
Tasarım kararlarınız, yapay zeka sisteminizin sorumluluğunu ve güvenliğini doğrudan şekillendirir. Örneğin, veri kaynaklarını nasıl seçeceğinize, model davranışını nasıl yapılandıracağınıza veya yapay zeka çıkışlarını kullanıcılara nasıl sunacağınıza karar verirsiniz. Bu seçimlerin kullanıcılarınız ve şirketiniz için gerçek sonuçları vardır.
Bu modülde, yapay zeka yönetimiyle ilgili üç önemli boyutu ele alıyoruz:
- Gizlilik: Verileri sorumlu bir şekilde işleyin, hangi verilerin toplandığını açıklayın ve tarayıcıdan ayrılan verileri en aza indirin.
- Adalet: Modellerinizde ayrımcı davranış (önyargı) olup olmadığını kontrol edin ve kullanıcıların sorunları işaretlemesine olanak tanıyan döngüler oluşturun.
- Güven ve şeffaflık: Sisteminizi şeffaflık ve ölçülü güven için tasarlayın. Böylece kullanıcılar, belirsizliklere ve olası hatalara rağmen sistemden yararlanmaya devam edebilir.
Her konu için farklı yapay zeka ürünlerinde nasıl göründüğünü açıklıyoruz. Ardından, yapay zeka çözümünüzün üç katmanı (veri, yapay zeka ve kullanıcı deneyimi) genelinde analiz ederiz. Nelere dikkat etmeniz gerektiğini, sorunları nasıl ele alacağınızı ve etkili, basit bir yönetimi nasıl sürdüreceğinizi öğreneceksiniz.
Gizlilik
Gerçek kullanım ve etkileşim verilerinin her yapay zeka sisteminin temelini oluşturduğunu öğrendiniz. Veriler, öğrenmeyi, değerlendirmeyi ve sürekli iyileştirmeyi destekler. İyi gizlilik uygulamaları, bu verileri güvende tutmanıza ve kullanıcıların bilgilerini kontrol etmesine olanak tanır.
Gizlilik beklentileri, ürününüze ve kitlenize bağlı olarak büyük ölçüde değişir. Tüketici ürünlerinde beklentiler genellikle kişilerin adları, mesajları ve göz atma davranışları gibi kimliği tanımlayabilecek bilgilerinin (PII) korunmasıyla ilgilidir. Kurumsal ayarlarda ise veri egemenliği, gizliliği ve fikri mülkiyetin korunması ön plana çıkar.
İnsanların geçim kaynaklarını veya refahını etkileyen sektörler (ör. sağlık, finans ve eğitim), eğlence gibi daha düşük riskli alanlara kıyasla daha katı gizlilik önlemleri gerektirir.
Yapay zeka sisteminizin farklı bileşenlerinde gizliliğin nasıl yönetilebileceğine bakalım.
Veriler
Yapay zeka sisteminizi sürekli olarak iyileştirmek için girişler, çıkışlar, geri bildirimler ve hatalar dahil olmak üzere kullanıcı etkileşimleriyle ilgili veriler toplayabilirsiniz. Bu bilgiler, istemlerde değerlendirme, modelde ince ayar veya birkaç görevli örnek için yeniden kullanılabilir. Ayrıca kullanıcı deneyimi tasarımınızı da şekillendirebilir.
Sorumlu veri toplama ile ilgili bazı kurallar:
- Yalnızca öğrenme için gerekenleri toplayın. Yapay zeka destekli bir ürün araması, sonuçları iyileştirmek için kullanıcının tam profiline ihtiyaç duymayabilir. Çoğu durumda sorgu, tıklama kalıpları ve anonimleştirilmiş oturum verilerinin sağlanması yeterlidir.
- Hassas bilgileri kaldırma. Verileri harici modellere göndermeden önce tüm kimliği tanımlayabilecek bilgileri (PII) kaldırın. Bunu anonimleştirme, takma ad kullanma veya toplama ile yapabilirsiniz.
- Saklama sınırları. Günlükleri ve önbelleğe alınan verileri amaçlarına hizmet ettikten sonra silin. Kısa saklama döngüleri, analizleri engellemeden riski azaltır.
Hangi bilgileri topladığınızı, bu bilgileri ne kadar süreyle sakladığınızı ve neden gerekli olduğunu belgeleyin. Veri akışlarınızı teknik bilgisi olmayan bir kullanıcıya net bir şekilde açıklayamıyorsanız akışlar muhtemelen kontrol etmek veya haklı çıkarmak için çok karmaşıktır.
Intelligence
Kullanıcılar, yapay zeka sisteminizle etkileşim kurarken farkında olmadan veya dikkatsizce özel ya da hassas bilgiler girebilir. Bu risk, özellikle kullanıcıların yazdıklarını kısıtlayamadığınız açık uçlu sohbet veya yazma arayüzlerinde yüksektir.
Belirli kelimelerin gönderilmesini engelleyebilirsiniz ancak bu bilgiler bağlama duyarlı olabilir. Modeliniz, harici bir sağlayıcı tarafından yönetilen bir sunucuda çalışıyorsa kullanıcı girişini eğitim verisi olarak yeniden kullanabilir. Sonuç olarak model, diğer kullanıcılara özel metin parçaları, kimlik bilgileri veya diğer gizli ayrıntılar gösterebilir.
Çıkarım sırasında gizlilik ihlallerine karşı nasıl önlem alabileceğiniz aşağıda açıklanmıştır:
Üçüncü taraf API'lerini dikkatlice inceleyin. Gönderdiğiniz verilerin başına tam olarak ne geldiğini bilmeniz gerekir. Girişler kaydedilir, saklanır veya eğitim için yeniden kullanılır mı? Şeffaf olmayan hizmetlerden kaçının ve şeffaf politikaları ve denetimleri olan sağlayıcıları tercih edin.
Modelleri kendiniz eğitiyor veya ince ayarlıyorsanız eğitim verilerinizdeki hassas ayrıntıları soyutlayın. Kısa yoldan öğrenmeye karşı dikkatli olun. Örneğin, kredi puanı başvurusunda posta kodları, modelin ırk veya sosyoekonomik durum hakkında varsayımlarda bulunmasına neden olabilir. Bu durum, adil olmayan tahminlere yol açabilir ve mevcut eşitsizlikleri pekiştirebilir.
Hassas alanlarda istemci tarafı çıkarımı tercih edin. Bu, yerleşik yapay zeka, tarayıcıdaki bir model veya özel bir istemci tarafı modeliyle yapılabilir. Bu seçim hakkında daha fazla bilgiyi bir sonraki modül olan platform seçimi bölümünde edinebilirsiniz.
Kullanıcı deneyimi
Uygulama arayüzünüz, kullanıcılara neler olduğunu göstermek, güvenlerini kazanmak ve verileri üzerinde kontrol sahibi olmalarını sağlamak için bir fırsat sunar:
- Şeffaf olun. Arayüzünüzdeki "Yerel olarak işlendi" veya "Analiz için güvenli bir şekilde gönderildi" gibi kısa etiketler güven oluşturmanıza yardımcı olabilir. Analizin cihazda mı yoksa sunucuda mı gerçekleştiğini açıklayan ipuçları gibi daha fazla ayrıntı için kademeli açıklama eklemeyi düşünebilirsiniz.
- Yeri geldiği zaman izin isteyin. İlgili durumlarda izin isteyin. "Önerileri iyileştirmek için önceki aramaları paylaşmak ister misiniz?" sorusu, genel bir izin istemeye kıyasla çok daha anlamlıdır.
- Basit kontroller sunun. Kişiselleştirme, bulut tabanlı özellikler veya veri paylaşımı için net bir şekilde görünen açma/kapatma düğmeleri ekleyin.
- Görünürlük verme Kullanıcıların uygulamadan çıkmadan verilerini yönetebilmesi için küçük bir gizlilik kontrol paneli ekleyin.
- Neden veri topladığınızı açıklayın. Kullanıcılar, verilerin nasıl kullanılacağını anladıklarında paylaşmaya daha istekli olabilir. Aynı durum saklama ve yönetim politikalarınız için de geçerlidir.
Web'deki yapay zeka gizliliği, tek bir uygunluk adımı değil, devam eden bir tasarım anlayışıdır:
- Veriler: Daha az veri toplayın ve daha fazla koruma sağlayın.
- Zeka: Harici modellerin hassas olabilecek verileri ezberlemesini önleyin.
- Kullanıcı deneyimi: Gizliliği kullanıcılar için şeffaf ve kontrol edilebilir hale getirin.
Adalet
Yapay zeka sistemleri, haksız ayrımcılığa yol açan önyargılar taşıyabilir. Bu durum, özellikle işe alma, hukuk ve finans gibi alanlarda geçerlidir. Bu alanlarda önyargı, gerçek insanları doğrudan etkileyen kritik kararları çarpıtabilir.
Örneğin, geçmiş işe alım verileriyle eğitilmiş bir işe alım modeli, belirli demografik özellikleri daha düşük aday kalitesiyle ilişkilendirebilir. Bu durumda, işle ilgili beceri ve deneyimi değerlendirmek yerine, yeterince temsil edilmeyen gruplardan gelen adaylar istemeden cezalandırılır.
Veriler
Eğitim verileriniz, gerçek dünyadaki önyargıları yansıtabilen ve hatta yeni önyargılar ortaya çıkarabilen, birbirinden bağımsız bilgi parçalarından oluşan bir kümedir. Verilerle ilgili önyargıları şeffaf ve yönetilebilir hale getirmek için pratik adımlar aşağıda verilmiştir:
- Veri kaynaklarınızı ve kapsamınızı belgeleyin. Kullanıcıların modelin hangi konularda yetersiz kalabileceğini anlamasına yardımcı olmak için kısa bir açıklama yayınlayın. Örneğin, "Bu model, öncelikli olarak İngilizce içeriklerle eğitildi ve teknik metinler sınırlı düzeyde kullanıldı."
- Teşhis kontrolleri yapın. Sistematik farklılıkları ortaya çıkarmak için A/B testlerini kullanın. Örneğin, sisteminizin "She is a great leader" (O, harika bir lider), "He is a great leader" (O, harika bir lider) ve "They are a great leader" (Onlar harika bir lider) ifadelerini nasıl işlediğini karşılaştırın. Duygu veya üsluptaki küçük farklılıklar daha derin bir önyargının işareti olabilir.
- Veri kümelerinizi etiketleyin. Gelecekteki denetimleri, filtrelemeyi ve yeniden dengelemeyi kolaylaştırmak için alan, bölge ve resmiyet düzeyi gibi basit meta veriler ekleyin.
Özel modelleri eğitiyor veya ince ayarlıyorsanız veri kümelerinizi dengeleyin. Daha geniş bir temsil, model oluşturulduktan sonra yanlılığı düzeltmekten daha etkili bir şekilde çarpıklığı azaltır.
Intelligence
Zeka katmanında önyargı, öğrenilmiş davranışa dönüştürülür. Çıkışları adalet ve kapsayıcılık yönünde yönlendirmek için korumalar, yeniden sıralama mantığı veya karma kurallar ekleyebilirsiniz:
- Düzenli olarak önyargı testi yapın. Cinsiyet içeren terimleri veya dışlayıcı bir üslubu yakalamak gibi sorunlu ifadeleri işaretlemek için önyargı tespit filtrelerini kullanın. Zaman içinde sapma olup olmadığını izleyin.
- Tahmini modellerde hassas veriler konusunda dikkatli olun. Posta kodu, eğitim veya gelir gibi özellikler, ırk ya da sınıf gibi hassas özellikleri dolaylı olarak kodlayabilir.
- Birden fazla çıktı oluşturup karşılaştırma Kullanıcıyla hangi çıktının paylaşılacağını belirlemeden önce sonuçları tarafsızlık, çeşitlilik ve üsluba göre sırala.
- Adalet kısıtlamalarını zorunlu kılmak için kurallar ekleyin. Örneğin, kalıplaşmış düşünceleri pekiştiren veya çeşitli örnekleri temsil etmeyen çıkışları engelleme.
Kullanıcı deneyimi
Kullanıcı arayüzünüzde modelin muhakemesi konusunda şeffaf olun ve geri bildirimleri teşvik edin:
- Yapay zeka çıktıları için gerekçeler sunun. Örneğin, "Önceki girişlerinize göre profesyonel bir üslup kullanmanız önerilir*." Bu sayede kullanıcılar, sistemin tanımlanmış bir mantığı izlediğini ve gizli bir yargı kullanmadığını görür.
- Kullanıcılara anlamlı kontrol olanağı sunun. Kullanıcıların, ayarlar veya istemler aracılığıyla model davranışını ayarlamasına (ör. üslup, karmaşıklık veya görsel stil tercihlerini seçme) izin verin.
- Önyargı veya yanlışlık bildirmeyi kolaylaştırın. Bir sorunu işaretlemek ne kadar kolay olursa yapay zeka sisteminizi geliştirmek için o kadar fazla gerçek dünya verisi elde edersiniz.
- Geri bildirim döngüsünü kapatın. Kullanıcı raporlarının kaybolmasına izin vermeyin. Bu verileri yeniden eğitme veya kural mantığınıza geri aktarın ve ilerlemeyi görünür şekilde paylaşın: "Önerilerdeki kültürel önyargıyı azaltmak için moderasyonumuzu güncelledik."
Önyargı verilerde doğar, modeller aracılığıyla güçlenir ve kullanıcı deneyiminde ortaya çıkar. Bu sorunu yapay zeka sisteminizin üç düzeyinde de ele alabilirsiniz:
- Veriler: Veri kaynaklarını şeffaf ve dengeli hale getirin.
- Zeka: Çıkışlardaki yanlılığı tespit etme, test etme ve azaltma.
- Kullanıcı deneyimi: Kullanıcılara kontrol ve geri bildirim yoluyla önyargıları belirleme ve düzeltme olanağı tanır.
Güven ve şeffaflık
Güven, kullanıcıların ürününüzü kullanıp kullanmayacağını, benimseyip benimsemeyeceğini ve savunup savunmayacağını belirler.
Çoğu kullanıcı, tahmin edilebilir uygulamalar bekler. Örneğin, düğme tıklamaları her zaman belirtilen işlemi gerçekleştirir ve aynı yere yönlendirir. Yapay zeka, davranışları çok değişken ve genellikle tahmin edilemez olduğundan bu beklentiyi karşılamaz. Ayrıca, yapay zeka sistemlerinin doğasında başarısızlık potansiyeli vardır: Dil modelleri gerçekleri halüsinasyon olarak algılar, tahmine dayalı modeller verileri yanlış etiketler ve aracıların kontrolü kaybedilir.
Kullanıcılarınız bu hatalara karşı son savunma hattıdır.
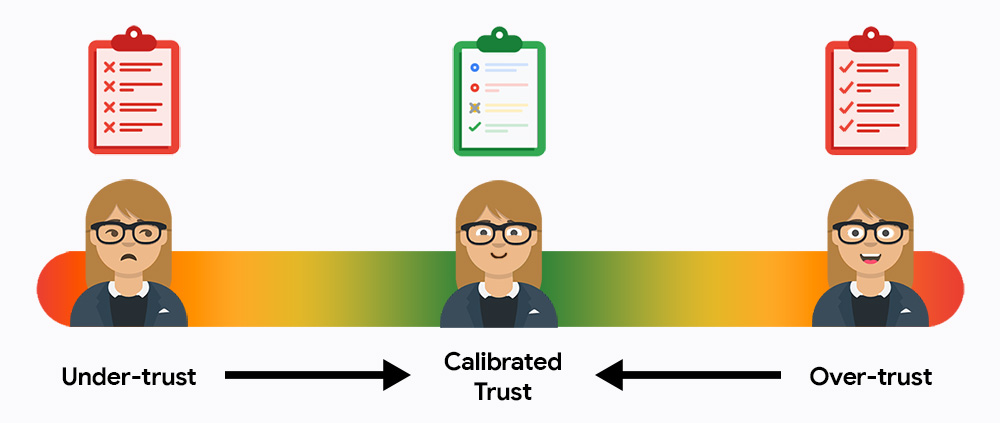
Başlangıçta kullanıcılar sisteminize muhtemelen ya az ya da çok güvenir. Sisteme az güvenmek, kullanıcıların sistemi kullanmayacağı, çok güvenmek ise hataları kontrol etmeden çıktıları tamamen kabul edeceği anlamına gelir. Göreviniz, kullanıcıları kalibre edilmiş güvenin altın ortasına çekmektir. Bu noktada kullanıcılar, nihai sonuçlardan sorumlu olmaya devam ederken verimlilik için yapay zekadan yararlanır.
Veriler
Veri katmanında, verilerinizin kapsamı ve kaynağı net bir şekilde açıklanarak güven oluşturulur:
- Veri kaynağı ve soyu hakkında açık olun.
- Verilerin güncelliğini ve eskiliğini belgeleyin.
- Modelin gördüğü içerik türlerini ve modelin zorlanabileceği noktaları (ör. İngilizce olmayan dil verileri) açıklayın.
Yapay zeka sisteminiz zaman içinde etkileşim ve geri bildirim topladıkça verilerin sürüm oluşturulmuş anlık görüntülerini saklayarak çıkışların nasıl geliştiğini açıklayabilirsiniz.
Intelligence
Zeka katmanında, açıklanabilirlik, güven göstergeleri ve modüler tasarım aracılığıyla güveni yönetebilirsiniz:
- Bağlama uygun, anlık açıklamalar sunun. Etkin kullanıcı paradoksuna göre, kullanıcıların yapay zeka sistemini kullanırken ne yaptığını anlaması için bağlam içinde, doğrudan etkileşimlere mikro açıklamalar yerleştirmeniz daha iyi olur.
- Sınırlamaları ve hata modlarını önceden bildirin. Kullanıcılara yapay zekanın hangi konularda hata yapabileceğini söyleyin. Örneğin, "Daha iyi sonuçlar almak için mizah veya alan jargonundan kaçının." Kısa ve bağlama uygun ipuçları, akışı bozmadan şeffaflık sağlar.
- Güven göstergeleri ve yedek mantık, yapay zekanın belirsizlik durumlarında güvenilir olmasını sağlar. Olasılık puanları veya geçmiş başarı oranları gibi proxy'lerden güveni tahmin edebilirsiniz. Açıkça yanlış olan çıkışlar için güvenli yedekler tanımlayın.
- Modüler mimariler, yapay zekayı daha şeffaf hale getirir. Örneğin, bir yazma asistanı dil bilgisi, stil ve üslubu ayrı adımlarda ele alıyorsa her aşamada neyin değiştiğini belirtin: "Üslup: daha az resmi; karmaşıklık: basitleştirilmiş".
Kullanıcı deneyimi
Kullanıcı deneyimi, güven oluşturmak ve kalibre etmek için geniş bir oyun alanı sunar. Deneyebileceğiniz bazı teknikler ve kalıplar:
- Eğitsel içerikleri uyarlama Kullanıcılarınızın yapay zeka konusunda bilgili olduğunu varsaymayın. Güçlü kullanıcılar için kısa ve öz, yeni başlayanlar için ise ayrıntılı açıklamalar sunun.
- Aşamalı ifşa uygulayın. Küçük ipuçlarıyla başlayın. "Bu içerik otomatik olarak oluşturuldu" gibi yapay zeka kullandığınızı belirten bir metin ekleyin ve kullanıcıların daha fazla bilgi için tıklamasına izin verin.
- Görünür sonuçlarla geri bildirim döngülerini kapatın. Kullanıcılar bir yapay zeka önerisini değerlendirdiğinde, düzelttiğinde veya geçersiz kıldığında, girişlerinin gelecekteki davranışları nasıl şekillendirdiğini paylaşın: "Kısa yanıtları tercih ettiniz. Tonu buna göre ayarladım." Görünürlük, geri bildirimi güvene dönüştürür.
- Hataları düzgün şekilde yönetin. Sisteminiz hata yaptığında veya düşük güvenilirlikli bir sonuç verdiğinde bunu kabul edin ve inceleme görevini kullanıcıya devredin. Örneğin, "Bu öneri, amacınızla eşleşmeyebilir. Yayınlamadan önce inceleyin." Kullanıcının yeniden denemesine, düzenlemesine veya güvenli bir geri dönüşe dönmesine izin vererek net bir yol sunun.
Kısacası, yapay zekanın belirsizliğini ve hata yapma potansiyelini gidermek için kullanıcıları şüphe veya aşırı güven yerine doğru güven kalibrasyonuna yönlendirin:
- Veriler: Veri kaynağı konusunda şeffaf olun.
- Zeka: Muhakemeyi modüler ve açıklanabilir hale getirin.
- UX: Aşamalı netlik ve geri bildirim için tasarım yapın.
Önemli noktalar
Bu modülde, sorumlu yapay zekanın üç temel dayanağı olan gizlilik, adalet ve güveni inceledik. Bu durum, özellikle işe yeni başlıyorsanız veya prototipten üretime geçmeye çalışıyorsanız bunaltıcı olabilir.
Çalışmalarınızı en kritik alanlara odaklayın ve yapay zeka yönetimiyle ilgili kendi yaklaşımınızı tanımlayın. Yineleme önemlidir. Her sürüm ve kullanıcı geri bildirimi turu, sisteminizin hangi alanlarda daha fazla koruma, şeffaflık veya esnekliğe ihtiyaç duyduğunu daha iyi anlamanızı sağlar.
Kaynaklar
Bu modülde yer alan konularla ilgili daha ileri düzeydeki bazı kaynakları aşağıda bulabilirsiniz:
- Yapay Zeka Asistanı Gizlilik ve Güvenlik Karşılaştırması, yapay zeka gizlilik politikaları hakkında ayrıntılı bilgi sağlar.
- Bir modelin eğitim verilerindeki belirli ve hassas bilgileri sakladığı ve bu bilgileri yeniden üretmesi için istem gönderilebildiği kritik bir gizlilik hatası modu olan LLM ezberleme hakkında bir makale.
- Seçtiğiniz modelle doğrudan ilişkili kaynakları inceleyin. Örneğin, Google Cloud güvenlik kaynakları sağlar.
- Sorumlu Yapay Zeka Araç Seti, bu modülde ele aldığımız tüm konularla ilgili geliştirici kaynakları sunar.
Kaynaklar
Bu modülde yer alan konularla ilgili daha ileri düzeydeki bazı kaynakları aşağıda bulabilirsiniz:
- Yapay Zeka Asistanı Gizlilik ve Güvenlik Karşılaştırması Yapay zeka gizlilik politikaları hakkında ayrıntılı bilgi sağlar.
- Bir modelin, eğitim verilerindeki belirli ve hassas bilgileri sakladığı ve bu bilgileri yeniden üretmesi için istem gönderilebildiği kritik bir gizlilik hatası modu olan LLM ezberleme hakkında bir makale.
- Seçtiğiniz modelle doğrudan ilişkili kaynakları inceleyin. Örneğin, Google Cloud güvenlik kaynakları sağlar.
- Sorumlu Yapay Zeka Araç Seti, bu modülde ele aldığımız tüm konularla ilgili geliştirici kaynakları sunar.
Anlayıp anlamadığınızı kontrol etme
Yapay zeka için veri toplama konusunda önerilen gizlilik uygulaması nedir?
Ölçülü güven nedir?
"Zeka" katmanında adil bir deneyim sağlamak için geliştiriciler ne yapabilir?
Güven ve şeffaflık oluşturmak için kullanılan kullanıcı deneyimi tekniği nedir?