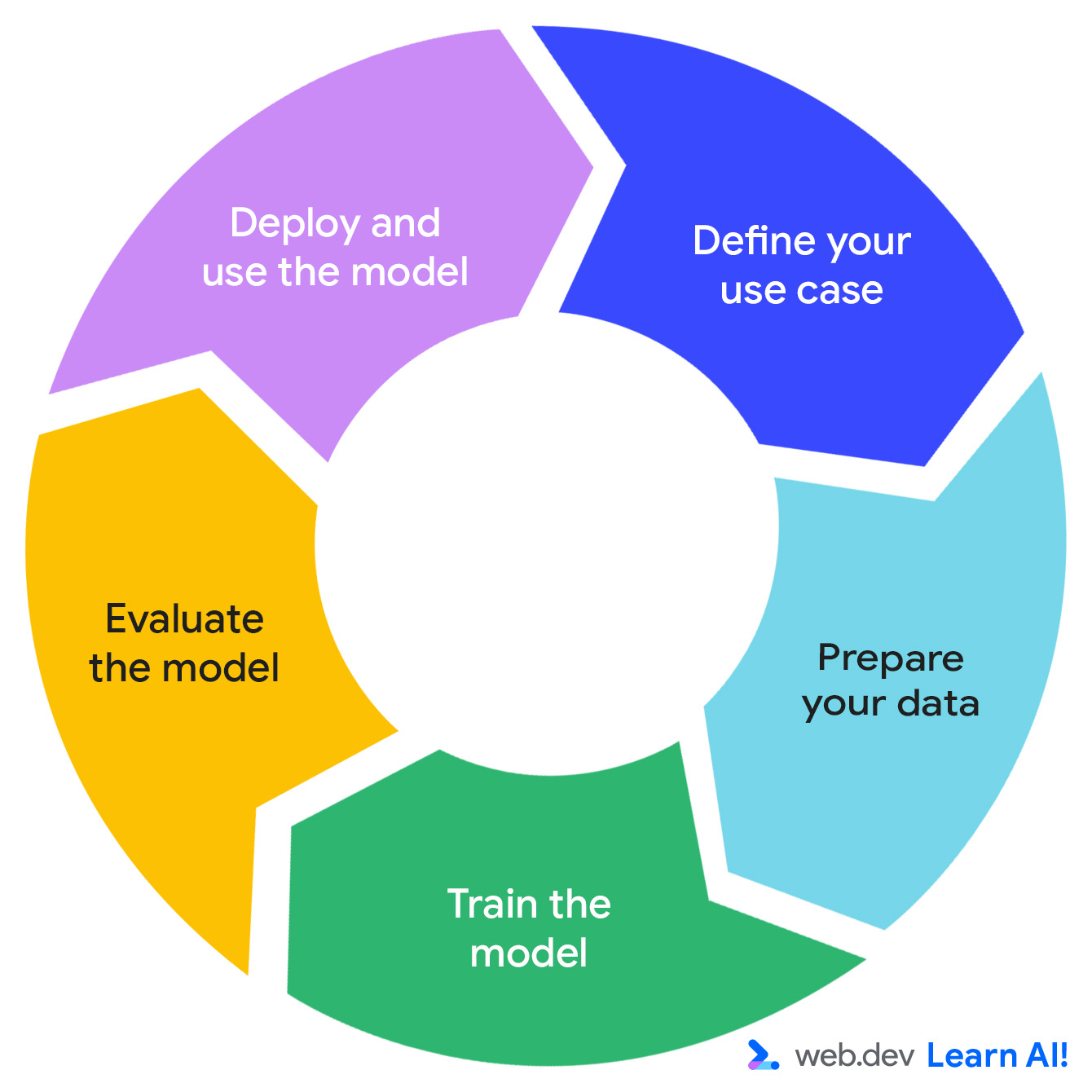
Stellen Sie sich vor, Sie arbeiten an einer abo-basierten Produktivitäts-App namens Do All The Things. Sie erheben bereits Nutzungsdaten wie Seitenaufrufe, Sitzungslänge, Funktionsnutzung und Aboverlängerungen. Nun möchten Sie mehr verwertbare Informationen aus den Daten ziehen. So durchlaufen Sie den prädiktiven KI-Zyklus.
Anwendungsfall definieren
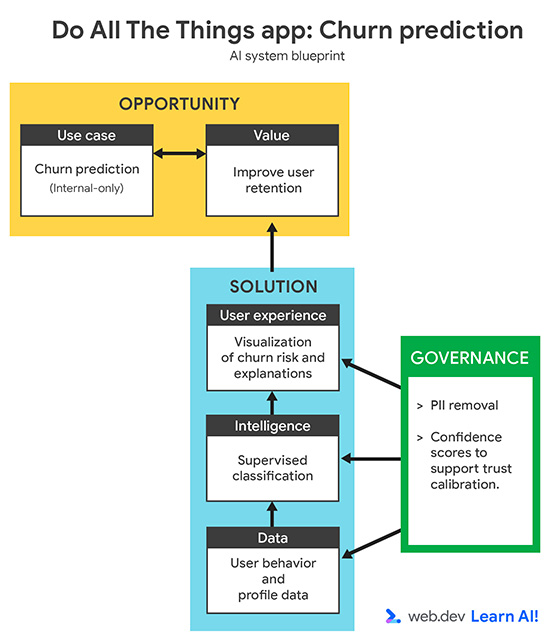
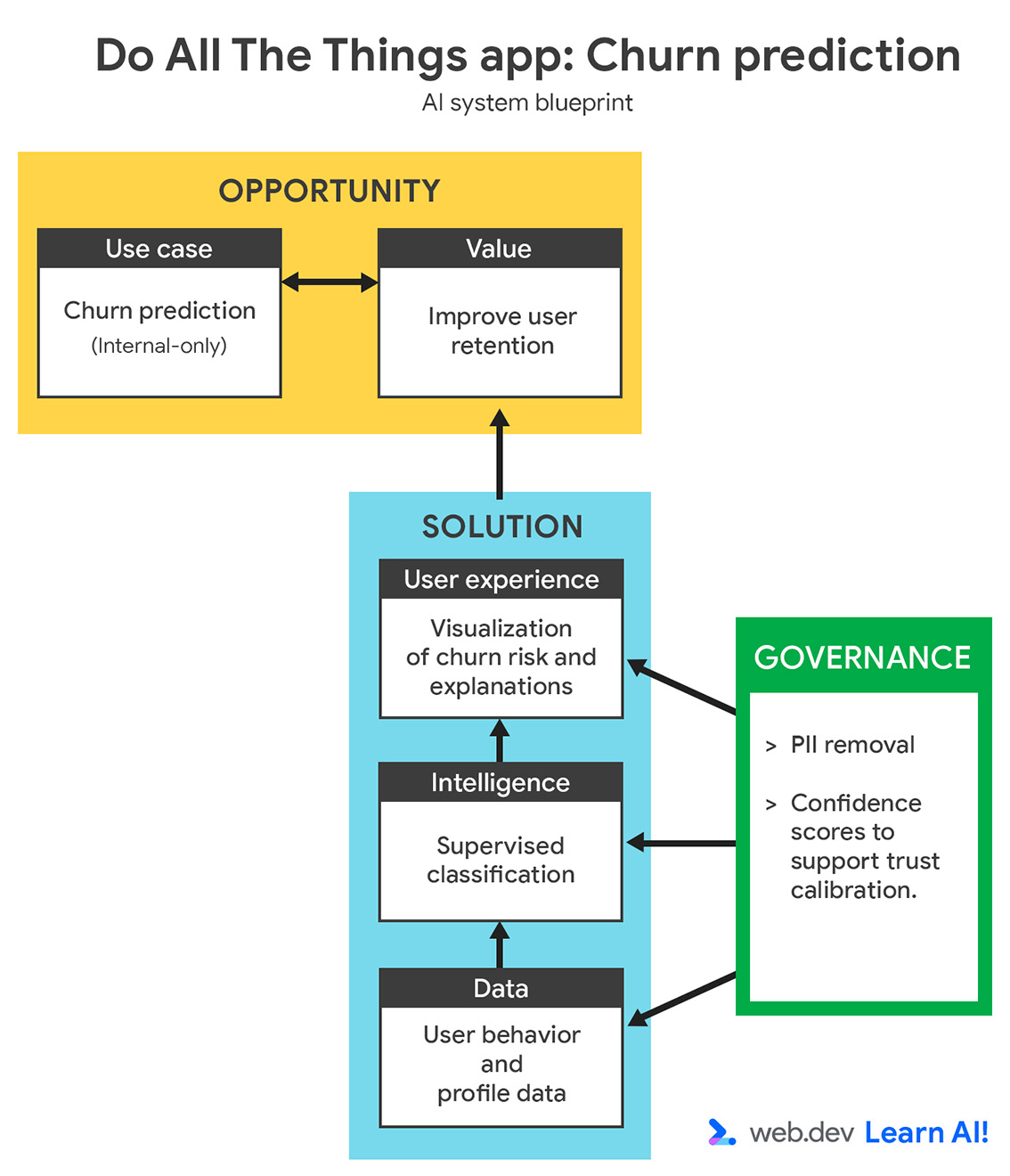{kind=link}
Ihre Abwanderungsrate ist in den letzten drei Monaten gestiegen. Anstatt erst zu reagieren, nachdem Nutzer gekündigt haben, möchten Sie mit vorausschauender KI Nutzer identifizieren, die wahrscheinlich kündigen werden, bevor sie es tun. Ziel ist es, Ihr Customer Success-Team mit Frühwarnsignalen zu unterstützen, damit es gezielte, proaktive Maßnahmen ergreifen kann, um gefährdete Nutzer zu binden.
Wenn Sie einen KI-Anwendungsfall für Vorhersagen definieren, sollten Sie zuerst prüfen, ob die Frage mit Daten beantwortet werden kann. Das können Daten sein, die Sie bereits erhoben haben, oder Daten, die Sie in Zukunft realistischerweise erheben könnten. Dieser Schritt erfordert oft die Zusammenarbeit mit Fachexperten, z. B. aus den Bereichen Kundenservice, Wachstum oder Marketing, damit die Vorhersage sowohl aussagekräftig als auch umsetzbar ist.
Eine gute Problemdefinition sollte Folgendes enthalten:
- Ziel: Welches Geschäftsergebnis möchten Sie beeinflussen? Sie möchten beispielsweise die Abwanderung reduzieren, indem Sie die proaktive Kontaktaufnahme aktivieren.
- Eingabedaten: Aus welchen bisherigen Signalen lernt das Modell? Sie geben beispielsweise Nutzungsmuster, Plantypen und Supportinteraktionen an.
- Ausgabe: Was wird vom Modell generiert? Sie möchten beispielsweise, dass das Modell für jeden Nutzer eine Abwanderungswahrscheinlichkeit berechnet.
- Nutzer: Wer verwendet die Vorhersage oder handelt auf Grundlage der Vorhersage? Diese Daten sind beispielsweise für Customer Success Manager vorgesehen.
- Erfolgskriterien: Wie messen Sie die Wirkung? Sie können beispielsweise die Kundenbindungsrate messen, um festzustellen, ob Sie die Abwanderung reduziert haben.
Wenn Sie diese Details von Anfang an berücksichtigen, können Sie eine häufige Falle vermeiden: ein benutzerdefiniertes Modell zu erstellen, das technisch einwandfrei ist, aber nie verwendet wird.
Daten vorbereiten
Damit Ihr Modell nützliche Lernsignale erhält, müssen Sie Ihre Verlaufsdaten mit idealen Vorhersagen kennzeichnen. Labeln Sie Nutzer von Do All The Things als „abgewandert“ oder „nicht abgewandert“.
Arbeiten Sie als Nächstes mit Ihrem Customer Success-Team zusammen, um herauszufinden, welche Verhaltensmerkmale für die Churn-Vorhersage am relevantesten sind. Beschränken Sie Ihr Dataset auf diese wichtigen Funktionen und entfernen Sie unnötige Felder, damit Ihr Modell nicht mit Rauschen umgehen muss. Denken Sie daran, den Datenschutz zu berücksichtigen. Entfernen Sie personenidentifizierbare Informationen wie Namen oder E‑Mail-Adressen und speichern Sie nur aggregierte Verhaltensdaten.
Die folgende Tabelle zeigt einen Auszug aus dem resultierenden Dataset:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | Premium | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | Google AI Pro | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | Kostenlos | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | Premium | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | Google AI Pro | 4.2 | 2 | 1 | 3 | 1 |
So erhält Ihr Modell saubere numerische und kategoriale Eingaben (z. B. plan_type oder avg_session_time) und ein eindeutiges Ziellabel (churned). Kategorien sollten in eindeutige numerische Kennzeichnungen umgewandelt werden.
Teilen Sie Ihr Dataset in drei Teilmengen auf:
- Trainingssatz (in der Regel etwa 70 bis 80%), um das Modell zu trainieren,
- Validierungs-Dataset (manchmal auch als Entwicklungs-Dataset bezeichnet) zum Optimieren von Hyperparametern und zum Vermeiden von Overfitting.
- Test-Dataset, um die Leistung des Modells bei völlig neuen Daten zu bewerten.
So kann Ihr Modell Entscheidungen verallgemeinern, anstatt sich auf gespeicherte historische Beispiele zu verlassen.
Modell trainieren
Im Gegensatz zu generativer KI, die häufig auf großen, vortrainierten Modellen basiert, nutzen die meisten Systeme mit vorausschauender KI selbsttrainierte Modelle. Das liegt daran, dass Vorhersageaufgaben sehr spezifisch für Ihr Produkt und Ihre Nutzer sind. Tools wie scikit-learn (Python), AutoML (No-Code oder Low-Code) oder TensorFlow.js (JavaScript) erleichtern das Trainieren und Bewerten von Vorhersagemodellen, ohne dass Sie sich um die zugrunde liegende Mathematik kümmern müssen.
In unserem Beispiel zur Kundenabwanderung wird der bereinigte Trainingsdatensatz in einen überwachten Klassifikationsalgorithmus wie die logistische Regression oder ein neuronales Netzwerk eingegeben. Probieren Sie mehrere Optionen aus, um herauszufinden, welche für Ihre Daten am besten geeignet ist.
Ihr Modell lernt, welche Verhaltensmuster mit Churn korrelieren. Am Ende kann jedem Nutzer ein Wahrscheinlichkeitswert zugewiesen werden. Beispiel: Das Risiko, dass Nutzer X im nächsten Monat kündigt, liegt bei 72 %.
Bewerten Sie das resultierende Modell nach jeder Trainingsiteration mit dem Validierungs-Dataset. Die Leistung eines Modells lässt sich durch Anpassen von Hyperparametern, aber auch durch gezielte Verbesserungen an Ihrem Dataset steigern.
Modell bewerten
Die Labels in Ihrem Dataset liefern die Ground Truth, mit der Sie die Modellausgaben vergleichen können. Die wichtigsten Messwerte, die Sie im Blick behalten sollten, sind:
- Genauigkeit: Wie viele der Nutzer, die als „abgewandert“ gekennzeichnet wurden, sind tatsächlich abgewandert?
- Recall: Wie viele der Nutzer, die abgewandert sind, wurden vom Modell erfasst?
- F1-Wert: Eine einzelne Zahl, die ein Gleichgewicht zwischen Precision und Recall herstellt. Sie ist nützlich, wenn Sie einen allgemeinen Messwert für die Genauigkeit benötigen, ohne einen der beiden Werte auf Kosten des anderen zu optimieren.
Zu viele falsch positive Ergebnisse führen zu verschwendeten Bemühungen zur Kundenbindung, während zu viele falsch negative Ergebnisse zu verlorenen Kunden führen. Der richtige Kompromiss hängt von Ihren geschäftlichen Prioritäten ab. Ihr Unternehmen zieht es möglicherweise vor, einige Falschmeldungen in Kauf zu nehmen, wenn dadurch die Wahrscheinlichkeit steigt, mehr Nutzer zu erfassen, bevor sie die Website verlassen.
Modell bereitstellen und verwalten
Nach der Validierung können Sie das Modell mit einer API oder als schlanken clientseitigen Dienst bereitstellen, der in Ihr Analysedashboard eingebunden ist. Jeden Tag können Nutzer bewertet und eine Visualisierung des Abwanderungsrisikos aktualisiert werden, damit Ihr Team die Kontaktaufnahme priorisieren kann. Damit die Daten genau und zuverlässig bleiben, sollten Sie die folgenden Empfehlungen von MLOps-Teams (Machine Learning Operations) berücksichtigen:
- Datenabweichung beobachten: Erkennen Sie, wenn sich das Nutzerverhalten ändert und Ihre Trainingsdaten nicht mehr der Realität entsprechen.
- Wenn Sie beispielsweise eine größere Überarbeitung der Benutzeroberfläche vornehmen, interagieren Nutzer anders mit den Funktionen, was dazu führt, dass die Vorhersagen zur Abwanderung weniger genau werden.
- Aus Fehlern lernen: Identifizieren Sie häufige Muster hinter falschen Vorhersagen und fügen Sie gezielte Beispiele hinzu, um den nächsten Trainingszyklus zu verbessern.
- Das Modell kennzeichnet beispielsweise häufig Poweruser als Risiko für Churn, da sie viele Supportanfragen öffnen. Nach der Überprüfung fügen Sie neue Funktionen hinzu, die die Fehlerbehebung von der Abmeldung unterscheiden.
- Regelmäßig neu trainieren: Auch wenn die Leistung stabil erscheint, sollten Sie das Modell regelmäßig aktualisieren, um saisonale Muster, Produktupdates oder Preisänderungen zu berücksichtigen.
- Sie trainieren das Modell beispielsweise neu, nachdem Sie Jahrestarife eingeführt haben, da sich die Preisstruktur auf das Verhalten der Nutzer vor der Verlängerung auswirkt.
Dieser Lebenszyklus ist das Rückgrat der prädiktiven KI. Mit Tools wie MLflow und Weights & Biases können Sie diesen Prozess ohne umfassendes ML-Fachwissen ausführen.
Häufige Schwierigkeiten und Risikominderungen
Gelegentliche Fehler lassen sich nicht vermeiden, aber Sie können sich vor häufigen Ursachen schützen, die die Leistung und das Vertrauen der Nutzer untergraben können:
- Daten von geringer Qualität: Wenn Ihre Eingabedaten verrauscht oder unvollständig sind, sind auch Ihre Vorhersagen verrauscht oder unvollständig. Um das Risiko zu minimieren, sollten Sie Ihre Daten vor dem Training visualisieren und validieren. Sie müssen die erforderlichen Lernsignale haben und fehlende Werte verarbeiten. Datenqualität in der Produktion überwachen
Überanpassung: Das Modell schneidet bei Trainingsdaten sehr gut ab, versagt aber in neuen Fällen. Um das Problem zu beheben, verwenden Sie Kreuzvalidierung, Regularisierung und Holdout-Datasets. So kann Ihr Modell über die Trainingsbeispiele hinaus generalisieren.
Data Drift: Das Nutzerverhalten und die Umgebung ändern sich, Ihr Modell jedoch nicht. Um das Problem zu beheben, planen Sie das erneute Training und fügen Sie Monitoring hinzu, um zu erkennen, wann die Genauigkeit sinkt.
Schlechte Messwerte: Die Gesamtgenauigkeit spiegelt nicht immer die Prioritäten Ihrer Nutzer wider. Manchmal ist beispielsweise der „Preis“ eines bestimmten Fehlers wichtiger. Bei der Betrugserkennung ist es viel schlimmer, einen betrügerischen Fall zu übersehen (falsch negativ), als einen unschuldigen Fall zu melden (falsch positiv). Um das zu vermeiden, sollten Sie die Messwerte an den realen Zielen für die Betrugserkennung ausrichten.
Die meisten dieser Probleme sind nicht schwerwiegend. Führen Sie das System schrittweise ein und beheben Sie Probleme, sobald sie auftreten.
Der Schlüssel zu diesem schlanken, flexiblen Ansatz ist die Beobachtbarkeit. Erstellen Sie Versionen Ihrer Modelle, protokollieren Sie Genauigkeitsmerkmale und Tools, die zum Erstellen des Modells verwendet wurden, verfolgen Sie die Leistung im Zeitverlauf und sorgen Sie dafür, dass das Monitoring aktiv bleibt. Wenn etwas abweicht oder nicht mehr funktioniert, können Sie das Problem erkennen und beheben, bevor Nutzer es bemerken.
Wichtige Erkenntnisse
Mit Predictive AI werden Ihre vorhandenen Daten in Prognosen umgewandelt. So lässt sich vorhersagen, was als Nächstes passieren wird und wo Sie aktiv werden sollten. Das ist die konkreteste und messbarste Form von KI. Konzentrieren Sie sich auf klar definierte Probleme, die sich in Daten ausdrücken lassen, wiederholen Sie den Prozess, wenn sich Ihr Produkt weiterentwickelt, und beobachten Sie die Leistung im Laufe der Zeit.
Im nächsten Modul erfahren Sie mehr über generative KI, mit der Sie auf Grundlage der verfügbaren Daten etwas Neues erstellen können.
Ressourcen
Wenn Sie mehr über die Mathematik hinter der Vorhersage-KI erfahren möchten, empfehlen wir Ihnen die folgenden Ressourcen:
- Crashkurse zu Machine Learning für Klassifizierung, lineare Regression und logistische Regression.
- Die Kursautorin Janna Lipenkova hat in Kapitel 4 von The Art of AI Product Development: Delivering Business Value (Die Kunst der KI-Produktentwicklung: Geschäftlichen Nutzen erzielen) mehr über das Thema der prädiktiven KI geschrieben.
- Artificial Intelligence: A Modern Approach von Stuart Jonathan Russell und Peter Norvig. Dieses Buch wurde ursprünglich 1995 veröffentlicht und die letzte Ausgabe erschien 2021. Sie wird häufig in KI-Entwicklungsprogrammen unterrichtet.
- Pattern Recognition and Machine Learning von Christopher M. Bishop für einen sehr umfassenden und akademischen Ansatz für prädiktive KI.
Wissen testen
Was ist die Hauptfunktion von Predictive AI?
Bei welcher Aufgabe werden Elemente anhand von Mustern in vordefinierte Kategorien eingeteilt?
Warum sollten Sie im „Predictive AI-Zyklus“ Ihr Dataset in Trainings-, Validierungs- und Test-Datasets aufteilen?
Welcher Messwert gleicht Genauigkeit und Trefferquote aus, um ein allgemeines Maß für die Richtigkeit zu liefern?
Was ist Data Drift und wie können Sie ihn minimieren?