
AI เชิงคาดการณ์ (หรือเชิงวิเคราะห์) คือชุดอัลกอริทึมที่จะช่วยให้คุณ เข้าใจข้อมูลที่มีอยู่และคาดการณ์สิ่งที่น่าจะเกิดขึ้นต่อไป โมเดล AI เชิงคาดการณ์จะเรียนรู้งานวิเคราะห์ต่างๆ ที่ช่วยให้ผู้ใช้เข้าใจข้อมูลของตนเองโดยอิงตามรูปแบบในอดีต ดังนี้
- การจัดประเภท: จัดกลุ่มรายการเป็นหมวดหมู่ที่กำหนดไว้ล่วงหน้าตามรูปแบบ ในข้อมูล ตัวอย่างเช่น ร้านค้าออนไลน์อาจจัดประเภทผู้เข้าชมตามความตั้งใจ (การวิจัย การซื้อ การคืนสินค้า) เพื่อปรับคำแนะนำให้สอดคล้องกัน
- การถดถอย: คาดการณ์ค่าตัวเลข เช่น อัตราการมีส่วนร่วม ระยะเวลาเซสชัน หรือความน่าจะเป็นของ Conversion
- คำแนะนำ: แนะนำรายการที่เกี่ยวข้องกับผู้ใช้หรือบริบทที่กำหนดมากที่สุด ลองนึกถึง"ผู้ใช้ที่ชอบคุณยังดู" หรือ "บทแนะนำที่แนะนำตามความคืบหน้าของคุณ"
- การคาดการณ์และการตรวจหาความผิดปกติ: โมเดลจะคาดการณ์เหตุการณ์ในอนาคต เช่น ปริมาณการเข้าชมที่เพิ่มขึ้น หรือระบุพฤติกรรมที่ผิดปกติ เช่น ความผิดปกติในการชำระเงินหรือการฉ้อโกง
ผลิตภัณฑ์บางอย่างสร้างขึ้นโดยอิงตาม AI แบบคาดการณ์ทั้งหมด เช่น เครื่องมือค้นพบเพลง ในกรณีอื่นๆ AI แบบคาดการณ์จะช่วยปรับปรุงประสบการณ์ที่กำหนดไว้แล้ว เช่น เว็บไซต์สตรีมมิงที่มีคำแนะนำที่ปรับเปลี่ยนในแบบของคุณ นอกจากนี้ AI เชิงคาดการณ์ยังเป็น เครื่องมือภายในที่มีประสิทธิภาพได้ด้วย โดยคุณสามารถใช้ AI นี้เพื่อวิเคราะห์ข้อมูลผลิตภัณฑ์และผู้ใช้เพื่อ ค้นพบข้อมูลเชิงลึกและแนะนําการดําเนินการถัดไปที่ชาญฉลาดยิ่งขึ้น
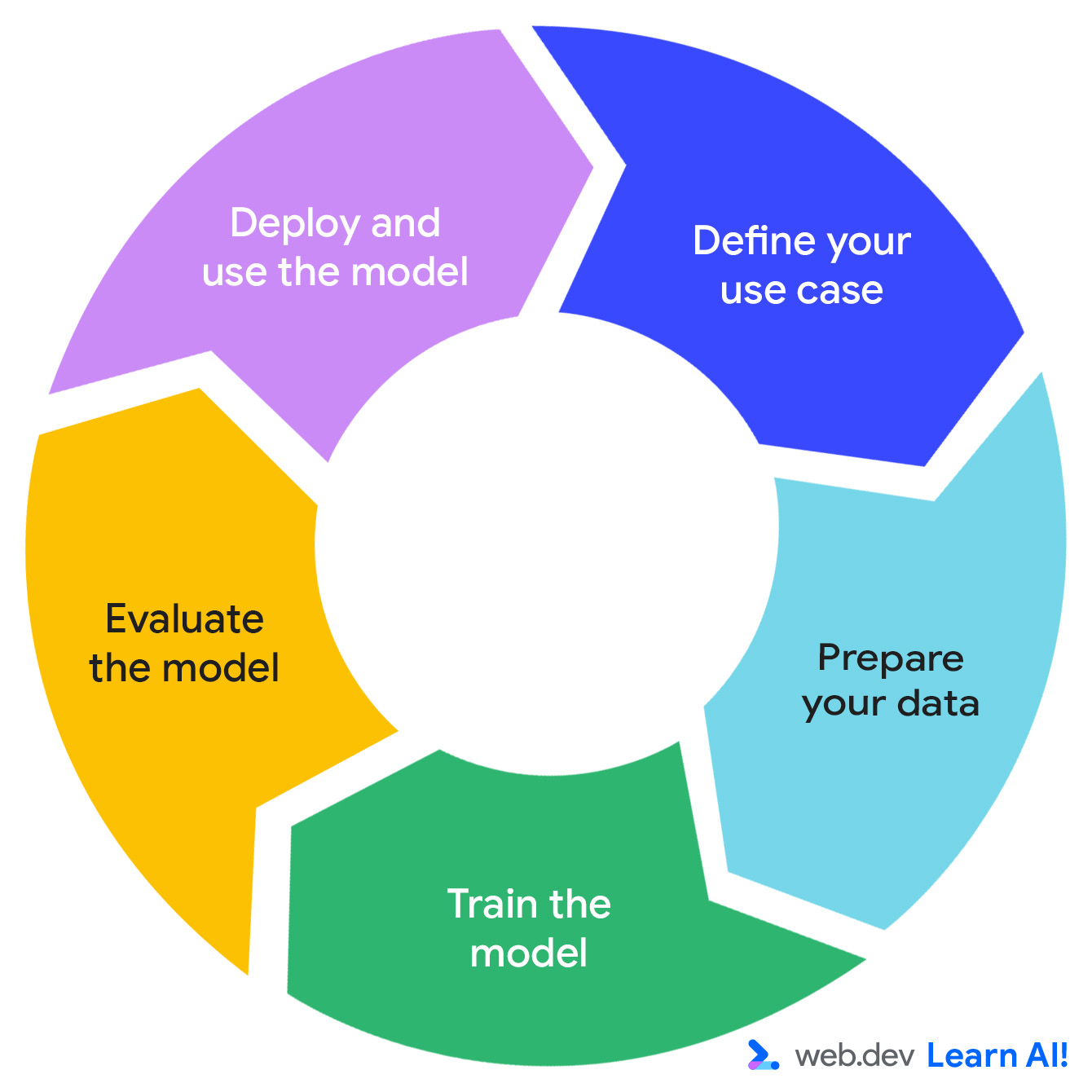
วงจร Predictive AI
การพัฒนาระบบ AI แบบคาดการณ์เป็นไปตามวงจรแบบวนซ้ำ ซึ่งประกอบด้วย การกำหนดโอกาส การเตรียมข้อมูล การฝึกโมเดล การประเมินโมเดล และการใช้งานโมเดล
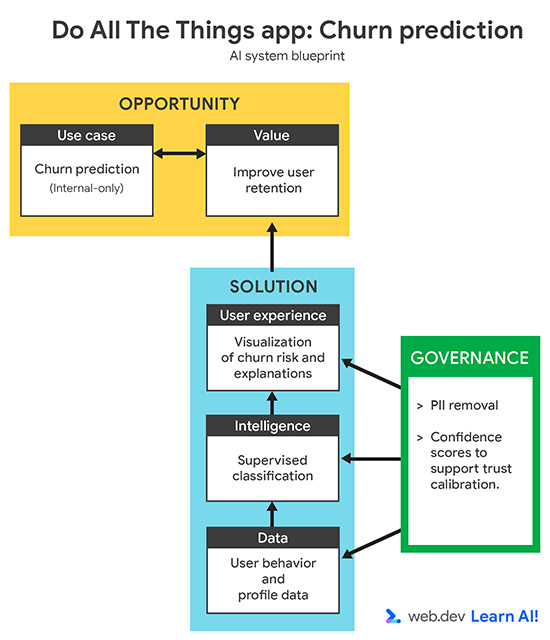
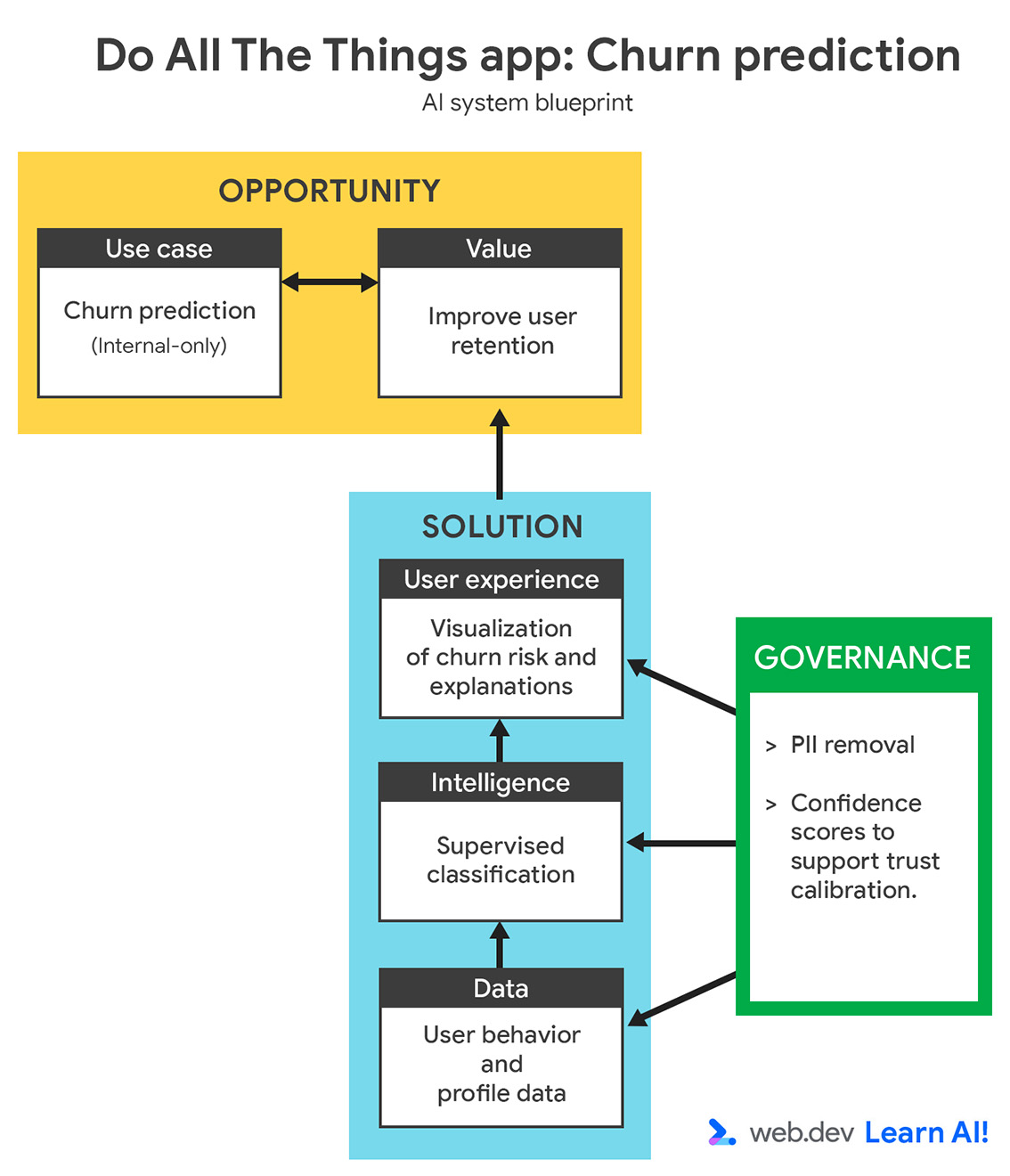
สมมติว่าคุณกำลังทำงานกับแอปเพื่อการทำงานแบบสมัครใช้บริการชื่อ Do All The Things คุณรวบรวมข้อมูลการใช้งานอยู่แล้ว เช่น การดูหน้าเว็บ ระยะเวลาเซสชัน การใช้งานฟีเจอร์ และการต่ออายุการสมัครใช้บริการ ตอนนี้คุณต้องการดึง มูลค่าที่นำไปใช้ได้จริงจากข้อมูล วิธีเดินทางผ่านลูป AI เชิงคาดการณ์มีดังนี้
กำหนดกรณีการใช้งาน
{kind=link}
อัตราการเลิกใช้งานเพิ่มขึ้นในช่วง 3 เดือนที่ผ่านมา คุณต้องการใช้ AI เชิงคาดการณ์เพื่อระบุผู้ใช้ที่มีแนวโน้มที่จะเลิกใช้งานก่อนที่ผู้ใช้จะยกเลิก แทนที่จะดำเนินการหลังจากที่ผู้ใช้ยกเลิก เป้าหมายคือการสนับสนุนทีมความสําเร็จของลูกค้าด้วยสัญญาณเบื้องต้น เพื่อให้ทีมสามารถดําเนินการเชิงรุกแบบกําหนดเป้าหมาย เพื่อรักษาผู้ใช้ที่มีความเสี่ยง
เมื่อกำหนดกรณีการใช้งาน AI เชิงคาดการณ์ ให้เริ่มด้วยการตรวจสอบว่าคำถามนั้นตอบได้ด้วยข้อมูล ซึ่งอาจเป็นข้อมูลที่คุณรวบรวมไว้แล้วหรือข้อมูลที่คุณ สามารถรวบรวมได้จริงนับจากนี้เป็นต้นไป ขั้นตอนนี้มักต้องอาศัย การทำงานร่วมกับผู้เชี่ยวชาญด้านโดเมน เช่น ทีมความสำเร็จของลูกค้า ทีมการเติบโต หรือ ทีมการตลาด เพื่อให้มั่นใจว่าการคาดการณ์มีความหมายและนำไปใช้ได้จริง
การกำหนดปัญหาที่ชัดเจนควรระบุสิ่งต่อไปนี้
- เป้าหมาย: คุณพยายามมีอิทธิพลต่อผลลัพธ์ทางธุรกิจใด เช่น คุณต้องการลดการเลิกใช้งานโดยการเปิดใช้การติดต่อเชิงรุก
- ข้อมูลอินพุต: โมเดลเรียนรู้จากสัญญาณย้อนหลังใด ตัวอย่างเช่น คุณระบุรูปแบบการใช้งาน ประเภทแพ็กเกจ และการโต้ตอบในการสนับสนุน
- เอาต์พุต: โมเดลจะสร้างอะไร เช่น คุณต้องการให้โมเดล สร้างคะแนนความน่าจะเป็นของการเลิกใช้งานสำหรับผู้ใช้แต่ละราย
- ผู้ใช้: ใครเป็นผู้ใช้หรือดำเนินการตามการคาดการณ์ เช่น ข้อมูลนี้มีไว้สำหรับผู้จัดการฝ่ายความสำเร็จของลูกค้า
- เกณฑ์ความสำเร็จ: คุณวัดผลลัพธ์อย่างไร ตัวอย่างเช่น คุณวัด อัตราการรักษาลูกค้าเพื่อดูว่าได้ลดการเลิกใช้งานหรือไม่
การระบุรายละเอียดเหล่านี้ตั้งแต่เริ่มต้นจะช่วยให้คุณหลีกเลี่ยงข้อผิดพลาดที่พบบ่อยได้ นั่นคือ การสร้างโมเดลที่กำหนดเองซึ่งทำงานได้ดีในทางเทคนิค แต่ไม่เคยถูกนำไปใช้
เตรียมข้อมูล
หากต้องการให้สัญญาณการเรียนรู้ที่เป็นประโยชน์แก่โมเดล คุณต้องติดป้ายกำกับข้อมูลย้อนหลังด้วยการคาดการณ์ที่เหมาะสม ติดป้ายกำกับผู้ใช้ Do All The Things เป็น "เลิกใช้งาน" หรือ "ไม่ได้เลิกใช้งาน"
จากนั้นทํางานร่วมกับทีมความสําเร็จของลูกค้าเพื่อระบุฟีเจอร์ด้านพฤติกรรม ที่เกี่ยวข้องกับการคาดการณ์การเลิกใช้งานมากที่สุด จำกัดชุดข้อมูลให้เหลือเฉพาะฟีเจอร์หลักเหล่านี้และนำฟิลด์ที่ไม่จำเป็นออก เพื่อให้โมเดลไม่ต้องจัดการกับสัญญาณรบกวน อย่าลืมพิจารณาความเป็นส่วนตัวของข้อมูล นำข้อมูลส่วนบุคคลที่ระบุตัวบุคคลนั้นได้ (PII) เช่น ชื่อหรืออีเมล ออก และจัดเก็บเฉพาะข้อมูลเชิงพฤติกรรมที่รวบรวมไว้
ตารางต่อไปนี้แสดงตัวอย่างจากชุดข้อมูลผลลัพธ์
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | พรีเมียม | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | 6 เดือน | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | ฟรี | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | พรีเมียม | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | 6 เดือน | 4.2 | 2 | 1 | 3 | 1 |
ซึ่งจะทำให้โมเดลมีอินพุตเชิงตัวเลขและเชิงหมวดหมู่ที่สะอาด (เช่น plan_type หรือ avg_session_time) และป้ายกำกับเป้าหมายที่ชัดเจน (churned)
ควรแปลงหมวดหมู่เป็นตัวระบุตัวเลขที่ไม่ซ้ำกัน
สุดท้าย ให้แบ่งชุดข้อมูลออกเป็น 3 ชุดย่อย ดังนี้
- ชุดการฝึก (โดยปกติประมาณ 70-80%) เพื่อสอนโมเดล
- ชุดข้อมูลการตรวจสอบ (บางครั้งเรียกว่าชุดข้อมูลการพัฒนา) เพื่อปรับแต่งไฮเปอร์พารามิเตอร์ และป้องกันการเกิด Overfitting
- ชุดทดสอบเพื่อประเมินประสิทธิภาพของโมเดล ในข้อมูลที่ไม่เคยเห็นมาก่อน
ซึ่งจะช่วยให้โมเดลของคุณตัดสินใจได้ทั่วไปแทนที่จะอาศัยตัวอย่างในอดีตที่จดจำไว้
ฝึกโมเดล
ระบบ AI เชิงคาดการณ์ส่วนใหญ่จะอาศัยโมเดลที่ฝึกด้วยตนเอง ซึ่งต่างจาก Generative AI ที่มักสร้างขึ้นจากโมเดลขนาดใหญ่ที่ผ่านการฝึกเบื้องต้น เนื่องจากงานแบบคาดการณ์มีความเฉพาะเจาะจงสูงสำหรับผลิตภัณฑ์และผู้ใช้ของคุณ เครื่องมืออย่าง scikit-learn (Python), AutoML (แบบไม่ต้องเขียนโค้ดหรือใช้โค้ดน้อย) หรือ TensorFlow.js (JavaScript) ช่วยให้ฝึกและประเมินโมเดล การคาดการณ์ได้ง่ายขึ้นโดยไม่ต้องกังวลเกี่ยวกับคณิตศาสตร์พื้นฐาน
ในตัวอย่างการเลิกใช้งาน เราจะป้อนชุดการฝึกที่ทำความสะอาดแล้วลงในอัลกอริทึมการจัดประเภทที่มีการกำกับดูแล เช่น การถดถอยโลจิสติก หรือโครงข่ายประสาทเทียม ลองใช้หลายๆ ตัวเลือกเพื่อดูว่าตัวเลือกใดเหมาะกับข้อมูลของคุณมากที่สุด
โมเดลจะเรียนรู้รูปแบบพฤติกรรมที่สัมพันธ์กับการเลิกใช้งาน และในตอนท้าย ระบบจะ กำหนดคะแนนความน่าจะเป็นให้กับผู้ใช้แต่ละรายได้ เช่น มีความเสี่ยง 72% ที่ ผู้ใช้ X จะยกเลิกในเดือนหน้า
หลังจากการฝึกแต่ละครั้ง ให้ประเมินโมเดลที่ได้โดยใช้ชุดข้อมูลการตรวจสอบ คุณสามารถปรับปรุงประสิทธิภาพของโมเดลได้โดยการปรับไฮเปอร์พารามิเตอร์ รวมถึงการปรับปรุงชุดข้อมูลที่กำหนดเป้าหมายด้วย
ประเมินโมเดล
ป้ายกำกับในชุดข้อมูลจะให้ข้อมูลที่เชื่อถือได้ซึ่งคุณสามารถ เปรียบเทียบเอาต์พุตของโมเดลได้ เมตริกหลักที่ควรติดตามมีดังนี้
- ความแม่นยำ: ในบรรดาผู้ใช้ทั้งหมดที่ถูกแจ้งว่า "เลิกใช้งาน" มีผู้ใช้ที่เลิกใช้งานจริงๆ กี่ราย
- การเรียกคืน: โมเดลจับผู้ใช้ที่เลิกใช้งานได้กี่คนจากผู้ใช้ที่เลิกใช้งานทั้งหมด
- คะแนน F1: ตัวเลขเดียวที่สร้างความสมดุลระหว่างความแม่นยำและความอ่อนไหว ซึ่งมีประโยชน์เมื่อคุณต้องการวัดความแม่นยำโดยรวมโดยไม่ต้องเพิ่มประสิทธิภาพอย่างใดอย่างหนึ่งมากเกินไปจนส่งผลกระทบต่ออีกอย่างหนึ่ง
ผลบวกเท็จมากเกินไปจะทำให้ความพยายามในการรักษาลูกค้าสูญเปล่า ในขณะที่ผลลบเท็จมากเกินไปจะทำให้เสียลูกค้า การประนีประนอมที่เหมาะสมจะขึ้นอยู่กับลำดับความสำคัญของธุรกิจ เช่น บริษัทของคุณอาจต้องการจัดการกับสัญญาณเตือนที่ผิดพลาด 2-3 รายการหากจะช่วยให้มีโอกาสมากขึ้นที่จะดึงดูดผู้ใช้ได้มากขึ้นก่อนที่ผู้ใช้จะออกจากเว็บไซต์
ทำให้โมเดลใช้งานได้และบำรุงรักษา
เมื่อตรวจสอบแล้ว คุณจะนําโมเดลไปใช้งานกับ API หรือเป็นบริการฝั่งไคลเอ็นต์ที่มีน้ำหนักเบาที่ผสานรวม เข้ากับแดชบอร์ดข้อมูลวิเคราะห์ได้ ในแต่ละวัน ระบบจะให้คะแนนผู้ใช้และอัปเดตภาพการแสดงความเสี่ยงที่จะเลิกใช้งาน เพื่อให้ทีมจัดลำดับความสำคัญของการเข้าถึงได้ หากต้องการให้ข้อมูลมีความถูกต้องและเชื่อถือได้ ให้ใช้บทเรียนต่อไปนี้จากทีมปฏิบัติการแมชชีนเลิร์นนิง (MLOps)
- ตรวจสอบการเปลี่ยนแปลงของข้อมูล: ตรวจหาเมื่อพฤติกรรมของผู้ใช้เปลี่ยนไปและข้อมูลการฝึก
ไม่แสดงความเป็นจริงอีกต่อไป
- ตัวอย่างเช่น หลังจากเปิดตัวการออกแบบ UI ครั้งใหญ่ ผู้ใช้จะโต้ตอบกับฟีเจอร์ต่างๆ ในลักษณะที่แตกต่างออกไป ซึ่งทำให้การคาดการณ์การเลิกใช้งานมีความแม่นยำน้อยลง
- เรียนรู้จากข้อผิดพลาด: ระบุรูปแบบที่พบบ่อยซึ่งอยู่เบื้องหลังการคาดการณ์ที่ไม่ถูกต้อง และ
เพิ่มตัวอย่างที่กำหนดเป้าหมายเพื่อปรับปรุงรอบการฝึกครั้งถัดไป
- ตัวอย่างเช่น โมเดลมักจะแจ้งผู้ใช้ขั้นสูงว่าเป็นความเสี่ยงที่จะเลิกใช้งานเนื่องจาก ผู้ใช้เปิดคำขอรับการสนับสนุนจำนวนมาก หลังจากตรวจสอบแล้ว คุณจะเพิ่มฟีเจอร์ใหม่ที่ แยกการแก้ปัญหาจากการเลิกใช้งาน
- ฝึกโมเดลใหม่เป็นประจำ: แม้ว่าประสิทธิภาพจะดูคงที่ แต่ให้รีเฟรชโมเดลเป็นระยะๆ เพื่อให้สอดคล้องกับรูปแบบตามฤดูกาล การอัปเดตผลิตภัณฑ์ หรือการเปลี่ยนแปลงราคา
- เช่น คุณฝึกโมเดลอีกครั้งหลังจากเปิดตัวแพ็กเกจรายปี เนื่องจาก โครงสร้างการกำหนดราคาจะเปลี่ยนพฤติกรรมของผู้ใช้ก่อนต่ออายุ
วงจรนี้เป็นแกนหลักของ AI เชิงคาดการณ์ เครื่องมืออย่าง MLflow และ Weights & Biases ช่วยให้คุณเรียกใช้กระบวนการนี้ได้โดยไม่ต้องมีความเชี่ยวชาญด้าน ML ในเชิงลึก
ข้อผิดพลาดที่พบบ่อยและการลดความเสี่ยง
แม้ว่าข้อผิดพลาดจะเกิดขึ้นเป็นครั้งคราว แต่คุณก็สามารถป้องกันสาเหตุหลักที่พบบ่อย ซึ่งอาจบั่นทอนประสิทธิภาพและความไว้วางใจของผู้ใช้ได้
- ข้อมูลคุณภาพต่ำ: หากข้อมูลนำเข้ามีสัญญาณรบกวนหรือไม่สมบูรณ์ การคาดการณ์ก็จะเช่นกัน หากต้องการลดผลกระทบ ให้แสดงภาพและตรวจสอบข้อมูลก่อน การฝึก ตรวจสอบว่าคุณมีสัญญาณการเรียนรู้ที่จำเป็นและจัดการค่าที่ขาดหายไป ตรวจสอบคุณภาพของข้อมูลในการทำงานจริง
Overfitting: โมเดลทํางานได้ดีมากในข้อมูลการฝึก แต่ทํางานไม่ได้ใน กรณีใหม่ หากต้องการลดปัญหา ให้ใช้การตรวจสอบแบบไขว้ การทำให้เป็นปกติ และชุดข้อมูลที่แยกไว้ ซึ่งจะช่วยให้โมเดลของคุณสรุปผลได้นอกเหนือจากตัวอย่างการฝึก
การเปลี่ยนแปลงของข้อมูล: พฤติกรรมและสภาพแวดล้อมของผู้ใช้เปลี่ยนแปลงไป แต่โมเดลของคุณไม่เปลี่ยนแปลง หากต้องการลดผลกระทบ ให้กำหนดเวลาการฝึกใหม่และเพิ่มการตรวจสอบเพื่อตรวจหาเมื่อความแม่นยำเริ่มลดลง
เมตริกที่ไม่ดี: ความแม่นยำโดยรวมไม่ได้สะท้อนถึงลำดับความสำคัญของผู้ใช้เสมอไป ตัวอย่างเช่น ในบางครั้ง "ต้นทุน" ของข้อผิดพลาดที่เฉพาะเจาะจงอาจมีความสำคัญมากกว่า ในการตรวจหาการประพฤติมิชอบ การพลาดเคสการประพฤติมิชอบ (ผลลบลวง) นั้นแย่กว่าการแจ้งเคสที่ไม่มีการประพฤติมิชอบ (ผลบวกลวง) มาก เพื่อลดความเสี่ยง ให้ปรับ เมตริกให้สอดคล้องกับเป้าหมายในโลกแห่งความเป็นจริงสำหรับการตรวจหาการฉ้อโกง
ปัญหาเหล่านี้ส่วนใหญ่ไม่ได้ร้ายแรง ค่อยๆ เปิดตัวระบบและแก้ไขปัญหาที่เกิดขึ้น
กุญแจสำคัญของแนวทางที่มีประสิทธิภาพและยืดหยุ่นนี้คือความสามารถในการสังเกต จัดเวอร์ชันโมเดล บันทึกลักษณะความแม่นยำและเครื่องมือที่ใช้สร้างโมเดล ติดตาม ประสิทธิภาพเมื่อเวลาผ่านไป และตรวจสอบอย่างต่อเนื่อง เมื่อมีสิ่งใดเปลี่ยนแปลงหรือหยุดทำงาน คุณจะสามารถตรวจจับและแก้ไขปัญหาได้ ก่อนที่ผู้ใช้จะสังเกตเห็น
สิ่งที่ได้เรียนรู้
AI เชิงคาดการณ์จะเปลี่ยนข้อมูลที่มีอยู่ให้กลายเป็นความสามารถในการคาดการณ์ ซึ่งจะเผยให้เห็นสิ่งที่น่าจะเกิดขึ้นต่อไปและจุดที่ควรดำเนินการ ซึ่งเป็นรูปแบบ AI ที่เป็นรูปธรรมและวัดผลได้มากที่สุด มุ่งเน้นปัญหาที่กำหนดไว้อย่างชัดเจนซึ่งแสดงในข้อมูลได้ ทำซ้ำอย่างต่อเนื่องเมื่อผลิตภัณฑ์พัฒนาขึ้น และตรวจสอบประสิทธิภาพเมื่อเวลาผ่านไป
ในโมดูลถัดไป คุณจะได้เรียนรู้เกี่ยวกับ Generative AI ซึ่งจะช่วยให้คุณสร้างสรรค์สิ่งใหม่ๆ จากข้อมูลที่มีอยู่
แหล่งข้อมูล
หากสนใจทำความเข้าใจคณิตศาสตร์เบื้องหลัง AI เชิงคาดการณ์ เราขอแนะนำให้คุณดูแหล่งข้อมูลต่อไปนี้
- หลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิงในหัวข้อ การจัดประเภท การถดถอยเชิงเส้น และการถดถอยโลจิสติก
- ผู้เขียนหลักสูตร Janna Lipenkova ได้เขียนเพิ่มเติมเกี่ยวกับหัวข้อ AI เชิงคาดการณ์ในบทที่ 4 ของศิลปะการพัฒนาผลิตภัณฑ์ AI: การส่งมอบมูลค่าทางธุรกิจ
- ปัญญาประดิษฐ์: แนวทางที่ทันสมัย โดย Stuart Jonathan Russell และ Peter Norvig หนังสือเล่มนี้เผยแพร่ครั้งแรก ในปี 1995 และฉบับล่าสุดเผยแพร่ในปี 2021 ซึ่งมักจะ สอนในโปรแกรมวิศวกรรม AI
- การจดจำรูปแบบและแมชชีนเลิร์นนิง โดย Christopher M. Bishop สำหรับแนวทางที่ครอบคลุมและเชิงวิชาการอย่างยิ่งในการ เรียนรู้ AI แบบคาดการณ์
ทดสอบความเข้าใจ
ฟังก์ชันหลักของ AI เชิงคาดการณ์คืออะไร
งานใดที่เกี่ยวข้องกับการจัดกลุ่มรายการลงในหมวดหมู่ที่กำหนดไว้ล่วงหน้าตามรูปแบบ
ใน "วงจร AI เชิงคาดการณ์" เหตุใดคุณจึงควรแยกชุดข้อมูลออกเป็นชุดการฝึก ชุดการตรวจสอบ และชุดการทดสอบ
เมตริกใดที่ปรับสมดุลความแม่นยำและความอ่อนไหวเพื่อให้การวัดความถูกต้องโดยรวม
การเปลี่ยนแปลงของข้อมูลคืออะไร และคุณควรลดการเปลี่ยนแปลงของข้อมูลอย่างไร