
Vos décisions de conception ont un impact direct sur la responsabilité et la sécurité de votre système d'IA. Par exemple, vous décidez comment sélectionner les sources de données, configurer le comportement du modèle ou présenter les résultats de l'IA aux utilisateurs. Ces choix ont des conséquences concrètes pour vos utilisateurs et votre entreprise.
Dans ce module, nous aborderons trois dimensions essentielles de la gouvernance de l'IA :
- Confidentialité : traitez les données de manière responsable, expliquez ce qui est collecté et minimisez ce qui quitte le navigateur.
- Équité : vérifiez que vos modèles ne présentent pas de comportement discriminatoire (biais) et créez des boucles permettant aux utilisateurs de signaler les problèmes.
- Confiance et transparence : concevez votre système pour qu'il soit transparent et inspire une confiance calibrée, afin que les utilisateurs continuent d'en bénéficier malgré l'incertitude et les erreurs potentielles.
Pour chaque thème, nous expliquons comment il se manifeste dans différents produits d'IA. Nous allons ensuite l'analyser en fonction des trois couches de votre solution d'IA : données, intelligence et expérience utilisateur. Vous découvrirez ce à quoi vous devez faire attention, comment résoudre les problèmes et comment maintenir une gouvernance efficace et légère.
Confidentialité
Vous avez appris que les données réelles d'utilisation et d'interaction sont au cœur de tout système d'IA. Les données permettent l'apprentissage, l'évaluation et l'amélioration continue. De bonnes pratiques de confidentialité vous permettent de protéger ces données, mais aussi de donner aux utilisateurs le contrôle de leurs informations.
Les attentes en matière de confidentialité varient considérablement en fonction de votre produit et de votre audience. Dans les produits destinés aux consommateurs, les attentes concernent généralement la protection des informations permettant d'identifier personnellement les utilisateurs, comme leur nom, leurs messages et leur comportement de navigation. Dans les paramètres d'entreprise, l'accent est mis sur la souveraineté, la confidentialité et la protection de la propriété intellectuelle des données.
Les secteurs qui affectent les moyens de subsistance ou le bien-être des personnes, comme la santé, la finance et l'éducation, exigent des mesures de protection de la confidentialité plus strictes que les domaines à faible risque, comme le divertissement.
Voyons comment gérer la confidentialité dans les différents composants de votre système d'IA.
Données
Pour améliorer en continu votre système d'IA, vous pouvez collecter des données sur les interactions des utilisateurs, y compris les entrées, les sorties, les commentaires et les erreurs. Ces informations peuvent être réutilisées pour l'évaluation, l'ajustement du modèle ou les exemples few-shot dans les requêtes. Elle peut également vous aider à concevoir l'expérience utilisateur.
Voici quelques consignes pour collecter des données de manière responsable :
- Ne collectez que les données nécessaires à l'apprentissage. Une recherche de produits optimisée par l'IA n'a pas forcément besoin du profil complet d'un utilisateur pour améliorer les résultats. Dans la plupart des cas, il suffit de fournir la requête, les schémas de clics et les données de session anonymisées.
- Supprimez les informations sensibles. Supprimez toutes les informations permettant d'identifier personnellement l'utilisateur avant d'envoyer des données à des modèles externes. Pour ce faire, vous pouvez anonymiser, pseudonymiser ou agréger les données.
- Limiter la fidélisation : Supprimez les journaux et les données mises en cache une fois qu'ils ont rempli leur fonction. Les cycles de rétention courts réduisent les risques sans bloquer les insights.
Documentez les informations que vous collectez, la durée pendant laquelle vous les conservez et la raison pour laquelle elles sont nécessaires. Si vous ne pouvez pas expliquer clairement vos flux de données à un utilisateur non technique, ils sont probablement trop complexes à contrôler ou à justifier.
Intelligence
Lorsque les utilisateurs interagissent avec votre système d'IA, ils peuvent saisir des informations privées ou sensibles sans le savoir ou par inadvertance. Ce risque est particulièrement élevé dans les interfaces de chat ou d'écriture ouvertes, où vous ne pouvez pas limiter ce que les utilisateurs saisissent.
Bien que vous puissiez empêcher l'envoi de certains mots, ces informations peuvent être sensibles au contexte. Si votre modèle s'exécute sur un serveur géré par un fournisseur externe, il est possible que celui-ci réutilise les saisies des utilisateurs comme données d'entraînement. À terme, le modèle peut révéler des fragments de texte privé, des identifiants ou d'autres informations confidentielles à d'autres utilisateurs.
Voici comment vous protéger contre les atteintes à la confidentialité lors de l'inférence :
Examinez attentivement les API tierces. Vous devez savoir exactement ce qu'il advient des données que vous envoyez. Les entrées sont-elles enregistrées, conservées ou réutilisées pour l'entraînement ? Évitez les services opaques et privilégiez les fournisseurs dont les règles et les contrôles sont transparents.
Si vous entraînez ou affinez vous-même des modèles, abstrayez les détails sensibles de vos données d'entraînement. Méfiez-vous de l'apprentissage par raccourci. Par exemple, dans une application de score de crédit, les codes postaux peuvent amener le modèle à faire des hypothèses sur l'origine ethnique ou le statut socio-économique. Cela peut entraîner des prédictions injustes et renforcer les inégalités existantes.
Dans les domaines sensibles, préférez l'inférence côté client. Cela peut se faire avec l'IA intégrée, un modèle dans le navigateur ou un modèle personnalisé côté client. Vous en saurez plus sur ce choix dans le prochain module, Choisir une plate-forme.
Expérience utilisateur
L'interface de votre application vous permet de montrer aux utilisateurs ce qui se passe, de gagner leur confiance et de leur donner le contrôle sur leurs données :
- Soyez transparent. Les libellés courts dans votre interface, tels que "Traitées localement" ou "Envoyées de manière sécurisée pour analyse", peuvent vous aider à gagner la confiance des utilisateurs. Envisagez d'ajouter une divulgation progressive pour plus de détails, comme des info-bulles qui expliquent quand l'analyse a lieu sur l'appareil ou sur un serveur.
- Demander en contexte : Demandez le consentement de l'utilisateur lorsque cela est pertinent. "Souhaitez-vous partager vos recherches précédentes pour améliorer les recommandations ?" est beaucoup plus pertinent qu'une option d'activation globale.
- Proposez des commandes simples. Ajoutez des boutons bascule clairement visibles pour la personnalisation, les fonctionnalités basées sur le cloud ou le partage de données.
- Accorder la visibilité Incluez un petit tableau de bord de confidentialité pour que les utilisateurs puissent gérer leurs données sans quitter l'application.
- Expliquez pourquoi vous collectez des données. Les utilisateurs sont plus susceptibles de partager des données s'ils comprennent comment elles seront utilisées. Il en va de même pour vos règles de conservation et de gestion.
La confidentialité dans l'IA Web n'est pas une simple étape de conformité, mais un état d'esprit de conception continu :
- Données : collectez moins de données et protégez-les davantage.
- Intelligence : atténuez la mémorisation de données potentiellement sensibles par les modèles externes.
- UX : rendez la confidentialité transparente et contrôlable pour les utilisateurs.
Équité
Les systèmes d'IA peuvent être biaisés et entraîner une discrimination injuste. C'est particulièrement vrai dans des domaines comme le recrutement, le droit et la finance, où les biais peuvent fausser des décisions critiques qui affectent directement de vraies personnes.
Par exemple, un modèle de recrutement entraîné sur des données de recrutement historiques pourrait associer certaines caractéristiques démographiques à une qualité de candidat inférieure, pénalisant involontairement les candidats issus de groupes sous-représentés, au lieu d'évaluer les compétences et l'expérience pertinentes pour le poste.
Données
Vos données d'entraînement sont un ensemble d'informations isolées individuellement qui peuvent refléter des biais du monde réel, voire en introduire de nouveaux. Voici des étapes pratiques pour rendre les biais liés aux données transparents et gérables :
- Documentez vos sources de données et votre couverture. Publiez un bref communiqué pour aider les utilisateurs à comprendre les limites du modèle. Par exemple, "Ce modèle a été principalement entraîné sur du contenu en anglais, avec une représentation limitée du texte technique."
- Exécutez des vérifications de diagnostic. Utilisez des tests A/B pour identifier les différences systématiques. Par exemple, comparez la façon dont votre système gère les phrases "C'est une excellente dirigeante", "C'est un excellent dirigeant" et "C'est une excellente dirigeante". De petits écarts dans le sentiment ou le ton peuvent révéler un biais plus profond.
- Ajoutez des libellés à vos ensembles de données. Ajoutez des métadonnées légères telles que le domaine, la région et le niveau de formalité pour faciliter les futurs audits, filtrages et rééquilibrages.
Si vous entraînez ou affinez des modèles personnalisés, équilibrez vos ensembles de données. Une représentation plus large réduit le biais plus efficacement que la correction du biais après la création du modèle.
Intelligence
Dans la couche Intelligence, le biais se transforme en comportement appris. Vous pouvez ajouter des mesures de protection, une logique de reclassification ou des règles hybrides pour orienter les résultats vers l'équité et l'inclusion :
- Testez régulièrement les biais. Utilisez des filtres de détection des biais pour signaler les formulations problématiques, comme les termes genrés ou le ton exclusif. Surveillez la dérive au fil du temps.
- Faites attention aux données sensibles pour les modèles prédictifs. Les attributs, tels que le code postal, le niveau d'études ou le revenu, peuvent encoder indirectement des caractéristiques sensibles, telles que l'origine ethnique ou la classe sociale.
- Générez et comparez plusieurs résultats. Classe les résultats en fonction de la neutralité, de la diversité et du ton, avant de déterminer quelle sortie partager avec l'utilisateur.
- Ajoutez des règles pour appliquer des contraintes d'équité. Par exemple, en bloquant les résultats qui renforcent les stéréotypes ou qui ne représentent pas des exemples diversifiés.
Expérience utilisateur
Dans votre interface utilisateur, soyez transparent sur le raisonnement du modèle et encouragez les commentaires :
- Fournissez des explications pour les résultats de l'IA. Par exemple, "Recommandation : ton professionnel, d'après vos saisies précédentes*." Cela permet aux utilisateurs de comprendre que le système suit une logique définie, et non un jugement caché.
- Donnez aux utilisateurs un contrôle pertinent. Permettez-leur d'ajuster le comportement du modèle à l'aide de paramètres ou de requêtes (par exemple, en choisissant des préférences de ton, de complexité ou de style visuel).
- Signaler plus facilement les biais ou les inexactitudes : Plus il est facile de signaler un problème, plus vous obtiendrez de données réelles pour améliorer votre système d'IA.
- Fermez la boucle de rétroaction. Ne laissez pas les signalements des utilisateurs disparaître. Réinjectez ces données dans votre logique de réentraînement ou de règles, et partagez vos progrès de manière visible : "Nous avons mis à jour notre modération pour réduire les biais culturels dans les recommandations."
Les biais sont présents dans les données, amplifiés par les modèles et mis en évidence dans l'expérience utilisateur. Vous pouvez l'aborder à tous les niveaux de votre système d'IA :
- Données : les sources de données doivent être transparentes et équilibrées.
- Intelligence : détecter, tester et atténuer les biais dans les résultats.
- Expérience utilisateur : permettez aux utilisateurs d'identifier et de corriger les biais grâce au contrôle et aux commentaires.
Confiance et transparence
La confiance détermine si les utilisateurs utilisent votre produit, l'adoptent et le recommandent.
La plupart des utilisateurs s'attendent à ce que les applications soient prévisibles. Par exemple, les clics sur les boutons effectuent toujours l'action indiquée et mènent au même endroit. L'IA ne répond pas à cette attente, car son comportement est très variable et souvent imprévisible. De plus, les systèmes d'IA ont un potentiel d'échec inhérent : les modèles de langage hallucinent des faits, les modèles prédictifs étiquettent mal les données et les agents deviennent incontrôlables.
Vos utilisateurs sont la dernière ligne de défense contre ces erreurs.
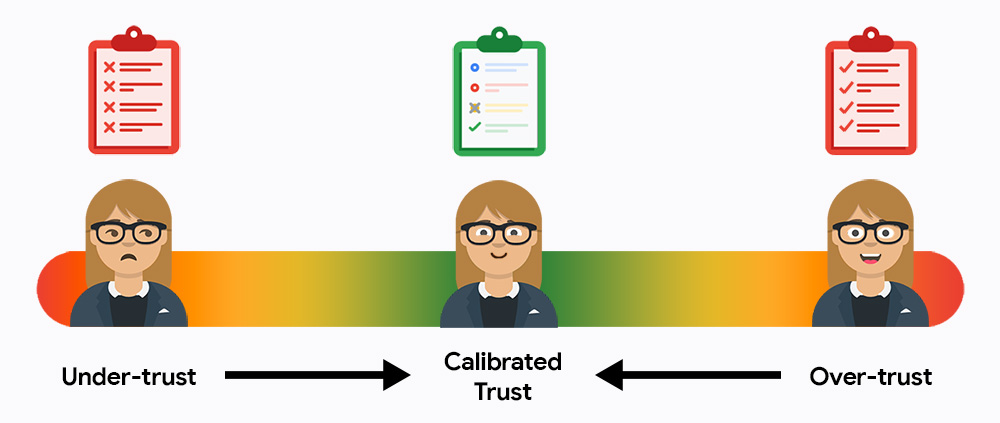
Au début, les utilisateurs ont probablement trop ou pas assez confiance dans votre système. Une confiance insuffisante signifie qu'ils n'utiliseront pas le système, tandis qu'une confiance excessive signifie qu'ils accepteront complètement les résultats, sans vérifier s'ils contiennent des erreurs. Votre tâche consiste à amener les utilisateurs au juste milieu de la confiance calibrée, où ils s'appuient sur l'IA pour gagner en efficacité tout en restant responsables des résultats finaux.
Données
Dans la couche de données, la confiance se construit en expliquant clairement la couverture et la provenance de vos données :
- Soyez explicite sur l'origine et la traçabilité des données.
- Documenter la fraîcheur et l'obsolescence des données.
- Décrivez les types de contenus que le modèle a vus et les domaines dans lesquels il peut rencontrer des difficultés, comme les données dans une autre langue que l'anglais.
À mesure que votre système d'IA accumule des interactions et des commentaires au fil du temps, pensez à conserver des instantanés versionnés des données pour pouvoir expliquer l'évolution des résultats.
Intelligence
Dans la couche Intelligence, vous pouvez gérer la confiance grâce à l'explicabilité, aux indicateurs de confiance et à la conception modulaire :
- Fournissez des explications contextuelles et ponctuelles. Selon le paradoxe de l'utilisateur actif, il est préférable d'intégrer des micro-explications contextuelles directement dans les interactions, afin que les utilisateurs comprennent ce que fait le système d'IA lorsqu'ils l'utilisent.
- Communiquez à l'avance les limites et les modes de défaillance. Indiquez aux utilisateurs où l'IA peut rencontrer des difficultés. Par exemple, "Évite l'humour ou le jargon spécifique à un domaine pour obtenir de meilleurs résultats." Des repères contextuels courts offrent de la transparence sans interrompre le flux.
- Les indicateurs de confiance et la logique de secours permettent à l'IA de rester fiable en cas d'incertitude. Vous pouvez estimer la confiance à partir de proxys, tels que les scores de probabilité ou les taux de réussite passés. Définissez des solutions de repli sûres pour les sorties manifestement incorrectes.
- Les architectures modulaires rendent l'IA plus transparente. Par exemple, si un assistant à la rédaction gère la grammaire, le style et le ton dans des étapes distinctes, indiquez ce qui a changé à chaque étape : "Ton : moins formel ; complexité : simplifiée".
Expérience utilisateur
L'expérience utilisateur vous offre un vaste terrain de jeu pour renforcer et calibrer la confiance. Voici quelques techniques et modèles à essayer :
- Adapter les contenus éducatifs Ne partez pas du principe que vos utilisateurs sont experts en IA. Fournissez des conseils simples aux utilisateurs expérimentés et des explications détaillées aux débutants.
- Appliquez la divulgation progressive. Commencez par de petits indices. Incluez un texte indiquant que vous avez utilisé l'IA, par exemple "Ce contenu a été généré automatiquement", et permettez aux utilisateurs de cliquer pour en savoir plus.
- Fermez les boucles de rétroaction avec des résultats visibles. Lorsque les utilisateurs évaluent, corrigent ou remplacent une suggestion de l'IA, expliquez-leur comment leur contribution façonne le comportement futur : "Vous avez préféré les réponses concises. J'ai adapté le ton en conséquence." La visibilité transforme les commentaires en confiance.
- Gérez les erreurs de façon optimale. Lorsque votre système commet une erreur ou fournit un résultat peu fiable, reconnaissez-le et demandez à l'utilisateur de l'examiner. Par exemple, "Cette suggestion ne correspond peut-être pas à votre intention. Vérifier avant de publier". Indiquez clairement la marche à suivre en permettant à l'utilisateur de réessayer, de modifier ou de revenir à une option de secours sûre.
En bref, pour faire face à l'incertitude et au potentiel d'erreur inhérent à l'IA, guidez les utilisateurs pour qu'ils calibrent correctement leur confiance, en évitant le doute ou la surconfiance :
- Données : soyez transparent sur la provenance des données.
- Intelligence : rendre le raisonnement modulaire et explicable.
- UX : concevez une expérience utilisateur qui offre une clarté et un feedback progressifs.
Vos points à retenir
Dans ce module, nous avons exploré trois piliers fondamentaux de l'IA responsable : la confidentialité, l'équité et la confiance. Cela peut sembler insurmontable, surtout lorsque vous débutez ou que vous essayez de passer du prototype à la production.
Concentrez vos efforts sur les domaines les plus critiques et définissez votre propre approche de la gouvernance de l'IA. L'itération est essentielle. Chaque version et chaque série de commentaires des utilisateurs vous permettront de mieux comprendre où votre système a besoin de plus de garde-fous, de transparence ou de flexibilité.
Ressources
Voici quelques ressources plus avancées sur les thèmes abordés dans ce module :
- Comparaison de la confidentialité et de la sécurité des assistants IA fournit des informations détaillées sur les règles de confidentialité de l'IA.
- Un article sur la mémorisation des LLM, un mode de défaillance critique en termes de confidentialité où un modèle conserve des informations spécifiques et sensibles issues de ses données d'entraînement et peut être invité à les reproduire.
- Examinez les ressources directement associées au modèle que vous choisissez. Par exemple, Google Cloud fournit des ressources de sécurité.
- La boîte à outils pour une IA responsable propose des ressources pour les développeurs sur tous les sujets abordés dans ce module.
Ressources
Voici quelques ressources plus avancées sur les thèmes abordés dans ce module :
- Comparaison de la confidentialité et de la sécurité des assistants IA : découvrez en détail les règles de confidentialité de l'IA.
- Un article sur la mémorisation des LLM, un mode de défaillance critique en termes de confidentialité où un modèle conserve des informations spécifiques et sensibles issues de ses données d'entraînement et peut être invité à les reproduire.
- Examinez les ressources directement associées au modèle que vous choisissez. Par exemple, Google Cloud fournit des ressources de sécurité.
- La boîte à outils pour une IA responsable propose des ressources pour les développeurs sur tous les sujets abordés dans ce module.
Vérifier que vous avez bien compris
Quelle est la bonne pratique recommandée en matière de confidentialité concernant la collecte de données pour l'IA ?
Qu'est-ce que la confiance calibrée ?
Pour garantir l'équité dans la couche "Intelligence", quelle action les développeurs peuvent-ils entreprendre ?
Quelle technique UX permet de renforcer la confiance et la transparence ?