
您的設計決策會直接影響 AI 系統的責任和安全性。例如,您可以決定如何選取資料來源、設定模型行為,或向使用者呈現 AI 輸出內容。這些選擇會對使用者和貴公司造成實際影響。
在本單元中,我們將介紹 AI 控管的三個重要層面:
- 隱私權:負責任地處理資料、說明蒐集的資料類型,並盡量減少從瀏覽器流出的資料。
- 公平性:檢查模型是否有歧視行為 (偏誤),並建立可供使用者標記問題的迴圈。
- 信任和透明度:設計系統時應秉持透明原則,並校正信任度,讓使用者在不確定性和潛在錯誤的情況下,仍能持續從中獲益。
我們會針對每個主題,說明其在不同 AI 產品中的呈現方式。接著,我們會將這些原則細分為 AI 解決方案的三個層面:資料、智慧和使用者體驗。您將瞭解應注意的事項、如何解決問題,以及如何維持有效且輕量的管理機制。
隱私權
您已瞭解實際使用和互動資料是任何 AI 系統的核心。資料是學習、評估和持續改善的基礎。良好的隱私權做法不僅能確保資料安全,還能讓使用者控管自己的資訊。
隱私權期望因產品和目標對象而異。在消費性產品中,使用者通常會期望保護個人識別資訊 (PII),例如姓名、訊息和瀏覽行為。在企業環境中,重點會轉向資料主權、機密性和智慧財產保護。
影響人們生計或福祉的產業 (例如醫療保健、金融和教育) 需要比娛樂等低風險領域更嚴格的隱私權防護措施。
我們來看看如何管理 AI 系統各個元件的隱私權。
資料
如要持續改善 AI 系統,您可以收集使用者互動資料,包括輸入內容、輸出內容、意見回饋和錯誤。這項資訊可重複用於評估、模型微調,或提示中的少量樣本。這項資料也能做為使用者體驗設計的參考依據。
以下是負責任地收集資料的幾項準則:
- 只收集學習所需的資料。AI 輔助產品搜尋功能可能不需要使用者的完整個人資料,就能改善搜尋結果。在大多數情況下,提供查詢、點擊模式和匿名工作階段資料就足夠。
- 移除機密資訊。將資料傳送至外部模型前,請先移除所有個人識別資訊 (PII)。您可以透過匿名化、假名化或匯總來達成此目的。
- 限制保留時間:記錄和快取資料達到用途後,請刪除這些資料。縮短保留週期可降低風險,同時不影響洞察資料。
記錄您收集的資訊、保留時間,以及收集這些資訊的原因。如果無法向非技術人員清楚說明資料流程,這些流程可能過於複雜,難以控制或證明合理性。
情報
使用者與 AI 系統互動時,可能會在不知情或不小心輸入私密或敏感資訊。在開放式即時通訊或撰寫介面中,您無法限制使用者輸入的內容,因此這類風險特別高。
雖然您可以禁止傳送特定字詞,但這類資訊可能與情境相關。如果模型在外部供應商管理的伺服器上執行,供應商可能會將使用者輸入內容重複用於訓練資料。最終,模型可能會向其他使用者揭露私人文字片段、憑證或其他機密詳細資料。
以下說明如何在推論期間防範隱私權侵害事件:
請仔細審查第三方 API。您應確切瞭解所傳送資料的處理方式。系統會記錄、保留或重複使用輸入內容進行訓練嗎?避免使用不透明的服務,並優先選擇政策和控制項公開透明的供應商。
如果您自行訓練或微調模型,請從訓練資料中抽象化敏感詳細資料。請勿抄捷徑。舉例來說,在信用評分申請中,郵遞區號可能會導致模型對種族或社經地位做出假設。這可能會導致預測不公正,並加劇現有的不平等。
在敏感領域中,建議使用用戶端推論。這可以是內建 AI、瀏覽器中的模型,或是自訂用戶端模型。下一個單元「選擇平台」會詳細說明這項選擇。
使用者體驗
應用程式介面可讓您向使用者說明情況、贏得信任,並讓他們控管自己的資料:
- 開誠布公。介面中的簡短標籤 (例如「在本機處理」或「安全地傳送以供分析」) 有助於建立信任感。建議加入漸進式揭露功能,提供更多詳細資料,例如說明分析是在裝置上還是伺服器上進行的工具提示。
- 在使用情境中要求。在適當情況下要求同意聲明。「您是否要分享先前的搜尋記錄,以取得更實用的建議?」比全面性的同意聲明更有意義。
- 提供簡單的控制選項。加入清楚顯示的切換按鈕,方便使用者開啟/關閉個人化設定、雲端功能或資料共用。
- 授予瀏覽權限。加入小型隱私權資訊主頁,讓使用者不必離開應用程式就能管理資料。
- 說明您收集資料的原因。如果使用者瞭解資料的用途,可能就比較願意分享。資料保留和管理政策也適用相同原則。
網路 AI 的隱私權並非單一的法規遵循步驟,而是持續的設計思維:
- 資料:減少收集資料,加強保護。
- 智慧:避免外部模型記住潛在的敏感資料。
- 使用者體驗:讓使用者清楚瞭解隱私權設定,並可自行控管。
公平性
AI 系統可能帶有偏誤,導致不公平的歧視行為。在招聘、法律和金融等領域,偏見可能會扭曲直接影響真人的重大決策,因此尤其需要注意。
舉例來說,根據歷來招募資料訓練的聘僱模型可能會將特定客層特徵與較低的應徵者品質建立關聯,無意間懲罰來自弱勢群體的應徵者,而非評估與工作相關的技能和經驗。
資料
訓練資料是一組個別獨立的資訊,可能反映現實世界的偏誤,甚至會產生新的偏誤。以下是實用步驟,可讓您清楚瞭解並管理資料相關偏誤:
- 記錄資料來源和涵蓋範圍。發布簡短聲明,協助使用者瞭解模型可能不足之處。例如:「這個模型主要以英文內容訓練,技術性文字的代表性有限。」
- 執行診斷檢查。使用 A/B 測試找出系統性差異。舉例來說,比較系統處理「她是優秀的領導者」、「他是優秀的領導者」和「他們是優秀的領導者」的方式。如果情緒或語氣出現微小差異,可能代表存在更深層的偏見。
- 為資料集加上標籤。新增網域、區域和正式程度等輕量型中繼資料,方便日後稽核、篩選和重新平衡。
如果您要訓練或微調自訂模型,請平衡資料集。與在模型建構完成後修正偏差相比,更廣泛的代表性可更有效地減少偏斜。
情報
在智慧層中,偏誤會轉化為學習行為。您可以新增安全措施、重新排序邏輯或混合規則,引導輸出內容朝向公平和包容的方向發展:
- 定期測試偏誤。使用偏誤偵測篩選器標記有問題的措辭,例如找出性別用語或排擠語氣。長期監控漂移情形。
- 對於預測模型,請謹慎處理私密資料。郵遞區號、教育程度或收入等屬性可能會間接編碼種族或階級等敏感特徵。
- 生成及比較多個輸出內容。根據中立性、多元性和語氣對結果進行排序,然後決定要與使用者分享哪個輸出內容。
- 新增規則,強制執行公平性限制。例如,禁止輸出會加深刻板印象或無法呈現多元範例的內容。
使用者體驗
在使用者介面中,清楚說明模型的推理過程,並鼓勵使用者提供意見回饋:
- 提供 AI 輸出內容的理由。例如「根據您先前的輸入內容,建議使用專業語氣*。」這可讓使用者瞭解系統是依據定義的邏輯,而非隱藏的判斷標準。
- 讓使用者享有有意義的控制權。允許他們透過設定或提示調整模型行為,例如選擇語氣、複雜度或視覺風格偏好設定。
- 簡化回報偏誤或不實資訊的流程。越容易標記問題,您就能取得越多實際資料來改善 AI 系統。
- 全盤掌握成效。請勿讓使用者檢舉內容消失。將這項資料回饋到重新訓練或規則邏輯中,並清楚顯示進度:「我們已更新審核機制,減少推薦內容中的文化偏見。」
偏誤源自資料,透過模型放大,並在使用者體驗中顯現。您可以在 AI 系統的所有三個層級解決這個問題:
- 資料:確保資料來源透明且平衡。
- 智慧:偵測、測試及減輕輸出內容中的偏誤。
- 使用者體驗:讓使用者透過控制和意見回饋功能,找出並修正偏誤。
信任與透明度
信任感決定使用者是否會使用、採用及推薦您的產品。
大多數使用者都希望應用程式能預測行為。舉例來說,按鈕點擊一律會執行指定動作,並導向相同位置。AI 的行為變化多端,且往往難以預測,因此打破了這項期望。此外,AI 系統本身就可能發生故障:語言模型會產生事實幻覺、預測模型會錯誤標記資料,以及代理程式會失控。
使用者是防範這類錯誤的最後一道防線。
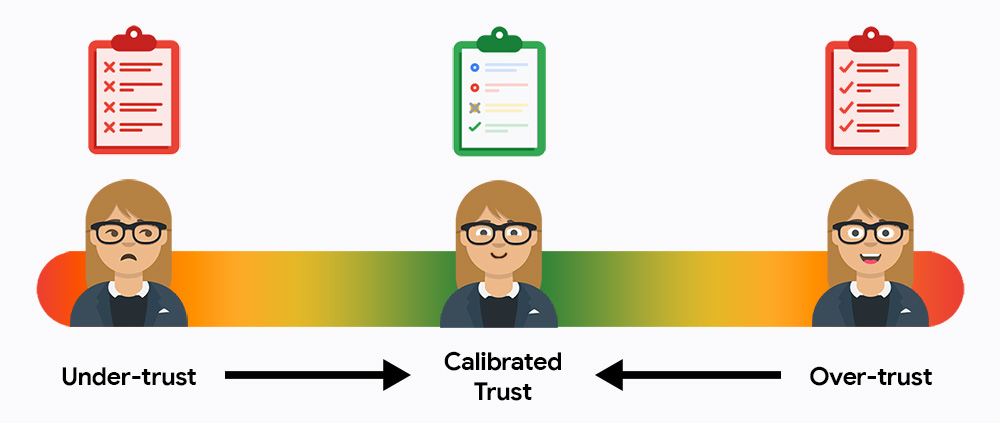
一開始,使用者可能過度或過度不信任您的系統。 如果信任度不足,使用者就不會使用系統;如果信任度過高,使用者就會完全接受輸出內容,而不會檢查是否有錯誤。您的任務是將使用者帶入校準信任的黃金中點,讓他們在依賴 AI 提升效率的同時,仍對最終結果負責。
資料
在資料層,清楚說明資料的涵蓋範圍和出處,有助於建立信任感:
- 明確說明資料來源和歷程。
- 記錄資料更新間隔和過時程度。
- 說明模型看過的內容類型,以及模型可能難以處理的內容,例如非英文資料。
隨著 AI 系統累積互動和意見回饋,請考慮維護資料的版本化快照,以便說明輸出內容的演變過程。
情報
在智慧層中,您可以透過可解釋性、信賴指標和模組化設計來管理信任:
- 提供符合情境的即時說明。根據活躍使用者悖論,您最好在互動中直接嵌入微型說明,讓使用者瞭解 AI 系統在他們使用時的運作方式。
- 預先說明限制和故障模式。告知使用者 AI 可能會出錯的地方。舉例來說,「避免使用幽默或領域術語,以獲得更佳結果。」簡短的脈絡提示可提供透明度,不會中斷流程。
- 信心指標和備援邏輯可確保 AI 在不確定情況下仍能提供可靠結果。您可以根據機率分數或過往成功率等替代指標,估算信心指數。為明顯不正確的輸出內容定義安全的回退機制。
- 模組化架構可提高 AI 透明度。舉例來說,如果寫作助理會分階段處理文法、風格和語氣,請指出每個階段的變化:「語氣:較不正式;複雜度:簡化」。
使用者體驗
使用者體驗是建立及校正信任感的大好機會。以下是一些可嘗試的技巧和模式:
- 調整教育內容。請勿假設使用者精通 AI。 為進階使用者提供簡要指引,為新手提供詳細說明。
- 採用漸進式揭露。先從簡單的提示開始。加入說明您使用 AI 的文案,例如「這是自動生成的內容」,並讓使用者點選查看更多深入分析資訊。
- 透過可見的結果關閉意見回饋迴路。當使用者評估、修正或覆寫 AI 建議時,請說明他們的輸入內容如何影響未來的行為:「您偏好簡潔的回覆。並相應調整語氣。」公開透明能將意見回饋轉化為信任。
- 明確解釋錯誤原因。如果系統出錯或提供低信賴度的結果,請確認並將審查工作委派給使用者。舉例來說,「這項建議可能不符合您的意圖。發布前請先確認。」 提供明確的解決途徑,讓使用者重試、編輯或還原至安全備份。
簡而言之,為解決 AI 的不確定性和潛在錯誤,請引導使用者從懷疑或過度依賴,轉為適當信任:
- 資料:公開資料來源。
- 智慧:讓推理過程模組化,並提供說明。
- UX:設計時應逐步提供清楚的資訊和意見回饋。
重點摘要
在本單元中,我們探討了負責任 AI 的三大核心支柱,也就是隱私權、公平性和信任感。這可能會讓人感到不知所措,尤其是剛開始或嘗試從原型轉移到正式環境時。
專注於最關鍵的領域,並定義自己的 AI 治理方法。疊代是關鍵。每次發布版本和收集使用者意見回饋,都能幫助您進一步瞭解系統哪些方面需要更多防護措施、透明度或彈性。
資源
以下提供一些進階資源,進一步瞭解本單元的主題:
- AI 助理隱私權和安全性比較:深入瞭解 AI 隱私權政策。
- LLM 記憶論文:這是一種嚴重的隱私權失效模式,模型會保留訓練資料中的特定機密資訊,並可透過提示重現這些資訊。
- 查看與所選模型直接相關的資源。舉例來說,Google Cloud 提供安全防護資源。
- 負責任的 AI 工具包提供開發人員資源,涵蓋本單元的所有主題。
資源
以下提供一些進階資源,進一步瞭解本單元的主題:
- AI 助理隱私權和安全性比較 深入探討 AI 隱私權政策。
- LLM 記憶論文:這是一種嚴重的隱私權失敗模式,模型會保留訓練資料中的特定機密資訊,並在收到提示時重現這些資訊。
- 查看與所選模型直接相關的資源。例如,Google Cloud 提供安全資源。
- 負責任的 AI 工具包提供開發人員資源,涵蓋本單元的所有主題。
隨堂測驗
在收集 AI 資料時,建議採取哪些隱私權做法?
什麼是校準信任?
為確保「智慧」層的公平性,開發人員可以採取哪些行動?
有哪些使用者體驗技巧可建立信任感和透明度?