
A IA preditiva (ou analítica) é um conjunto de algoritmos que ajudam você a entender os dados atuais e prever o que provavelmente vai acontecer em seguida. Com base em padrões históricos, os modelos de IA preditiva aprendem diferentes tarefas analíticas que ajudam os usuários a entender os dados:
- Classificação: agrupa itens em categorias predefinidas com base em padrões nos dados. Por exemplo, uma loja on-line pode classificar os visitantes por intenção (pesquisa, compra, devoluções) para adaptar as recomendações de acordo com isso.
- Regressão: prevê valores numéricos, como taxa de engajamento, duração da sessão ou probabilidade de conversão.
- Recomendação: sugira itens mais relevantes para um determinado usuário ou contexto. Pense em "usuários como você também acessaram" ou "tutoriais recomendados com base no seu progresso".
- Previsão e detecção de anomalias: o modelo prevê eventos futuros, como um pico de tráfego, ou identifica comportamentos incomuns, como anomalias de pagamento ou fraude.
Alguns produtos são criados totalmente com base na IA preditiva, como ferramentas de descoberta de músicas. Em outros, a IA preditiva melhora uma experiência determinística, como um site de streaming com recomendações personalizadas. A IA preditiva também pode ser um facilitador interno poderoso: use-a para analisar dados de produtos e usuários, descobrir insights e orientar as próximas ações de forma mais inteligente.
O loop da IA preditiva
O desenvolvimento de um sistema de IA preditiva segue um ciclo iterativo: defina sua oportunidade, prepare os dados, treine o modelo, avalie o modelo e implante o modelo.
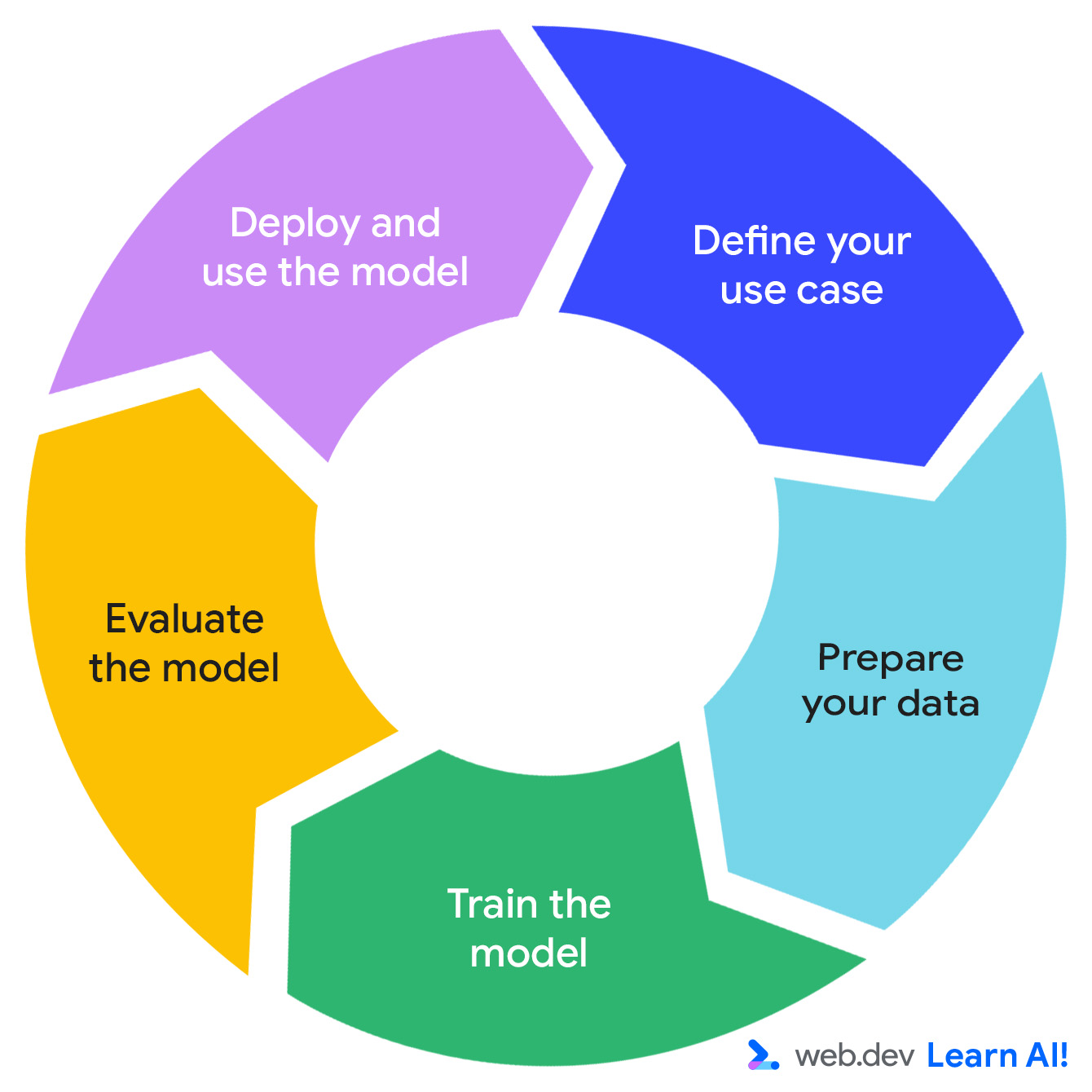
Imagine que você está trabalhando em um app de produtividade por assinatura chamado Do All The Things. Você já coleta dados de uso, como visualizações de página, duração da sessão, uso de recursos e renovações de assinatura. Agora, você quer extrair mais valor útil dos dados. Veja como viajar pelo ciclo de IA preditiva.
Defina seu caso de uso
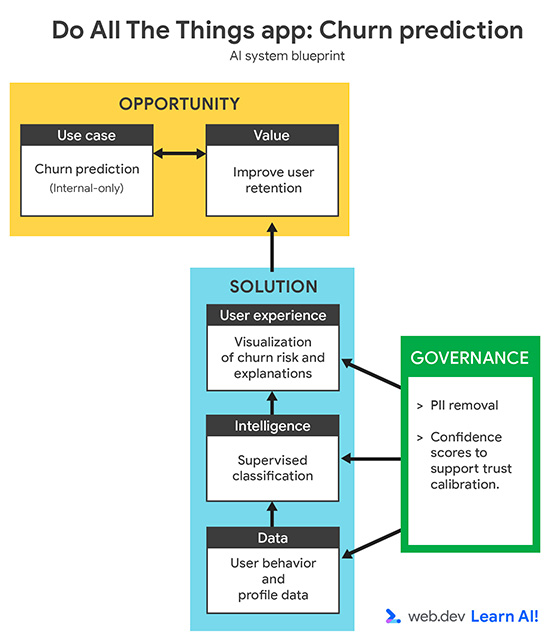
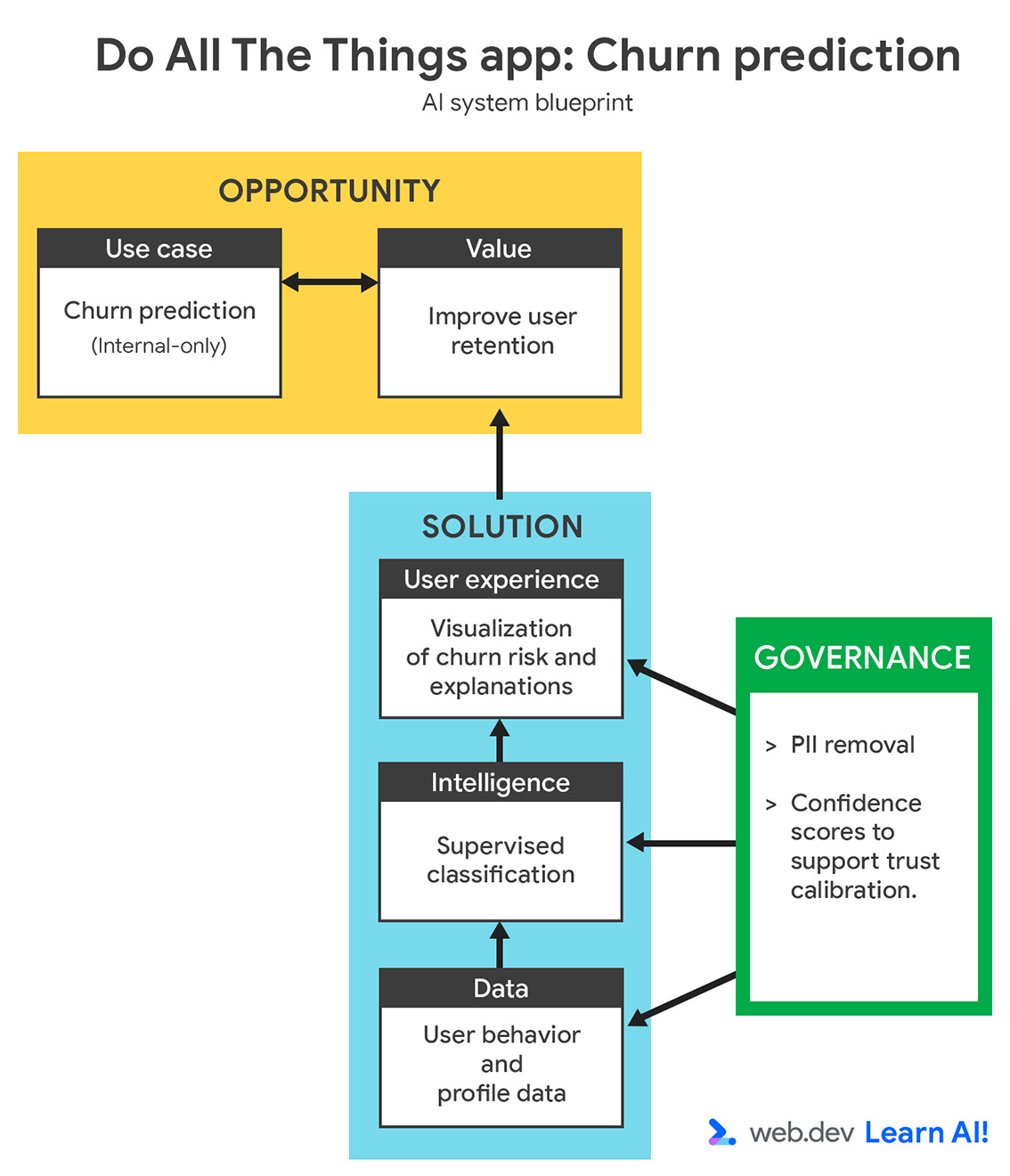{kind=link}
Sua taxa de desistência aumentou nos últimos três meses. Em vez de reagir depois que os usuários cancelam, use a IA preditiva para identificar os usuários que provavelmente vão abandonar o serviço antes de cancelar. O objetivo é apoiar sua equipe de sucesso do cliente com indicadores iniciais para que ela possa tomar medidas direcionadas e proativas para reter usuários em risco.
Ao definir um caso de uso de IA preditiva, comece validando se a pergunta pode ser respondida com dados. Podem ser dados que você já coletou ou que pode coletar daqui para frente. Essa etapa geralmente exige colaboração com especialistas no assunto, como equipes de sucesso do cliente, crescimento ou marketing, para garantir que a previsão seja significativa e útil.
Uma definição de problema forte deve especificar:
- Meta: qual resultado de negócios você está tentando influenciar? Por exemplo, você quer reduzir o churn ativando o contato proativo.
- Dados de entrada: quais indicadores históricos o modelo aprende? Por exemplo, você fornece padrões de uso, tipos de planos e interações de suporte.
- Saída: o que o modelo vai gerar? Por exemplo, você quer que o modelo crie uma pontuação de probabilidade de desistência para cada usuário.
- Usuário: quem usa ou age com base na previsão? Por exemplo, esses dados são destinados a gerentes de sucesso do cliente.
- Critérios de sucesso: como você mede o impacto? Por exemplo, você mede a taxa de retenção para determinar se reduziu o churn.
Ao identificar esses detalhes no início, você evita uma armadilha comum: criar um modelo personalizado tecnicamente sólido, mas que nunca é usado.
Preparar os dados
Para fornecer ao modelo indicadores de aprendizado úteis, rotule seus dados históricos com previsões ideais. Marque os usuários do rótulo Do All The Things como "desistiram" ou "não desistiram".
Em seguida, trabalhe com a equipe de sucesso do cliente para identificar quais recursos comportamentais são mais relevantes para a previsão de rotatividade. Reduza o conjunto de dados para esses recursos principais e remova campos desnecessários para que o modelo não precise lidar com ruídos. Não se esqueça de considerar a privacidade de dados. Remova informações de identificação pessoal (PII), como nomes ou e-mails, e armazene apenas dados comportamentais agregados.
A tabela a seguir mostra um trecho do conjunto de dados resultante:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | Premium | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | Google AI Pro | 5,8 | 3 | 1 | 2 | 1 |
| 00125 | sem custos | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | Premium | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | Google AI Pro | 4.2 | 2 | 1 | 3 | 1 |
Isso fornece ao modelo entradas numéricas e categóricas limpas (como plan_type ou avg_session_time) e um rótulo de destino claro (churned). As categorias precisam ser convertidas em identificadores numéricos exclusivos.
Por fim, divida o conjunto de dados em três subconjuntos:
- Conjunto de treinamento (geralmente de 70 a 80%) para ensinar o modelo.
- Conjunto de validação (às vezes também chamado de conjunto de desenvolvimento) para ajustar hiperparâmetros e evitar overfitting.
- Conjunto de teste para avaliar o desempenho do modelo com dados totalmente inéditos.
Isso ajuda o modelo a generalizar decisões em vez de depender de exemplos históricos memorizados.
Treine o modelo
Ao contrário da IA generativa, que geralmente é criada com base em modelos grandes e pré-treinados, a maioria dos sistemas de IA preditiva usa modelos de autoaprendizagem. Isso porque as tarefas preditivas são altamente específicas para seu produto e seus usuários. Ferramentas como scikit-learn (Python), AutoML (sem código ou com pouco código) ou TensorFlow.js (JavaScript) facilitam o treinamento e a avaliação de modelos preditivos sem se preocupar com a matemática por trás.
No nosso exemplo de desistência, alimentamos o conjunto de treinamento limpo em um algoritmo de classificação supervisionado, como regressão logística ou uma rede neural. Teste várias opções para determinar o que funciona melhor para seus dados.
O modelo aprende quais padrões de comportamento estão relacionados ao cancelamento. No final, ele pode atribuir uma pontuação de probabilidade a cada usuário. Por exemplo, há um risco de 72% de que o usuário X cancele no próximo mês.
Após cada iteração de treinamento, avalie o modelo resultante usando o conjunto de validação. O desempenho de um modelo pode ser melhorado ajustando os hiperparâmetros e fazendo melhorias direcionadas no conjunto de dados.
Avaliar o modelo
Os rótulos no conjunto de dados fornecem a verdade fundamental para comparar as saídas do modelo. As principais métricas a serem rastreadas são:
- Precisão: de todos os usuários sinalizados como "desistentes", quantos realmente desistiram?
- Recall: de todos os usuários que cancelaram, quantos o modelo detectou?
- Pontuação F1: um único número que equilibra precisão e recall, útil quando você quer uma medida geral de acurácia sem otimizar demais uma em detrimento da outra.
Muitos falsos positivos desperdiçam os esforços de retenção, enquanto muitos falsos negativos levam à perda de clientes. A troca certa depende das prioridades da sua empresa. Por exemplo, sua empresa pode preferir lidar com alguns alarmes falsos se isso aumentar a probabilidade de capturar mais usuários antes que eles saiam.
Implantar e manter o modelo
Depois de validado, você pode implantar o modelo com uma API ou como um serviço leve do lado do cliente integrado ao seu painel de análises. Todos os dias, ele pode pontuar usuários e atualizar uma visualização de risco de desistência, permitindo que sua equipe priorize o alcance. Para manter a precisão e a confiabilidade, adote estas lições das equipes de operações de machine learning (MLOps):
- Monitore o desvio de dados: detecte quando o comportamento do usuário muda e os dados de treinamento não representam mais a realidade.
- Por exemplo, depois de lançar uma grande reformulação da interface, os usuários interagem com os recursos de maneira diferente, fazendo com que as previsões de desistência se tornem menos precisas.
- Aprenda com os erros: identifique padrões comuns por trás de previsões incorretas e adicione exemplos direcionados para melhorar o próximo ciclo de treinamento.
- Por exemplo, o modelo frequentemente sinaliza usuários avançados como riscos de desistência porque eles abrem muitos tíquetes de suporte. Depois da revisão, adicione novos recursos que distinguem a solução de problemas do desinteresse.
- Retreine regularmente: mesmo que o desempenho pareça estável, atualize o modelo periodicamente para considerar padrões sazonais, atualizações de produtos ou mudanças de preços.
- Por exemplo, você treina novamente o modelo depois de apresentar planos anuais, já que a estrutura de preços muda o comportamento dos usuários antes da renovação.
Esse ciclo de vida é a base da IA preditiva. Com ferramentas como MLflow e Weights & Biases, é possível executar esse processo sem ter experiência em ML.
Dificuldades e mitigações comuns
Embora erros ocasionais aconteçam, é possível se proteger contra causas comuns que podem prejudicar a performance e a confiança do usuário:
- Dados de baixa qualidade: se os dados de entrada forem ruidosos ou incompletos, as previsões também serão. Para mitigar, visualize e valide seus dados antes do treinamento. Verifique se você tem os indicadores de aprendizado necessários e processe os valores ausentes. Monitore a qualidade dos dados em produção.
Overfitting: o modelo tem um desempenho muito bom com os dados de treinamento, mas falha em novos casos. Para reduzir esse problema, use validação cruzada, regularização e conjuntos de dados de validação. Isso ajuda o modelo a generalizar além dos exemplos de treinamento.
Desvio de dados: o comportamento e os ambientes dos usuários mudam, mas o modelo não. Para minimizar, programe o retreinamento e adicione o monitoramento para detectar quando a acurácia começar a cair.
Métricas ruins: a acurácia geral nem sempre reflete as prioridades dos seus usuários. Por exemplo, às vezes, o "custo" de um erro específico é mais importante. Na detecção de fraudes, perder um caso fraudulento (falso negativo) é muito pior do que sinalizar um inocente (falso positivo). Para reduzir esse problema, alinhe as métricas com metas reais de detecção de fraudes.
A maioria desses problemas não é fatal. Lance o sistema gradualmente e resolva os problemas à medida que eles surgirem.
A chave para essa abordagem enxuta e flexível é a capacidade de observação. Controle a versão dos modelos, registre as características de acurácia e as ferramentas usadas para criar o modelo, acompanhe o desempenho ao longo do tempo e mantenha o monitoramento ativo. Quando algo mudar ou quebrar, você poderá detectar e corrigir o problema antes que os usuários percebam.
Seus pontos principais
A IA preditiva transforma seus dados atuais em insights, revelando o que provavelmente vai acontecer e onde agir. É a forma mais concreta e mensurável de IA. Concentre-se em problemas bem definidos que podem ser expressos em dados, continue iterando à medida que seu produto evolui e monitore a performance ao longo do tempo.
No próximo módulo, você vai aprender sobre a IA generativa, que ajuda a criar algo novo com base nos dados disponíveis.
Recursos
Se você quiser entender a matemática por trás da IA preditiva, recomendamos que consulte estes recursos:
- Cursos intensivos de aprendizado de máquina sobre classificação, regressão linear e regressão logística.
- A autora do curso, Janna Lipenkova, escreveu mais sobre o tema da IA preditiva no capítulo 4 de The Art of AI Product Development: Delivering Business Value (em inglês).
- Inteligência artificial: uma abordagem moderna, de Stuart Jonathan Russell e Peter Norvig. O livro foi publicado inicialmente em 1995, e a edição mais recente foi lançada em 2021. Ele é ensinado em programas de engenharia de IA.
- Pattern Recognition and Machine Learning de Christopher M. Bishop, para uma abordagem acadêmica e abrangente do aprendizado de IA preditiva.
Teste seu conhecimento
Qual é a principal função da IA preditiva?
Qual tarefa envolve agrupar itens em categorias predefinidas com base em padrões?
No "loop de IA preditiva", por que você deve dividir seu conjunto de dados em conjuntos de treinamento, validação e teste?
Qual métrica equilibra precisão e recall para fornecer uma medida geral de acurácia?
O que é o deslocamento de dados e como mitigá-lo?