
החלטות התכנון שלכם משפיעות ישירות על האחריות והבטיחות של מערכת ה-AI. לדוגמה, אתם מחליטים איך לבחור מקורות נתונים, לקבוע את אופן הפעולה של המודל או להציג למשתמשים את התוצאות של ה-AI. לבחירות האלה יש השלכות בעולם האמיתי על המשתמשים ועל החברה שלכם.
במודול הזה נסביר על שלושה היבטים חשובים של ניהול AI:
- פרטיות: טיפול אחראי בנתונים, הסבר על הנתונים שנאספים וצמצום כמות הנתונים שיוצאים מהדפדפן.
- הוגנות: כדאי לבדוק את המודלים שלכם כדי לוודא שהם לא מפלים (הטיה), וליצור לולאות שמאפשרות למשתמשים לסמן בעיות.
- אמינות ושקיפות: חשוב לעצב את המערכת כך שתהיה שקופה ואמינה, כדי שהמשתמשים ימשיכו ליהנות ממנה למרות אי-הוודאות והטעויות הפוטנציאליות.
בכל נושא מוסבר איך הוא בא לידי ביטוי במוצרי AI שונים. לאחר מכן, אנחנו מפרטים את ההמלצות לפי שלוש השכבות של פתרון ה-AI: נתונים, אינטליגנציה וחוויית משתמש. תלמדו מה צריך לבדוק, איך לטפל בבעיות ואיך לשמור על ניהול יעיל ופשוט.
פרטיות
למדתם שנתוני שימוש ואינטראקציה אמיתיים הם הבסיס של כל מערכת AI. הנתונים מאפשרים למידה, הערכה ושיפור מתמיד. שיטות טובות לשמירה על הפרטיות מאפשרות לכם לשמור על הנתונים האלה, אבל גם לתת למשתמשים שליטה על המידע שלהם.
הציפיות בנוגע לפרטיות משתנות מאוד בהתאם למוצר ולקהל. במוצרים לצרכנים, הציפיות בדרך כלל קשורות להגנה על פרטים אישיים מזהים (PII) של אנשים פרטיים, כמו שמות, הודעות והתנהגות גלישה. בהגדרות ארגוניות, הדגש עובר לריבונות נתונים, סודיות והגנה על קניין רוחני.
במגזרים שמשפיעים על פרנסתם או על רווחתם של אנשים, כמו בריאות, כספים וחינוך, נדרשים אמצעי הגנה מחמירים יותר על הפרטיות מאשר בתחומים עם סיכון נמוך יותר, כמו בידור.
נראה איך אפשר לנהל את הפרטיות ברכיבים השונים של מערכת ה-AI.
נתונים
כדי לשפר באופן מתמשך את מערכת ה-AI, אפשר לאסוף נתונים על האינטראקציות של המשתמשים, כולל קלט, פלט, משוב ושגיאות. אפשר לעשות שימוש חוזר במידע הזה לצורך הערכה, כוונון עדין של מודלים או דוגמאות של למידה עם הקשר מועט בהנחיות. הוא יכול גם לעזור לכם לעצב את חוויית המשתמש.
ריכזנו כאן כמה הנחיות לאיסוף נתונים אחראי:
- אוספים רק את מה שצריך לצורך למידה. יכול להיות שחיפוש מוצרים מבוסס-AI לא יצטרך את הפרופיל המלא של המשתמש כדי לשפר את התוצאות. ברוב המקרים, מספיק לספק את השאילתה, דפוסי הקליקים ונתוני הפעילות באתר שעברו אנונימיזציה.
- הסרת מידע רגיש. לפני ששולחים נתונים למודלים חיצוניים, צריך להסיר את כל הפרטים האישיים המזהים (PII). אפשר לעשות זאת באמצעות אנונימיזציה, פסאודונימיזציה או צבירה.
- הגבלת תקופת השמירה. מומלץ למחוק יומנים ונתונים שמאוחסנים במטמון אחרי שהם סיימו את התפקיד שלהם. מחזורי שמירה קצרים מפחיתים את הסיכון בלי לחסום את התובנות.
צריך לתעד איזה מידע אתם אוספים, כמה זמן אתם שומרים אותו ולמה הוא נחוץ. אם אתם לא יכולים להסביר בצורה ברורה את זרימות הנתונים למשתמש לא טכני, סביר להניח שהזרימות מורכבות מדי וקשה לשלוט בהן או להצדיק אותן.
Intelligence
כשמשתמשים מקיימים אינטראקציה עם מערכת ה-AI שלכם, הם עלולים להזין מידע פרטי או רגיש בלי לדעת או מתוך חוסר זהירות. הסיכון הזה גבוה במיוחד בממשקי צ'אט או כתיבה פתוחים, שבהם אי אפשר להגביל את מה שהמשתמשים מקלידים.
יכול להיות שתוכלו למנוע שליחה של מילים מסוימות, אבל המידע הזה עשוי להיות תלוי בהקשר. אם המודל שלכם פועל בשרת שמנוהל על ידי ספק חיצוני, יכול להיות שהספק ישתמש מחדש בקלט של המשתמשים כנתוני אימון. בסופו של דבר, יכול להיות שהמודל יחשוף בפני משתמשים אחרים קטעים של טקסט פרטי, פרטי כניסה או פרטים סודיים אחרים.
כך אפשר להגן על הפרטיות מפני פרצות במהלך ההסקה:
חשוב לבדוק בקפידה ממשקי API של צד שלישי. חשוב לדעת מה בדיוק קורה לנתונים שאתם שולחים. האם ערכי הקלט נרשמים ביומן, נשמרים או נעשה בהם שימוש חוזר לצורך אימון? מומלץ להימנע משירותים לא שקופים ולהעדיף ספקים עם מדיניות ובקרות שקופות.
אם אתם מאמנים או מכווננים מודלים בעצמכם, כדאי להסתיר פרטים רגישים בנתוני האימון. היזהרו מלימוד קיצורי דרך. לדוגמה, בבקשה לקבלת דירוג אשראי, מיקודים יכולים להוביל את המודל להניח הנחות לגבי גזע או מעמד סוציו-אקונומי. הדבר עלול להוביל לתחזיות לא הוגנות ולחיזוק של אי-שוויון קיים.
בדומיינים רגישים, עדיף להשתמש בהסקת מסקנות בצד הלקוח. אפשר לעשות את זה באמצעות AI מובנה, מודל בדפדפן או מודל בהתאמה אישית בצד הלקוח. מידע נוסף על הבחירה הזו זמין במודול הבא, בחירת פלטפורמה.
חוויית משתמש
ממשק האפליקציה מאפשר לכם להראות למשתמשים מה קורה, לזכות באמון שלהם ולתת להם שליטה בנתונים שלהם:
- שומרים על שקיפות. תוויות קצרות בממשק, כמו 'העיבוד מתבצע באופן מקומי' או 'הנתונים נשלחים בצורה מאובטחת לצורך ניתוח', יכולות לעזור לכם לבנות אמון. כדאי להוסיף גילוי הדרגתי של פרטים נוספים, כמו תיאורי כלים שמסבירים מתי מתבצעת ניתוח במכשיר ומתי בשרת.
- שואלים בהקשר. לבקש הסכמה כשזה רלוונטי. השאלה "רוצה לשתף את החיפושים הקודמים כדי לשפר את ההמלצות?" הרבה יותר משמעותית מהסכמה כללית.
- אמצעי בקרה פשוטים. הוספת מתגים גלויים בבירור להפעלה או להשבתה של התאמה אישית, תכונות מבוססות-ענן או שיתוף נתונים.
- הענקת הרשאות גישה. כדאי לכלול לוח בקרה קטן לפרטיות, כדי שהמשתמשים יוכלו לנהל את הנתונים שלהם בלי לצאת מהאפליקציה.
- הסבר למה אתם אוספים נתונים. יכול להיות שהמשתמשים יהיו יותר פתוחים לשיתוף נתונים אם הם יבינו איך ייעשה בהם שימוש. אותו עיקרון חל על מדיניות שמירת הנתונים ומדיניות הניהול.
הפרטיות ב-AI באינטרנט היא לא שלב אחד של תאימות, אלא גישה עיצובית מתמשכת:
- נתונים: איסוף של פחות נתונים והגנה טובה יותר עליהם.
- יכולות מתקדמות: צמצום הסיכון לשמירת נתונים רגישים פוטנציאליים במודלים חיצוניים.
- חוויית משתמש: חשוב שהמשתמשים יוכלו להבין את נושא הפרטיות ולשלוט בו.
יחס הוגן
מערכות AI יכולות להכיל הטיה שמובילה לאפליה לא הוגנת. זה נכון במיוחד בתחומים כמו גיוס עובדים, משפטים ופיננסים, שבהם הטיה יכולה לעוות החלטות קריטיות שמשפיעות ישירות על אנשים אמיתיים.
לדוגמה, מודל לגיוס עובדים שאומן על נתוני גיוס היסטוריים יכול לקשר בין מאפיינים דמוגרפיים מסוימים לבין איכות נמוכה יותר של מועמדים, ובכך לפגוע במועמדים מקבוצות לא מיוצגות, במקום להעריך את הכישורים והניסיון שרלוונטיים למשרה.
נתונים
נתוני האימון הם קבוצה של פריטי מידע מבודדים שיכולים לשקף הטיה מהעולם האמיתי, ואפילו להציג הטיה חדשה. אלה שלבים מעשיים שיעזרו לכם להפוך את ההטיות שקשורות לנתונים לשקופות ולניתנות לניהול:
- תיעוד של מקורות הנתונים והכיסוי. פרסום הצהרה קצרה שתעזור למשתמשים להבין איפה המודל עלול להיכשל. לדוגמה, "המודל הזה אומן בעיקר על תוכן בשפה האנגלית, עם ייצוג מוגבל של טקסט טכני".
- הפעלת בדיקות אבחון. משתמשים בבדיקות A/B כדי לזהות הבדלים שיטתיים. לדוגמה, אפשר להשוות בין התגובות של המערכת למשפטים 'She is a great leader', 'He is a great leader' ו-'They are a great leader'. הבדלים קטנים בסנטימנט או בטון יכולים להצביע על הטיה עמוקה יותר.
- מתייגים את מערכי הנתונים. כדאי להוסיף מטא-נתונים קלים כמו דומיין, אזור ורמת רשמיות, כדי שבעתיד יהיה קל לבצע ביקורות, סינון ואיזון מחדש.
אם אתם מאמנים מודלים בהתאמה אישית או מבצעים להם כוונון עדין, הקפידו על איזון בין מערכי הנתונים. ייצוג רחב יותר מפחית את ההטיה בצורה יעילה יותר מאשר תיקון ההטיה אחרי בניית המודל.
Intelligence
בשכבת ה-AI, הטיה הופכת להתנהגות נלמדת. אתם יכולים להוסיף אמצעי הגנה, לוגיקה של דירוג מחדש או כללים היברידיים כדי להטות את התוצאות לכיוון של הוגנות והכללה:
- בדיקה שוטפת של הטיה. אפשר להשתמש במסננים לזיהוי הטיה כדי לסמן ניסוחים בעייתיים, כמו מונחים שמפלים בין המינים או ניסוחים שיוצרים תחושת ניכור. מעקב אחרי סחף לאורך זמן.
- כשמשתמשים במודלים חזויים, צריך להיזהר עם מידע אישי רגיש. מאפיינים כמו מיקוד, השכלה או הכנסה יכולים לקודד באופן עקיף מאפיינים רגישים כמו גזע או מעמד.
- יצירה והשוואה של כמה פלטים. לדרג את התוצאות על סמך ניטרליות, מגוון וטון, לפני שקובעים איזו תוצאה לשתף עם המשתמש.
- הוספת כללים לאכיפת אילוצי הוגנות לדוגמה, חסימת פלטים שמחזקים סטריאוטיפים או שלא מייצגים דוגמאות מגוונות.
חוויית משתמש
בממשק המשתמש, חשוב לנהוג בשקיפות לגבי ההיגיון של המודל ולעודד משוב:
- לספק הסברים לתוצאות של AI. לדוגמה, "מומלץ להשתמש בסגנון מקצועי על סמך הקלט הקודם שלך*". כך המשתמשים יכולים לראות שהמערכת פועלת לפי לוגיקה מוגדרת, ולא לפי שיקול דעת נסתר.
- לתת למשתמשים שליטה משמעותית. לאפשר להם להתאים את התנהגות המודל באמצעות הגדרות או הנחיות – למשל, בחירת העדפות לגבי הטון, המורכבות או הסגנון החזותי.
- הוספנו אפשרות לדווח על הטיה או על חוסר דיוק. ככל שקל יותר לסמן בעיה, כך תקבלו יותר נתונים מהעולם האמיתי שיעזרו לכם לשפר את מערכת ה-AI.
- סוגרים את לולאת המשוב. אל תאפשרו לדיווחים של משתמשים להיעלם. השתמשו בנתונים האלה כדי לאמן מחדש את המודל או לשפר את הלוגיקה של הכללים, ושתפו את ההתקדמות באופן גלוי: "עדכנו את תהליך הבדיקה שלנו כדי לצמצם את ההטיה התרבותית בהמלצות".
ההטיה נוצרת בנתונים, מוגברת באמצעות מודלים ומוצגת בחוויית המשתמש. אתם יכולים לטפל בבעיה בכל שלוש הרמות של מערכת ה-AI:
- נתונים: מקורות הנתונים צריכים להיות שקופים ומאוזנים.
- אינטליגנציה: זיהוי, בדיקה וצמצום של הטיה בפלט.
- חוויית משתמש: לאפשר למשתמשים לזהות ולתקן הטיה באמצעות בקרה ומשוב.
אמון ושקיפות
האמון קובע אם אנשים ישתמשו במוצר שלכם, יאמצו אותו וימליצו עליו.
רוב המשתמשים מצפים שאפליקציות יפעלו בצורה צפויה. לדוגמה, קליקים על כפתורים תמיד מבצעים את הפעולה שמצוינת, ומובילים לאותו מקום. ה-AI לא עומד בציפייה הזו, כי ההתנהגות שלו משתנה מאוד ולעתים קרובות היא בלתי צפויה. בנוסף, יש למערכות AI פוטנציאל מובנה לכשלים: מודלים של שפה ממציאים עובדות, מודלים חיזויים מסווגים נתונים בצורה שגויה וסוכנים מתנהגים בצורה לא צפויה.
המשתמשים הם קו ההגנה האחרון מפני השגיאות האלה.
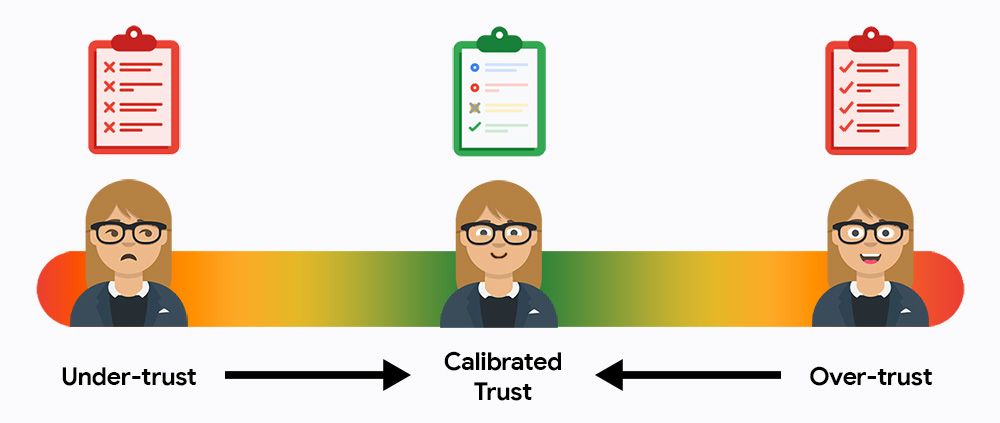
בהתחלה, סביר להניח שהמשתמשים לא יסמכו על המערכת שלכם או יסמכו עליה יותר מדי. אם הם לא יסמכו על המערכת, הם לא ישתמשו בה. אם הם יסמכו עליה יותר מדי, הם יקבלו את התוצאות בלי לבדוק אם יש בהן שגיאות. המשימה שלכם היא למשוך את המשתמשים אל אמצע הזהב של אמון מדויק, שבו הם מסתמכים על AI כדי לשפר את היעילות, אבל עדיין לוקחים אחריות על התוצאות הסופיות.
נתונים
בשכבת הנתונים, האמון נבנה על ידי הסבר ברור לגבי הכיסוי והמקור של הנתונים:
- צריך לציין במפורש את מקור הנתונים ואת השושלת שלו.
- עדכניות הנתונים במסמך.
- תאר את סוגי התוכן שהמודל ראה ואת המקומות שבהם המודל עשוי להתקשות, כמו נתונים בשפה שאינה אנגלית.
ככל שמערכת ה-AI צוברת אינטראקציות ומשוב לאורך זמן, כדאי לשמור תמונות מצב של הנתונים עם מספור גרסאות, כדי שתוכלו להסביר איך הפלט התפתח.
Intelligence
בשכבת ה-AI, אפשר לנהל את האמון באמצעות הסברים, אינדיקטורים של רמת הסמך ועיצוב מודולרי:
- הסברים בהתאם להקשר ובזמן הנכון. לפי הפרדוקס של המשתמש הפעיל, עדיף להטמיע הסברים קצרים בהקשר, ישירות באינטראקציות, כדי שהמשתמשים יבינו מה מערכת ה-AI עושה בזמן שהם משתמשים בה.
- חשוב להסביר מראש על המגבלות ועל מצבי הכשל. צריך להסביר למשתמשים איפה יכולות להיות בעיות ב-AI. לדוגמה, "כדי לקבל תוצאות טובות יותר, כדאי להימנע מהומור או מז'רגון ספציפי לתחום". רמזים קצרים לפי הקשר מספקים שקיפות בלי לפגוע ברצף.
- אינדיקטורים של רמת מהימנות ולוגיקה של חלופות עוזרים לשמור על מהימנות ה-AI גם במצבים של חוסר ודאות. אפשר לאמוד את רמת הביטחון באמצעות נתונים עקיפים, כמו ציוני הסתברות או שיעורי הצלחה קודמים. הגדרת חלופות בטוחות לתשובות שהן שגויות באופן ברור.
- ארכיטקטורות מודולריות משפרות את השקיפות של ה-AI. לדוגמה, אם עוזר כתיבה מטפל בדקדוק, בסגנון ובטון בשלבים נפרדים, צריך לציין מה השתנה בכל שלב: 'טון: פחות רשמי; מורכבות: פשוטה יותר'.
חוויית משתמש
חוויית המשתמש מספקת לכם מרחב עצום לבנייה ולכיול של אמון. ריכזנו כאן כמה טכניקות ודפוסים שאפשר לנסות:
- התאמת תוכן חינוכי. אל תניחו שהמשתמשים שלכם מבינים ב-AI. לספק הנחיות פשוטות למשתמשים מתקדמים והסברים מפורטים למתחילים.
- החלת חשיפה הדרגתית. מתחילים עם רמזים קטנים. כדאי לכלול תוכן שבו מצוין שהשתמשתם ב-AI, למשל: "התוכן הזה נוצר באופן אוטומטי", ולאפשר למשתמשים ללחוץ כדי לקבל תובנות נוספות.
- סגירת לולאות משוב עם תוצאות גלויות. כשמשתמשים מדרגים, מתקנים או מבטלים הצעה של AI, כדאי לשתף איך הקלט שלהם משפיע על ההתנהגות העתידית: 'העדפת תשובות תמציתיות. התאמתי את הטון בהתאם". החשיפה הופכת את המשוב לאמון.
- טיפול בשגיאות בצורה חלקה. אם המערכת טועה או נותנת תוצאה עם רמת מהימנות נמוכה, צריך להודות בטעות ולהעביר את הבדיקה למשתמש. לדוגמה, "יכול להיות שההצעה הזו לא תואמת לכוונת החיפוש שלך. בדיקה לפני הפרסום". צריך לספק למשתמשים אפשרות ברורה לנסות שוב, לערוך או לחזור לגיבוי בטוח.
בקיצור, כדי להתמודד עם אי הוודאות ועם הפוטנציאל לשגיאות שמאפיינים את ה-AI, צריך להנחות את המשתמשים כך שהם לא יטילו ספק או יסתמכו יותר מדי על ה-AI, אלא יפתחו בו אמון מושכל:
- נתונים: חשוב להיות שקופים לגבי מקור הנתונים.
- אינטליגנציה: להפוך את ההסקה למודולרית ולניתנת להסבר.
- UX: עיצוב שמאפשר בהירות ומשוב הדרגתיים.
התובנות שלכם
במודול הזה, בחנו שלושה עקרונות מרכזיים של AI אחראי: פרטיות, הוגנות ואמון. יכול להיות שזה ייראה לכם כמו עומס גדול מדי, במיוחד אם אתם רק מתחילים או מנסים לעבור משלב האב-טיפוס לשלב הייצור.
מומלץ למקד את המאמצים בתחומים החשובים ביותר ולהגדיר גישה משלכם לניהול AI. חשוב לבצע איטרציות. כל גרסה וכל סבב של משוב משתמשים יעזרו לכם להבין טוב יותר איפה המערכת שלכם צריכה יותר אמצעי הגנה, שקיפות או גמישות.
משאבים
ריכזנו כאן כמה מקורות מידע מתקדמים יותר בנושאים שמופיעים במודול הזה:
- השוואה בין מדיניות הפרטיות והאבטחה של עוזרים מבוססי-AI כוללת סקירה מפורטת של מדיניות הפרטיות של AI.
- מאמר בנושא שמירת מידע בזיכרון של LLM, מצב קריטי של כשל בפרטיות שבו מודל שומר מידע ספציפי ורגיש מנתוני האימון שלו, ואפשר להנחות אותו לשחזר את המידע הזה.
- בודקים את המשאבים שמשויכים ישירות למודל שבחרתם. לדוגמה, Google Cloud מספק משאבי אבטחה.
- ערכת הכלים לאחריות ב-AI כוללת משאבים למפתחים בנושאים שכיסינו במודול הזה.
משאבים
ריכזנו כאן כמה מקורות מידע מתקדמים יותר בנושאים שמופיעים במודול הזה:
- השוואה בין מדיניות הפרטיות והאבטחה של העוזר הדיגיטלי מבוסס-AI כוללת סקירה מפורטת של מדיניות הפרטיות של AI.
- מאמר בנושא זיכרון של LLM, מצב קריטי של כשל בפרטיות שבו מודל שומר מידע ספציפי ורגיש מנתוני האימון שלו, ואפשר להנחות אותו לשחזר את המידע הזה.
- בודקים את המשאבים שמשויכים ישירות למודל שבחרתם. לדוגמה, ב-Google Cloud יש משאבי אבטחה.
- ערכת הכלים לאחריות ב-AI כוללת משאבים למפתחים בנושאים שכיסינו ביחידה הזו.
בדיקת ההבנה
מהו נוהל מומלץ לשמירה על פרטיות בנוגע לאיסוף נתונים לצורך AI?
מהו אמון מדורג?
כדי להבטיח הוגנות בשכבת ה-Intelligence, איזו פעולה יכולים מפתחים לבצע?
מהי טכניקת UX לבניית אמון ושקיפות?