
การตัดสินใจด้านการออกแบบของคุณจะกำหนดความรับผิดชอบและความปลอดภัยของระบบ AI โดยตรง เช่น คุณตัดสินใจวิธีเลือกแหล่งข้อมูล กำหนดค่าลักษณะการทำงานของโมเดล หรือนำเสนอเอาต์พุต AI ต่อผู้ใช้ ตัวเลือกเหล่านี้ส่งผลกระทบต่อผู้ใช้และบริษัทของคุณในโลกแห่งความเป็นจริง
ในโมดูลนี้ เราจะพูดถึงมิติที่สำคัญ 3 ด้านของการกํากับดูแล AI ดังนี้
- ความเป็นส่วนตัว: จัดการข้อมูลอย่างมีความรับผิดชอบ อธิบายสิ่งที่เก็บรวบรวม และลด สิ่งที่ออกจากเบราว์เซอร์
- ความเป็นธรรม: ตรวจสอบโมเดลว่ามีพฤติกรรมที่เลือกปฏิบัติ (อคติ) หรือไม่ และสร้าง ลูปที่ให้ผู้ใช้แจ้งปัญหา
- ความไว้วางใจและความโปร่งใส: ออกแบบระบบให้มีความโปร่งใสและมีความไว้วางใจที่ปรับเทียบแล้ว เพื่อให้ผู้ใช้ได้รับประโยชน์จากระบบต่อไปแม้จะมีความไม่แน่นอนและข้อผิดพลาดที่อาจเกิดขึ้น
สำหรับแต่ละหัวข้อ เราจะอธิบายว่าหัวข้อนั้นๆ ปรากฏในผลิตภัณฑ์ AI ต่างๆ อย่างไร จากนั้นเราจะแบ่งออกเป็น 3 เลเยอร์ของโซลูชัน AI ได้แก่ ข้อมูล ข้อมูลอัจฉริยะ และประสบการณ์ของผู้ใช้ คุณจะได้เรียนรู้สิ่งที่ต้องระวัง วิธีแก้ไขปัญหา และวิธีรักษาการกำกับดูแลที่มีประสิทธิภาพและน้ำหนักเบา
ความเป็นส่วนตัว
คุณได้ทราบว่าข้อมูลการใช้งานและการโต้ตอบจริงคือหัวใจสำคัญของระบบ AI ข้อมูลขับเคลื่อนการเรียนรู้ การประเมิน และการปรับปรุงอย่างต่อเนื่อง แนวทางปฏิบัติที่ดีด้านความเป็นส่วนตัวช่วยให้คุณรักษาข้อมูลดังกล่าวให้ปลอดภัย แต่ก็ยังช่วยให้ผู้ใช้ควบคุมข้อมูลของตนเองได้ด้วย
ความคาดหวังด้านความเป็นส่วนตัวจะแตกต่างกันอย่างมากโดยขึ้นอยู่กับผลิตภัณฑ์และกลุ่มเป้าหมาย ใน ผลิตภัณฑ์สำหรับผู้บริโภค ความคาดหวังมักเกี่ยวข้องกับการปกป้องข้อมูลส่วนบุคคลที่ระบุตัวบุคคลนั้นได้ (PII) ของบุคคล เช่น ชื่อ ข้อความ และพฤติกรรมการท่องเว็บ ในการตั้งค่าระดับองค์กร โฟกัสจะเปลี่ยนไปที่อธิปไตยของข้อมูล ความลับ และการคุ้มครองทรัพย์สินทางปัญญา
ภาคส่วนที่ส่งผลต่อการดำรงชีวิตหรือคุณภาพชีวิตของผู้คน เช่น การดูแลสุขภาพ การเงิน และการศึกษา จำเป็นต้องมีมาตรการปกป้องความเป็นส่วนตัวที่เข้มงวดกว่าภาคส่วนที่มีความเสี่ยงต่ำกว่า เช่น ความบันเทิง
มาดูกันว่าคุณจะจัดการความเป็นส่วนตัวในคอมโพเนนต์ต่างๆ ของระบบ AI ได้อย่างไร
ข้อมูล
คุณสามารถรวบรวมข้อมูลเกี่ยวกับการโต้ตอบของผู้ใช้ ซึ่งรวมถึงอินพุต เอาต์พุต ความคิดเห็น และข้อผิดพลาด เพื่อปรับปรุงระบบ AI อย่างต่อเนื่อง ข้อมูลนี้ สามารถนำกลับมาใช้ซ้ำเพื่อการประเมิน การปรับแต่งโมเดล หรือตัวอย่างแบบไม่กี่ช็อตใน พรอมต์ได้ และยังช่วยในการออกแบบ UX ได้ด้วย
หลักเกณฑ์บางประการสำหรับการเก็บรวบรวมข้อมูลอย่างมีความรับผิดชอบมีดังนี้
- รวบรวมเฉพาะสิ่งที่จำเป็นสำหรับการเรียนรู้ การค้นหาผลิตภัณฑ์ที่ทำงานด้วยระบบ AI อาจไม่จำเป็นต้องใช้โปรไฟล์แบบเต็มของผู้ใช้เพื่อปรับปรุงผลลัพธ์ ในกรณีส่วนใหญ่ การระบุรูปแบบการค้นหา รูปแบบการคลิก และข้อมูลเซสชันที่ไม่ระบุตัวตนก็เพียงพอแล้ว
- ลบข้อมูลที่ละเอียดอ่อน นำ PII (ข้อมูลส่วนบุคคลที่ระบุตัวบุคคลนั้นได้) ทั้งหมดออกก่อนส่งข้อมูลไปยังโมเดลภายนอก ซึ่งทำได้โดยการไม่ระบุตัวตน การใช้นามแฝง หรือการรวบรวมข้อมูล
- จำกัดการเก็บรักษา ลบบันทึกและข้อมูลที่แคชไว้เมื่อหมดประโยชน์แล้ว รอบการเก็บรักษาที่สั้นจะช่วยลดความเสี่ยงโดยไม่บล็อกข้อมูลเชิงลึก
บันทึกข้อมูลที่คุณเก็บรวบรวม ระยะเวลาที่คุณเก็บข้อมูล และเหตุผลที่ต้องเก็บข้อมูล หากคุณอธิบายโฟลว์ของข้อมูลให้ผู้ใช้ที่ไม่ใช่ผู้เชี่ยวชาญด้านเทคนิคเข้าใจได้ไม่ชัดเจน โฟลว์นั้นอาจซับซ้อนเกินกว่าจะควบคุมหรือพิสูจน์ได้
การตรวจหา
เมื่อผู้ใช้โต้ตอบกับระบบ AI ของคุณ ผู้ใช้อาจป้อนข้อมูลส่วนตัวหรือข้อมูลที่ละเอียดอ่อนโดยไม่รู้ตัวหรือโดยไม่ระมัดระวัง ความเสี่ยงนี้จะสูงเป็นพิเศษใน อินเทอร์เฟซการแชทหรือการเขียนแบบเปิด ซึ่งคุณไม่สามารถจำกัดสิ่งที่ผู้ใช้พิมพ์ได้
แม้ว่าคุณจะป้องกันไม่ให้มีการส่งคำบางคำได้ แต่ข้อมูลนี้ อาจมีความละเอียดอ่อนตามบริบท หากโมเดลของคุณทำงานบนเซิร์ฟเวอร์ที่จัดการโดยผู้ให้บริการภายนอก ผู้ให้บริการอาจนำอินพุตของผู้ใช้มาใช้ซ้ำเป็นข้อมูลการฝึก ในที่สุด โมเดลอาจเปิดเผยข้อความส่วนตัว ข้อมูลเข้าสู่ระบบ หรือรายละเอียดอื่นๆ ที่เป็นความลับ ต่อผู้ใช้รายอื่น
วิธีป้องกันการละเมิดความเป็นส่วนตัวระหว่างการอนุมานมีดังนี้
ตรวจสอบ API ของบุคคลที่สามอย่างละเอียด คุณควรรู้แน่ชัดว่าเกิดอะไรขึ้นกับ ข้อมูลที่คุณส่ง ระบบจะบันทึก เก็บรักษา หรือนำอินพุตไปใช้ซ้ำเพื่อการฝึกไหม หลีกเลี่ยงบริการที่ไม่โปร่งใสและเลือกผู้ให้บริการที่มีนโยบายและการควบคุมที่โปร่งใส
หากคุณฝึกหรือปรับแต่งโมเดลด้วยตนเอง ให้หลีกเลี่ยงรายละเอียดที่ละเอียดอ่อนในข้อมูลการฝึก ระวังการเรียนรู้แบบลัด เช่น ใน การสมัครขอคะแนนเครดิต รหัสไปรษณีย์อาจทำให้โมเดลคาดเดา เกี่ยวกับเชื้อชาติหรือสถานะทางเศรษฐกิจและสังคม ซึ่งอาจส่งผลให้เกิดการคาดการณ์ที่ไม่เป็นธรรมและ ตอกย้ำความไม่เท่าเทียมที่มีอยู่
ในโดเมนที่มีความละเอียดอ่อน ให้ใช้การอนุมานฝั่งไคลเอ็นต์ ซึ่งอาจเป็นAI ในตัว โมเดลในเบราว์เซอร์ หรือโมเดลฝั่งไคลเอ็นต์ที่กำหนดเอง คุณจะได้ดูข้อมูลเพิ่มเติม เกี่ยวกับตัวเลือกนี้ในโมดูลถัดไป การเลือกแพลตฟอร์ม
ประสบการณ์ของผู้ใช้
อินเทอร์เฟซของแอปพลิเคชันเป็นโอกาสในการแสดงให้ผู้ใช้เห็นสิ่งที่เกิดขึ้น สร้างความไว้วางใจ และให้ผู้ใช้ควบคุมข้อมูลของตนเองได้
- มีความโปร่งใส ป้ายกำกับสั้นๆ ในอินเทอร์เฟซ เช่น "ประมวลผลในเครื่อง" หรือ "ส่งอย่างปลอดภัยเพื่อการวิเคราะห์" จะช่วยสร้างความน่าเชื่อถือได้ พิจารณาเพิ่ม การเปิดเผยข้อมูลแบบค่อยเป็นค่อยไปเพื่อดูรายละเอียดเพิ่มเติม เช่น เคล็ดลับเครื่องมือที่อธิบายว่าเมื่อใดที่ การวิเคราะห์เกิดขึ้นในอุปกรณ์เทียบกับเซิร์ฟเวอร์
- ถามในบริบท ขอความยินยอมเมื่อเกี่ยวข้อง "คุณต้องการ แชร์การค้นหาก่อนหน้าเพื่อปรับปรุงคำแนะนำไหม" มีความหมายมากกว่า การเลือกเข้าร่วมแบบครอบคลุม
- มีตัวควบคุมที่ใช้งานง่าย เพิ่มปุ่มเปิด/ปิดที่มองเห็นได้ชัดเจนสำหรับการปรับเปลี่ยนในแบบของคุณ ฟีเจอร์บนระบบคลาวด์ หรือการแชร์ข้อมูล
- ให้สิทธิ์ระดับการเข้าถึง ใส่แดชบอร์ดความเป็นส่วนตัวขนาดเล็กเพื่อให้ผู้ใช้จัดการ ข้อมูลได้โดยไม่ต้องออกจากแอป
- อธิบายเหตุผลที่ต้องเก็บรวบรวมข้อมูล ผู้ใช้อาจเต็มใจแชร์ข้อมูลมากขึ้นหาก เข้าใจวิธีใช้ข้อมูล นโยบายการเก็บรักษาและการจัดการก็เช่นกัน
ความเป็นส่วนตัวใน AI บนเว็บไม่ใช่ขั้นตอนการปฏิบัติตามข้อกำหนดเพียงขั้นตอนเดียว แต่เป็นแนวคิดการออกแบบที่ต้องดำเนินการอย่างต่อเนื่อง
- ข้อมูล: เก็บข้อมูลให้น้อยลงและปกป้องข้อมูลให้มากขึ้น
- ความสามารถในการวิเคราะห์: ลดการจดจำข้อมูลที่อาจมีความละเอียดอ่อนโดยโมเดลภายนอก
- ประสบการณ์ของผู้ใช้: ทำให้ผู้ใช้เห็นความเป็นส่วนตัวอย่างโปร่งใสและควบคุมได้
ความยุติธรรม
ระบบ AI อาจมีอคติที่นำไปสู่การเลือกปฏิบัติที่ไม่เป็นธรรม โดยเฉพาะอย่างยิ่งในโดเมนต่างๆ เช่น การจ้างงาน กฎหมาย และการเงิน ซึ่งอคติอาจทำให้การตัดสินใจที่สำคัญซึ่งส่งผลกระทบโดยตรงต่อผู้คนจริงเกิดความคลาดเคลื่อน
ตัวอย่างเช่น โมเดลการจ้างงานที่ฝึกกับข้อมูลการสรรหาบุคลากรในอดีตอาจ เชื่อมโยงลักษณะข้อมูลประชากรบางอย่างกับคุณภาพของผู้สมัครที่ต่ำกว่า โดยไม่ได้ตั้งใจที่จะลงโทษผู้สมัครจากกลุ่มที่ได้รับการเป็นตัวแทนน้อย แทนที่จะ ประเมินทักษะและประสบการณ์ที่เกี่ยวข้องกับงาน
ข้อมูล
ข้อมูลการฝึกเป็นชุดข้อมูลที่แยกกันแต่ละรายการ ซึ่งอาจแสดงอคติจากโลกแห่งความเป็นจริง และอาจทำให้เกิดอคติใหม่ๆ ด้วย ขั้นตอนที่ใช้ได้จริงในการทำให้ความลำเอียงที่เกี่ยวข้องกับข้อมูลมีความโปร่งใสและจัดการได้มีดังนี้
- บันทึกแหล่งข้อมูลและความครอบคลุม เผยแพร่คำชี้แจงสั้นๆ เพื่อ ช่วยให้ผู้ใช้เข้าใจข้อจำกัดของโมเดล เช่น "โมเดลนี้ได้รับการฝึกโดยใช้เนื้อหาภาษาอังกฤษเป็นหลัก โดยมีข้อความทางเทคนิคเป็นตัวแทนในจำนวนจำกัด"
- เรียกใช้การตรวจสอบการวินิจฉัย ใช้การทดสอบ A/B เพื่อดูความแตกต่างอย่างเป็นระบบ เช่น เปรียบเทียบว่าระบบจัดการกับข้อความ "เธอเป็นผู้นำที่ยอดเยี่ยม" "เขาเป็นผู้นำที่ยอดเยี่ยม" และ "พวกเขาเป็นผู้นำที่ยอดเยี่ยม" อย่างไร ความคลาดเคลื่อนเล็กน้อยใน ความรู้สึกหรือน้ำเสียงอาจเป็นสัญญาณของอคติที่ลึกซึ้งกว่า
- ติดป้ายกำกับชุดข้อมูล เพิ่มข้อมูลเมตาที่มีขนาดเล็ก เช่น โดเมน ภูมิภาค และระดับความเป็นทางการ เพื่อให้การตรวจสอบ การกรอง และการปรับสมดุลในอนาคต เป็นไปอย่างตรงไปตรงมา
หากคุณกำลังฝึกหรือปรับแต่งโมเดลที่กำหนดเอง ให้ปรับสมดุลชุดข้อมูล การเป็นตัวแทนที่กว้างขึ้น ช่วยลดความเบ้ได้อย่างมีประสิทธิภาพมากกว่าการแก้ไขอคติหลังจากสร้างโมเดล แล้ว
การตรวจหา
ในเลเยอร์อัจฉริยะ อคติจะเปลี่ยนเป็นพฤติกรรมที่ได้เรียนรู้ คุณสามารถเพิ่ม มาตรการป้องกัน ตรรกะการจัดอันดับใหม่ หรือกฎแบบผสมเพื่อชี้นำเอาต์พุตไปสู่ความเป็นธรรม และการไม่แบ่งแยกได้โดยทำดังนี้
- ทดสอบหาอคติเป็นประจำ ใช้ตัวกรองการตรวจหาอคติเพื่อแจ้งวลีที่มีปัญหา เช่น การตรวจหาคำที่ระบุเพศหรือน้ำเสียงที่กีดกัน ตรวจสอบ การเปลี่ยนแปลงเมื่อเวลาผ่านไป
- สำหรับโมเดลการคาดการณ์ โปรดระมัดระวังข้อมูลที่ละเอียดอ่อน แอตทริบิวต์ เช่น รหัสไปรษณีย์ การศึกษา หรือรายได้ อาจเข้ารหัสลักษณะที่ละเอียดอ่อนโดยอ้อม เช่น เชื้อชาติหรือชนชั้น
- สร้างและเปรียบเทียบเอาต์พุตหลายรายการ จัดอันดับผลลัพธ์ตามความเป็นกลาง ความหลากหลาย และน้ำเสียง ก่อนที่จะตัดสินใจว่าจะแชร์เอาต์พุตใดกับผู้ใช้
- เพิ่มกฎเพื่อบังคับใช้ข้อจํากัดด้านความเป็นธรรม เช่น การบล็อกเอาต์พุต ที่ตอกย้ำภาพเหมารวมหรือแสดงตัวอย่างที่ไม่หลากหลาย
ประสบการณ์ของผู้ใช้
ในอินเทอร์เฟซผู้ใช้ ให้มีความโปร่งใสเกี่ยวกับเหตุผลของโมเดลและกระตุ้นให้ผู้ใช้แสดงความคิดเห็นโดยทำดังนี้
- ระบุเหตุผลสำหรับเอาต์พุตของ AI เช่น "แนะนำให้ใช้ภาษาที่เป็นทางการตามข้อมูลที่คุณป้อนก่อนหน้านี้*" ซึ่งจะช่วยให้ผู้ใช้เห็นว่าระบบทำตามตรรกะที่กำหนดไว้ ไม่ใช่การตัดสินที่ซ่อนอยู่
- ให้ผู้ใช้มีอำนาจควบคุมที่มีความหมาย อนุญาตให้ผู้ใช้ปรับลักษณะการทำงานของโมเดลผ่านการตั้งค่าหรือพรอมต์ เช่น เลือกโทน ความซับซ้อน หรือค่ากำหนดสไตล์ภาพ
- ทำให้การรายงานอคติหรือความไม่ถูกต้องง่ายขึ้น ยิ่งการแจ้งปัญหาทำได้ง่ายขึ้นเท่าใด คุณก็จะได้รับข้อมูลในโลกแห่งความเป็นจริงมากขึ้นเท่านั้นเพื่อปรับปรุงระบบ AI
- ปิดวงจรความคิดเห็น อย่าปล่อยให้รายงานของผู้ใช้หายไป ป้อนข้อมูลนี้ กลับเข้าไปในการฝึกโมเดลใหม่หรือตรรกะของกฎ และแชร์ความคืบหน้าอย่างชัดเจนว่า "เราได้อัปเดตการกลั่นกรองเพื่อลดอคติทางวัฒนธรรมในคำแนะนำ"
อคติเกิดขึ้นในข้อมูล ขยายผ่านโมเดล และปรากฏในประสบการณ์ของผู้ใช้ คุณจัดการเรื่องนี้ได้ในระบบ AI ทั้ง 3 ระดับ ดังนี้
- ข้อมูล: ทำให้แหล่งข้อมูลมีความโปร่งใสและสมดุล
- ความอัจฉริยะ: ตรวจหา ทดสอบ และลดอคติในเอาต์พุต
- UX: ช่วยให้ผู้ใช้ระบุและแก้ไขอคติผ่านการควบคุมและความคิดเห็น
ความน่าเชื่อถือและความโปร่งใส
ความไว้วางใจเป็นตัวกำหนดว่าผู้คนจะใช้ ยอมรับ และสนับสนุนผลิตภัณฑ์ของคุณหรือไม่
ผู้ใช้ส่วนใหญ่คาดหวังว่าแอปพลิเคชันจะทำงานได้ตามที่คาดไว้ เช่น การคลิกปุ่มจะดำเนินการตามที่ระบุไว้เสมอ และนำไปยังที่เดียวกัน AI ทำลายความคาดหวังนี้ เนื่องจากพฤติกรรมของ AI มีความผันผวนสูงและมักคาดเดาไม่ได้ นอกจากนี้ ระบบ AI ยังมีโอกาสที่จะเกิดข้อผิดพลาดโดยธรรมชาติ ดังนี้ โมเดลภาษาหลอนข้อเท็จจริง โมเดลการคาดการณ์ติดป้ายข้อมูลผิด และ เอเจนต์หลุด
ผู้ใช้คือแนวป้องกันสุดท้ายสำหรับข้อผิดพลาดเหล่านี้
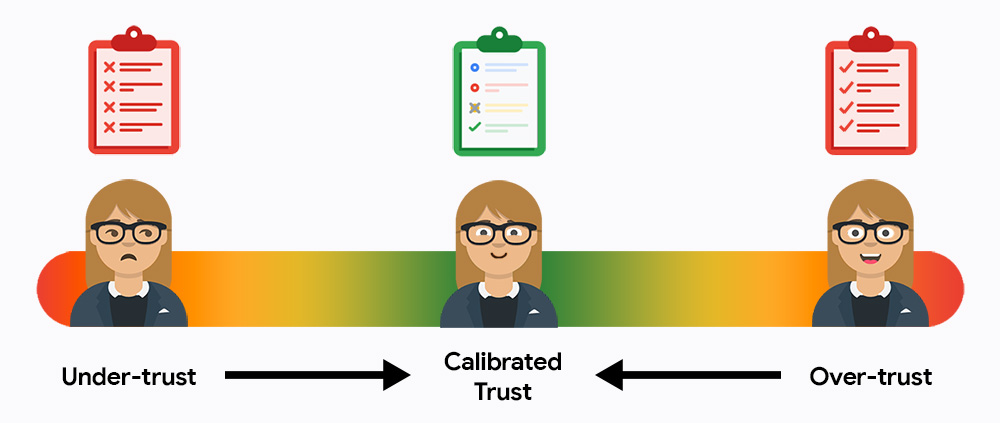
ในช่วงแรก ผู้ใช้อาจไม่เชื่อถือหรือเชื่อถือระบบของคุณมากเกินไป ความไว้วางใจต่ำหมายความว่าผู้ใช้จะไม่ใช้ระบบ และความไว้วางใจสูงหมายความว่าผู้ใช้ยอมรับเอาต์พุตทั้งหมดโดยไม่ตรวจสอบข้อผิดพลาด งานของคุณคือการดึงดูด ผู้ใช้ให้มาอยู่ตรงกลางระหว่างความน่าเชื่อถือที่ปรับเทียบแล้ว ซึ่งเป็นจุดที่ผู้ใช้พึ่งพา AI เพื่อ ประสิทธิภาพในขณะที่ยังคงรับผิดชอบต่อผลลัพธ์สุดท้าย
ข้อมูล
ใน Data Layer ความน่าเชื่อถือสร้างขึ้นได้ด้วยการอธิบายความครอบคลุมและแหล่งที่มาของข้อมูลอย่างชัดเจน ดังนี้
- ระบุแหล่งที่มาและแหล่งข้อมูลอย่างชัดเจน
- บันทึกความใหม่และความล้าสมัยของข้อมูล
- อธิบายประเภทเนื้อหาที่โมเดลเคยเห็นและจุดที่โมเดลอาจ มีปัญหา เช่น ข้อมูลภาษาที่ไม่ใช่ภาษาอังกฤษ
เมื่อระบบ AI สะสมการโต้ตอบและความคิดเห็นเมื่อเวลาผ่านไป ให้พิจารณา เก็บภาพรวมของข้อมูลที่กำหนดเวอร์ชันไว้ เพื่อให้คุณอธิบายได้ว่าเอาต์พุต พัฒนาไปอย่างไร
การตรวจหา
ในเลเยอร์ข้อมูลอัจฉริยะ คุณสามารถจัดการความน่าเชื่อถือผ่านความสามารถในการอธิบาย ตัวบ่งชี้ความเชื่อมั่น และการออกแบบแบบโมดูลได้โดยทำดังนี้
- ให้คำอธิบายตามบริบทแบบทันที ตามข้อขัดแย้งของผู้ใช้ที่ใช้งานอยู่ คุณควรฝังคำอธิบายย่อยๆ ในบริบทโดยตรงในการโต้ตอบ เพื่อให้ผู้ใช้เข้าใจสิ่งที่ระบบ AI กำลังทำขณะที่ใช้งาน
- แจ้งข้อจำกัดและโหมดความล้มเหลวตั้งแต่เนิ่นๆ แจ้งให้ผู้ใช้ทราบว่า AI อาจมีข้อผิดพลาด เช่น "หลีกเลี่ยงการใช้มุกตลกหรือคำศัพท์เฉพาะทางเพื่อให้ได้ผลลัพธ์ที่ดีขึ้น" คิวสั้นๆ ตามบริบทจะช่วยให้เกิดความโปร่งใสโดยไม่ขัดจังหวะ การทำงาน
- ตัวบ่งชี้ความเชื่อมั่นและตรรกะสำรองช่วยให้ AI ทำงานได้อย่างน่าเชื่อถือในสถานการณ์ที่ไม่แน่นอน คุณสามารถประมาณความเชื่อมั่นจากพร็อกซี เช่น คะแนนความน่าจะเป็น หรืออัตราความสำเร็จที่ผ่านมา กำหนดฟอลแบ็กที่ปลอดภัยสำหรับเอาต์พุตที่ ไม่ถูกต้องอย่างชัดเจน
- สถาปัตยกรรมแบบโมดูลช่วยให้ AI มีความโปร่งใสมากขึ้น เช่น หากผู้ช่วยด้านการเขียน จัดการไวยากรณ์ รูปแบบ และน้ำเสียงในขั้นตอนแยกกัน ให้ระบุสิ่งที่ เปลี่ยนแปลงในแต่ละขั้นตอน: "น้ำเสียง: เป็นกันเองมากขึ้น ความซับซ้อน: ลดลง"
ประสบการณ์ของผู้ใช้
ประสบการณ์ของผู้ใช้จะช่วยให้คุณมีพื้นที่กว้างขวางในการสร้างและ ปรับเทียบความน่าเชื่อถือ เทคนิคและรูปแบบที่น่าลองใช้มีดังนี้
- ปรับเนื้อหาด้านการศึกษา อย่าคิดว่าผู้ใช้ของคุณเชี่ยวชาญด้าน AI ให้คำแนะนำแบบย่อสำหรับผู้ใช้ขั้นสูงและคำอธิบายโดยละเอียดสำหรับ ผู้เริ่มต้น
- ใช้การเปิดเผยข้อมูลแบบค่อยเป็นค่อยไป เริ่มจากคิวขนาดเล็ก ใส่ข้อความที่ระบุว่าคุณใช้ AI เช่น "ระบบสร้างข้อความนี้โดยอัตโนมัติ" และอนุญาตให้ผู้ใช้คลิกเพื่อดูข้อมูลเชิงลึกเพิ่มเติม
- ปิดลูปความคิดเห็นด้วยผลลัพธ์ที่มองเห็นได้ เมื่อผู้ใช้ให้คะแนน แก้ไข หรือ ลบล้างคำแนะนำของ AI ให้แชร์ว่าข้อมูลที่ผู้ใช้ป้อนจะกำหนดลักษณะการทำงานในอนาคตอย่างไร "คุณชอบคำตอบที่กระชับ จึงปรับโทนการใช้ภาษาตามนั้น" ความโปร่งใสเปลี่ยน ความคิดเห็นให้เป็นความไว้วางใจ
- จัดการข้อผิดพลาดอย่างเหมาะสม เมื่อระบบทำผิดพลาดหรือให้ผลลัพธ์ที่มีความน่าเชื่อถือต่ำ ให้รับทราบและมอบหมายให้ผู้ใช้ตรวจสอบ เช่น "คำแนะนำนี้อาจไม่ตรงกับความตั้งใจของคุณ ตรวจสอบก่อนเผยแพร่" ระบุเส้นทางที่ชัดเจนโดยอนุญาตให้ผู้ใช้ลองอีกครั้ง แก้ไข หรือเปลี่ยนกลับ เป็นตัวเลือกสำรองที่ปลอดภัย
กล่าวโดยสรุปคือ เพื่อจัดการกับความไม่แน่นอนและข้อผิดพลาดที่อาจเกิดขึ้นของ AI ให้แนะนำ ผู้ใช้จากความสงสัยหรือการพึ่งพามากเกินไปไปสู่การปรับเทียบความน่าเชื่อถือที่เหมาะสม
- ข้อมูล: แสดงความโปร่งใสเกี่ยวกับแหล่งที่มาของข้อมูล
- ความอัจฉริยะ: ทำให้การให้เหตุผลเป็นแบบแยกส่วนและอธิบายได้
- UX: ออกแบบเพื่อความชัดเจนและคำติชมที่เพิ่มขึ้น
สิ่งที่ได้เรียนรู้
ในโมดูลนี้ เราได้สำรวจเสาหลัก 3 ประการของ AI ที่มีความรับผิดชอบ ได้แก่ ความเป็นส่วนตัว ความเป็นธรรม และความน่าเชื่อถือ ซึ่งอาจทำให้คุณรู้สึกท่วมท้น โดยเฉพาะเมื่อคุณเพิ่งเริ่มต้นหรือพยายามก้าวกระโดดจากต้นแบบไปสู่การผลิต
มุ่งเน้นความพยายามในด้านที่สำคัญที่สุดและกำหนดแนวทางของคุณเองในการกำกับดูแล AI การทำซ้ำคือกุญแจสำคัญ การเปิดตัวแต่ละครั้งและรอบความคิดเห็นของผู้ใช้จะช่วย เพิ่มความเข้าใจว่าระบบของคุณต้องการการป้องกัน ความโปร่งใส หรือความยืดหยุ่นเพิ่มเติมในส่วนใด
แหล่งข้อมูล
ต่อไปนี้คือแหล่งข้อมูลขั้นสูงเพิ่มเติมเกี่ยวกับหัวข้อที่แสดงในโมดูลนี้
- การเปรียบเทียบความเป็นส่วนตัวและความปลอดภัยของ AI Assistant จะเจาะลึกนโยบายความเป็นส่วนตัวของ AI
- เอกสารเกี่ยวกับการจดจำของ LLM ซึ่งเป็นโหมดความล้มเหลวด้านความเป็นส่วนตัวที่สำคัญซึ่งโมเดลจะเก็บรักษาและสามารถได้รับพรอมต์ให้สร้างข้อมูลที่เฉพาะเจาะจงและละเอียดอ่อนจากข้อมูลการฝึกได้
- ตรวจสอบแหล่งข้อมูลที่เชื่อมโยงโดยตรงกับโมเดลที่คุณเลือก เช่น Google Cloud มีแหล่งข้อมูลด้านความปลอดภัย
- ชุดเครื่องมือ AI ที่มีความรับผิดชอบมีแหล่งข้อมูลสำหรับนักพัฒนาแอปในทุกหัวข้อที่เรากล่าวถึงในโมดูลนี้
แหล่งข้อมูล
ต่อไปนี้คือแหล่งข้อมูลขั้นสูงเพิ่มเติมเกี่ยวกับหัวข้อที่แสดงในโมดูลนี้
- การเปรียบเทียบความเป็นส่วนตัวและความปลอดภัยของ AI Assistant จะเจาะลึกนโยบายความเป็นส่วนตัวของ AI
- บทความเกี่ยวกับการจดจำของ LLM ซึ่งเป็นโหมดความล้มเหลวด้านความเป็นส่วนตัวที่สำคัญ ซึ่งโมเดลจะเก็บรักษาและสามารถได้รับพรอมต์ให้สร้างซ้ำ ข้อมูลที่เฉพาะเจาะจงและละเอียดอ่อนจากข้อมูลที่ใช้ฝึกมา
- ตรวจสอบแหล่งข้อมูลที่เชื่อมโยงโดยตรงกับโมเดลที่คุณเลือก เช่น Google Cloud มีแหล่งข้อมูลด้านความปลอดภัย
- ชุดเครื่องมือ AI ที่มีความรับผิดชอบมีแหล่งข้อมูลสำหรับนักพัฒนาซอฟต์แวร์ในทุกหัวข้อที่เรากล่าวถึงในโมดูลนี้
ทดสอบความเข้าใจ
แนวทางปฏิบัติแนะนำด้านความเป็นส่วนตัวเกี่ยวกับการเก็บรวบรวมข้อมูลสำหรับ AI คืออะไร
ความน่าเชื่อถือที่ปรับเทียบแล้วคืออะไร
นักพัฒนาแอปควรดำเนินการใดเพื่อให้มั่นใจถึงความเป็นธรรมในเลเยอร์ "Intelligence"
เทคนิค UX ใดที่ช่วยสร้างความไว้วางใจและความโปร่งใส