
預測 (或分析) 型 AI 是一組演算法,可協助您瞭解現有資料,並預測接下來可能發生的情況。預測型 AI 模型會根據歷史模式學習不同的分析工作,協助使用者解讀資料:
- 分類:根據資料中的模式,將項目分入預先定義的類別。舉例來說,網路商店可能會依據訪客意圖 (研究、購買、退貨) 分類,以便據此調整建議。
- 迴歸:預測數值,例如參與度、工作階段時間長度或轉換機率。
- 推薦:根據特定使用者或情境,建議最相關的項目。例如「與你類似的使用者也觀看了」或「根據你的進度推薦的教學課程」。
- 預測和異常偵測:模型會預測未來的事件,例如流量尖峰,或找出異常行為,例如付款異常或詐欺。
部分產品完全以預測型 AI 為基礎,例如音樂探索工具。在其他情況下,預測型 AI 會提升確定性體驗,例如提供個人化推薦內容的串流網站。預測型 AI 也是強大的內部輔助工具:您可以運用這項技術分析產品和使用者資料,發掘洞察資料,並據此採取更明智的行動。
預測式 AI 迴圈
預測型 AI 系統的開發遵循反覆循環: 定義商機、準備資料、訓練模型、評估模型, 以及部署模型。
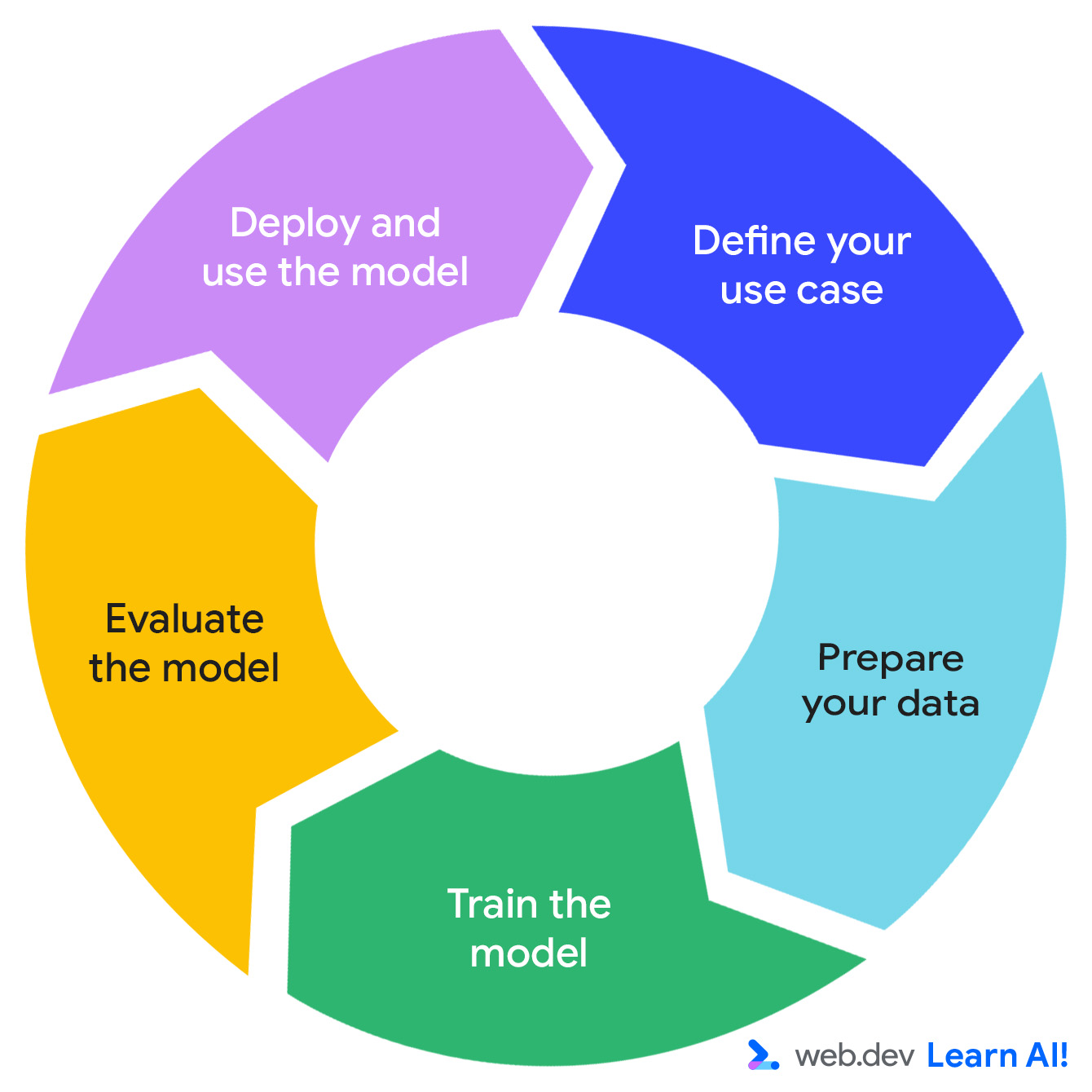
假設您正在開發以訂閱為基礎的生產力應用程式「Do All The Things」。您已收集網頁瀏覽次數、工作階段長度、功能使用情況和訂閱續訂等使用資料。現在,您希望從資料中擷取更多可做為行動依據的價值。以下說明如何透過預測式 AI 迴圈進行旅行。
定義用途
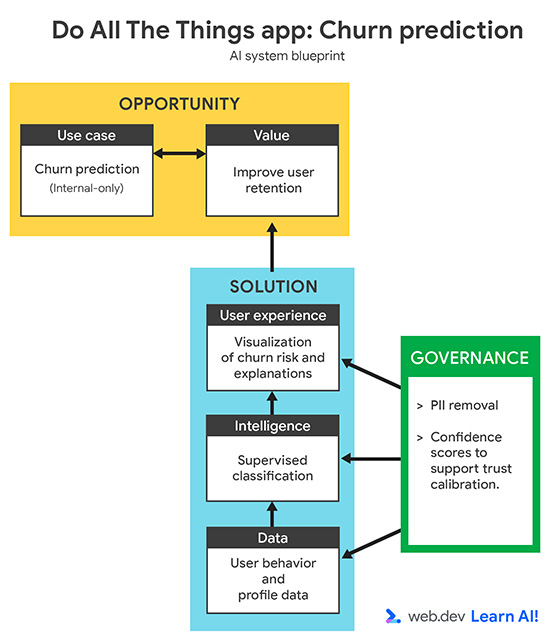
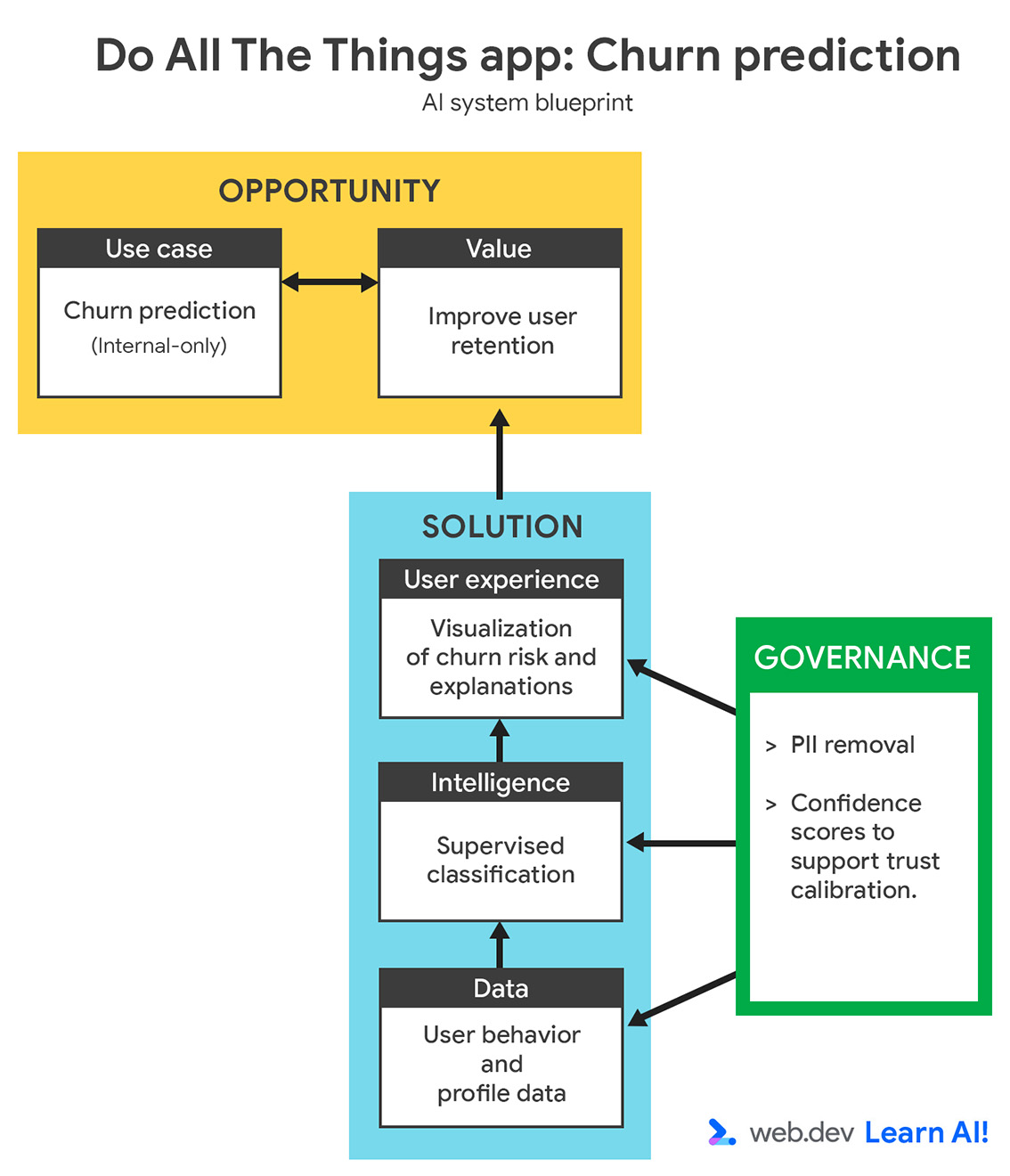{kind=link}
過去三個月,你的流失率有所增加。您想在使用者取消訂閱前,運用預測型 AI 找出可能流失的使用者,而不是在使用者取消訂閱後才採取行動。目標是透過早期信號支援客戶成功團隊,讓他們採取有針對性的主動行動,留住有流失風險的使用者。
定義預測型 AI 用途時,請先驗證資料是否能回答問題。這可以是您已收集的資料,也可以是您在未來可實際收集的資料。這個步驟通常需要與領域專家 (例如客戶成功、成長或行銷團隊) 合作,確保預測結果有意義且可做為行動依據。
明確的問題定義應指定:
- 目標:您想影響哪些業務成果?舉例來說,您想啟用主動式觸及功能,減少客戶流失。
- 輸入資料:模型會從哪些歷來信號中學習?例如,您提供使用模式、方案類型和支援互動。
- 輸出內容:模型會生成什麼內容?舉例來說,您希望模型為每位使用者建立流失機率分數。
- 使用者:誰會使用或根據預測結果採取行動?舉例來說,這項資料適用於客戶成功經理。
- 成功標準:如何評估影響力?舉例來說,您可以測量留存率,判斷是否已減少流失。
一開始就找出這些細節,可避免常見的陷阱:建立技術上健全,但從未使用的自訂模型。
準備資料
如要為模型提供實用的學習信號,您必須使用理想的預測結果標記歷來資料。將「Do All The Things」使用者標示為「流失」或「未流失」。
開始訓練前,請先投入時間清理及正規化資料。接著,與客戶成功團隊合作,找出與流失預測最相關的行為特徵。將資料集縮小至這些重要特徵,並移除不必要的欄位,這樣模型就不必處理雜訊。請務必考慮資料隱私權。移除個人識別資訊 (PII),例如姓名或電子郵件地址,只儲存匯總的行為資料。
下表顯示結果資料集的摘錄內容:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | Premium | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | 試用方案 | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | 免費 | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | Premium | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | 試用方案 | 4.2 | 2 | 1 | 3 | 1 |
這樣一來,模型就能獲得乾淨的數值和類別輸入內容 (例如 plan_type 或 avg_session_time),以及明確的目標標籤 (churned)。類別應轉換為不重複的數值 ID。
最後,將資料集分成三個子集:
- 訓練集 (通常約 70% 至 80%),用於訓練模型
- 驗證集 (有時也稱為開發集),用於調整超參數和避免過度擬合。
- 測試集:評估模型在完全未見過的資料上的表現。
這有助於模型概括決策,而非依賴記憶的歷史範例。
訓練模型
與生成式 AI (通常以大型預先訓練模型為基礎) 不同,大多數預測型 AI 系統都採用自行訓練的模型。這是因為預測工作與您的產品和使用者高度相關。scikit-learn (Python)、AutoML (無程式碼或低程式碼) 或 TensorFlow.js (JavaScript) 等工具,可簡化預測模型的訓練和評估程序,讓您不必擔心基礎數學問題。
在客戶流失範例中,我們會將經過清理的訓練集輸入監督式分類演算法,例如邏輯迴歸或類神經網路。請嘗試多種做法,找出最適合您資料的方式。
模型會學習哪些行為模式與流失相關。最後,系統會為每位使用者指派機率分數。舉例來說,使用者 X 下個月取消訂閱的風險為 72%。
每次訓練疊代後,請使用驗證集評估產生的模型。調整超參數可提升模型效能,但針對資料集進行改善也能達到相同效果。
評估模型
資料集中的標籤提供真值,可供您比較模型輸出內容。要追蹤的重要指標包括:
- 精確度:在所有標示為「流失」的使用者中,實際流失的使用者人數。
- 召回率:在所有流失的使用者中,模型抓到多少人?
- F1 分數:平衡精確度和喚回度的單一數字,可做為整體準確度的指標,避免為了提高其中一項指標而犧牲另一項。
誤判過多會浪費留存率提升工作的心力,誤判過少則會導致顧客流失。合適的取捨方式取決於您的業務優先事項。舉例來說,如果這樣做更有可能在使用者離開前抓住他們,貴公司可能會選擇處理幾個誤報。
部署及維護模型
驗證完成後,您可以使用 API 部署模型,或將模型整合至輕量型用戶端服務,並納入您的數據分析資訊主頁。這項功能每天都會為使用者評分,並更新流失風險的視覺化資料,方便團隊優先與高風險使用者聯絡。如要確保模型準確可靠,請採用機器學習運作 (MLOps) 團隊的經驗:
- 監控資料偏移:偵測使用者行為何時發生變化,以及訓練資料不再反映現實情況。
- 舉例來說,推出重大 UI 重新設計後,使用者與功能互動的方式會有所不同,導致流失預測的準確度降低。
- 從錯誤中學習:找出預測錯誤背後的常見模式,並加入目標範例,以利改善下一個訓練週期。
- 舉例來說,模型經常將超級使用者標示為流失風險,因為他們開啟了許多支援單。審查後,您新增了可區分疑難排解和互動率下降的新功能。
- 定期重新訓練:即使成效穩定,也請定期更新模型,以因應季節性趨勢、產品更新或價格變動。
- 舉例來說,推出年約方案後,您會重新訓練模型,因為價格結構變更會影響使用者續訂前的行為。
這個生命週期是預測式 AI 的骨幹。使用 MLflow 和 Weights & Biases 等工具,即使沒有深厚的機器學習專業知識,也能執行這項程序。
常見陷阱和防範措施
雖然偶爾會發生錯誤,但您可以防範常見的根本原因,避免影響成效和使用者信任度:
- 資料品質不佳:如果輸入資料有雜訊或不完整,預測結果也會如此。為減輕影響,請在訓練前以視覺化方式呈現及驗證資料。請確認您具備必要的學習信號,並處理遺漏值。監控正式環境中的資料品質。
過度配適:模型在訓練資料上表現優異,但無法處理新案例。如要減輕過度訓練的影響,請使用交叉驗證、正規化和保留資料集。這有助於模型根據訓練範例以外的資料進行歸納。
資料偏移:使用者行為和環境會改變,但模型不會。 為減輕影響,請安排重新訓練,並新增監控功能,偵測準確度何時開始下降。
不良指標:整體準確度不一定能反映使用者的優先事項。舉例來說,有時候特定錯誤的「成本」更重要。在詐欺偵測中,漏掉詐欺案件 (偽陰性) 的後果遠比標記無辜案件 (偽陽性) 嚴重。為減輕影響,請根據實際的詐欺偵測目標調整指標。
大多數問題都不會造成嚴重影響。逐步推出系統,並解決過程中出現的問題。
這種精簡彈性做法的關鍵在於可觀測性。為模型建立版本、記錄準確度特徵和用於建構模型的工具、追蹤一段時間內的成效,並持續監控。如果發生漂移或中斷情形,您就能在使用者發現前找出並修正問題。
重點摘要
預測型 AI 會將現有資料轉化為預測結果,揭露接下來可能發生的情況,以及應採取行動的領域。這是最具體且可衡量的 AI 形式。著重於可透過資料呈現的明確問題,並隨著產品演進不斷疊代,同時長期監控成效。
下一個單元將介紹生成式 AI,這項技術可根據現有資料建立新內容。
資源
如要瞭解預測型 AI 背後的數學原理,建議參閱下列資源:
- 機器學習密集課程:分類、線性迴歸和邏輯迴歸。
- 本課程的作者 Janna Lipenkova 在「The Art of AI Product Development: Delivering Business Value」一書的第 4 章中,進一步探討了預測型 AI 的主題。
- 人工智慧:現代方法 作者:Stuart Jonathan Russell 和 Peter Norvig。這本書最初於 1995 年出版,最新版本則於 2021 年發行。這項技術通常會在 AI 工程計畫中教授。
- 模式識別和機器學習,作者為 Christopher M. Bishop 撰寫的書籍,以深入淺出的方式介紹預測式 AI 學習。
隨堂測驗
預測型 AI 的主要功能是什麼?
哪項工作會根據模式將項目分入預先定義的類別?
在「預測型 AI 迴圈」中,為什麼要將資料集分割為訓練集、驗證集和測試集?
哪項指標會平衡精確度和喚回度,提供整體準確度評估?
什麼是資料偏移?如何減輕資料偏移的影響?