
W ostatniej sekcji dowiedzieliśmy się, że nawet jeśli nie znasz znaczenia słów na stronie, ale elementy semantyczne nadają dokumentowi znaczącą strukturę, inni – wyszukiwarka, technologie wspomagające, przyszły opiekun, nowy członek zespołu – zrozumieją zarys dokumentu.
W tej sekcji poznasz strukturę dokumentu, przypomnisz sobie elementy sekcji z poprzedniej sekcji i oznaczysz zarys aplikacji.
Jeśli podczas kodowania wybierzesz odpowiednie elementy, nie będziesz musiał refaktoryzować ani komentować kodu HTML. Jeśli zastanowisz się nad użyciem odpowiedniego elementu, najczęściej wybierzesz właściwy element. Jeśli tego nie zrobisz, prawdopodobnie nie wybierzesz odpowiedniego elementu.
Teraz, gdy rozumiesz semantykę znaczników i wiesz, dlaczego ważne jest wybranie odpowiedniego elementu, po zapoznaniu się z różnymi elementami będziesz zwykle wybierać właściwy element bez większego wysiłku.
Witryna <header>
Najpierw utwórz nagłówek witryny. Zacznij od znaczników niesemantycznych i stopniowo przechodź do dobrego rozwiązania, aby po drodze poznać zalety elementów HTML section i heading.
Jeśli nie zastanowisz się nad semantyką nagłówka, możesz użyć takiego kodu:
<!-- start header -->
<div id="pageHeader">
<div id="title">Machine Learning Workshop</div>
<!-- navigation -->
<div id="navigation">
<a href="#reg">Register</a>
<a href="#about">About</a>
<a href="#teachers">Instructors</a>
<a href="#feedback">Testimonials</a>
</div>
<!-- end navigation bar -->
</div>
<!-- end of header -->
CSS może sprawić, że (prawie) każdy znacznik będzie wyglądać prawidłowo. Jednak używanie niesemantycznego elementu <div> do wszystkiego powoduje dodatkową pracę. Aby kierować na wiele elementów <div> za pomocą CSS, musisz używać identyfikatorów lub klas do identyfikowania treści. Kod zawiera też komentarz do każdego zamykającego elementu </div>, aby wskazać, który tag otwierający zamyka dany element </div>.
Atrybuty id i class zapewniają punkty zaczepienia do stylizowania i JavaScriptu, ale nie dodają wartości semantycznej dla czytnika ekranu i (w większości przypadków) wyszukiwarek.
Możesz dodać atrybuty role, aby zapewnić semantykę i utworzyć dobry model obiektów ułatwień dostępu (AOM) dla czytników ekranu:
<!-- start header -->
<div role="banner">
<div role="heading" aria-level="1">Machine Learning Workshop</div>
<div role="navigation">
<a href="#reg">Register</a>
<a href="#about">About</a>
<a href="#teachers">Instructors</a>
<a href="#feedback">Testimonials</a>
</div>
<!-- end navigation bar -->
</div>
<!-- end of header -->
Dzięki temu uzyskasz co najmniej semantykę i możliwość używania selektorów atrybutów w CSS, ale nadal musisz dodawać komentarze, aby określić, który element <div> zamyka dany element </div>.
Jeśli znasz HTML, wystarczy, że zastanowisz się nad przeznaczeniem treści. Następnie możesz napisać ten kod semantycznie bez używania atrybutu role i bez konieczności komentowania tagów zamykających:
<header>
<h1>Machine Learning Workshop</h1>
<nav>
<a href="#reg">Register</a>
<a href="#about">About</a>
<a href="#teachers">Instructors</a>
<a href="#feedback">Testimonials</a>
</nav>
</header>
Ten kod używa 2 semantycznych punktów orientacyjnych: <header> i <nav>.
To jest główny nagłówek. Element <header> nie zawsze jest punktem orientacyjnym. Ma inną semantykę w zależności od tego, gdzie jest zagnieżdżony. Gdy element <header> jest najwyższego poziomu, jest to banner witryny, czyli rola punktu orientacyjnego, co mogłeś zauważyć w bloku kodu role. Gdy element <header> jest zagnieżdżony w elementach <main>, <article> lub <section>, identyfikuje go tylko jako nagłówek tej sekcji i nie jest punktem orientacyjnym.
Element <nav> identyfikuje treść jako nawigację. Ponieważ ten element <nav> jest zagnieżdżony w nagłówku witryny, jest to główna nawigacja witryny. Jeśli byłby zagnieżdżony w elemencie <article> lub <section>, byłaby to nawigacja wewnętrzna tylko dla tej sekcji. Używając elementów semantycznych, utworzyłeś znaczący model obiektów ułatwień dostępu (AOM). Dzięki AOM czytnik ekranu może poinformować użytkownika, że ta sekcja składa się z głównego bloku nawigacyjnego, po którym można się poruszać lub go pominąć.
Użycie tagów zamykających </nav> i </header> eliminuje konieczność dodawania komentarzy, aby określić, który element zamyka dany tag końcowy. Ponadto używanie różnych tagów do różnych elementów eliminuje konieczność stosowania punktów zaczepienia id i class. Selektory CSS mogą mieć niską specyficzność. Prawdopodobnie możesz kierować na linki za pomocą header nav a bez obaw o konflikt.
Napisałeś nagłówek z bardzo małą ilością kodu HTML i bez klas ani identyfikatorów. Gdy używasz semantycznego kodu HTML, nie musisz tego robić.
Witryna <footer>
Zakoduj stopkę witryny.
<footer>
<p>©2022 Machine Learning Workshop, LLC. All rights reserved.</p>
</footer>
Podobnie jak w przypadku elementu <header>, to, czy stopka jest punktem orientacyjnym, zależy od tego, gdzie jest zagnieżdżona. Gdy jest to stopka witryny, jest punktem orientacyjnym i powinna zawierać informacje o stopce witryny, które mają się pojawiać na każdej stronie, np. oświadczenie o prawach autorskich, informacje kontaktowe oraz linki do polityki prywatności i polityki dotyczącej plików cookie. Domyślna role stopki witryny to contentinfo. W przeciwnym razie stopka nie ma domyślnej roli i nie jest punktem orientacyjnym, jak widać na zrzucie ekranu AOM w Chrome (który ma element <article> z elementami <header> i <footer> między nimi).<header><footer>
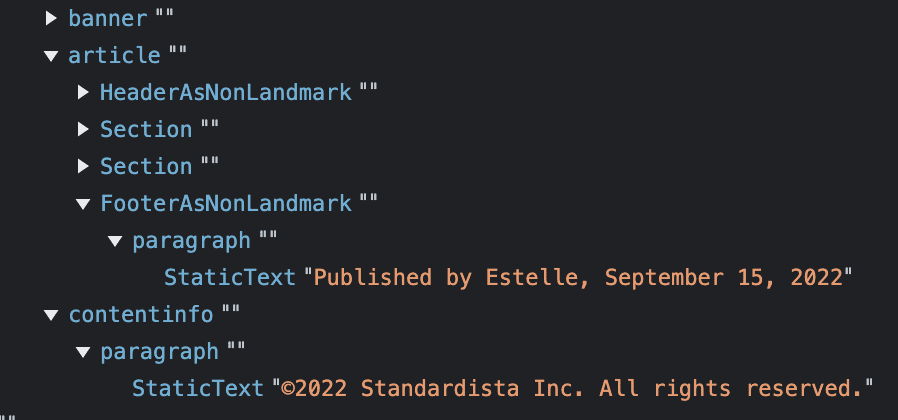
Na tym zrzucie ekranu widać 2 stopki: jedną w elemencie <article> i jedną na najwyższym poziomie. Stopka najwyższego poziomu jest punktem orientacyjnym z domyślną rolą contentinfo. Druga stopka nie jest punktem orientacyjnym. Chrome wyświetla ją jako FooterAsNonLandmark, a Firefox jako section.
Nie oznacza to, że nie należy używać elementu <footer>. Jeśli na przykład masz bloga, możesz mieć stopkę witryny z domyślną rolą contentinfo. Każdy post na blogu może też mieć element <footer>. Na głównej stronie docelowej bloga przeglądarka, wyszukiwarka i czytnik ekranu wiedzą, że główna stopka to stopka najwyższego poziomu, a wszystkie inne stopki są powiązane z postami, w których są zagnieżdżone.
Gdy element <footer> jest elementem potomnym elementu <article>, <aside>, <main>, <nav> lub <section>, nie jest punktem orientacyjnym. Jeśli post pojawia się samodzielnie, w zależności od znaczników stopka może zostać podniesiona.
W stopkach często można znaleźć informacje kontaktowe zawarte w elemencie <address>. Jest to jeden z elementów, który nie ma zbyt dobrej nazwy. Służy do umieszczania informacji kontaktowych osób lub organizacji, a nie fizycznych adresów pocztowych.
<footer>
<p>©2022 Machine Learning Workshop, LLC. All rights reserved.</p>
<address>Instructors: <a href="/hal.html">Hal</a> and <a href="/eve.html">Eve</a></address>
</footer>
Struktura dokumentu
Ten moduł zaczyna się od elementów <header> i <footer>, ponieważ tylko czasami są one elementami punktu orientacyjnego (lub „sekcji”). Istnieje kilka częściej używanych elementów sekcji.
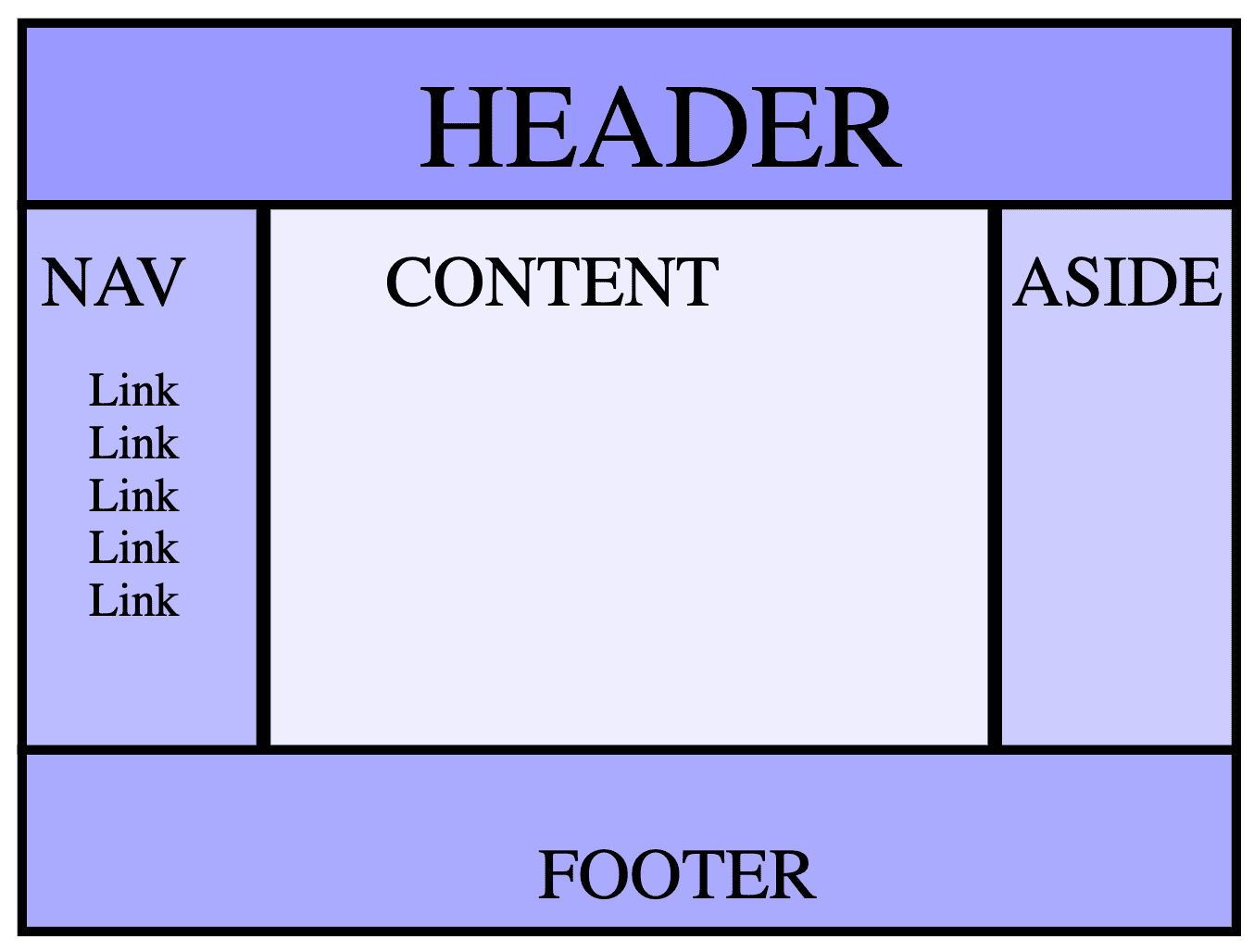
Układ z nagłówkiem, 2 paskami bocznymi i stopką jest znany jako układ świętego Graala. Istnieje wiele sposobów oznaczania tych treści, m.in.:
<body>
<header>Header</header>
<nav>Nav</nav>
<main>Content</main>
<aside>Aside</aside>
<footer>Footer</footer>
</body>
Jeśli tworzysz bloga, możesz mieć serię artykułów w <main>:
<body>
<header>Header</header>
<nav>Nav</nav>
<main>
<article>First post</article>
<article>Second post</article>
</main>
<aside>Aside</aside>
<footer>Footer</footer>
</body>
Gdy używasz elementów semantycznych, przeglądarki mogą tworzyć znaczące drzewa ułatwień dostępu. Ułatwia to poruszanie się po czytniku ekranu. W tym przypadku elementy banner i contentinfo są udostępniane przez elementy <header> i <footer> witryny. Nowe elementy dodane w tym miejscu to <main>, <aside> i <article>, a także elementy <h1> i <nav>, których używaliśmy wcześniej, oraz element <section>, którego jeszcze nie używaliśmy.
<main>
Jest jeden element punktu orientacyjnego <main>. Element <main> identyfikuje główną treść dokumentu. Na każdej stronie powinien znajdować się tylko jeden element <main>.
<aside>
Element <aside> służy do umieszczania treści, które są pośrednio lub stycznie powiązane z główną treścią dokumentu. Na przykład ten dokument dotyczy HTML. W przypadku sekcji dotyczącej specyficzności selektora CSS w 3 przykładach nagłówka witryny (div, role i semantic) stycznie powiązany element aside może być zawarty w elemencie <aside>. Podobnie jak w większości przypadków element <aside> będzie prawdopodobnie wyświetlany na pasku bocznym lub w polu z wezwaniem do działania. Element <aside> jest też punktem orientacyjnym z domyślną rolą complementary.
<article>
W elemencie <main> dodaliśmy 2 elementy <article>. Nie było to konieczne w pierwszym przykładzie, gdy główna treść była tylko jednym słowem, lub w rzeczywistości – pojedynczą sekcją treści. Jeśli jednak piszesz bloga, tak jak w naszym drugim przykładzie, każdy post powinien znajdować się w elemencie <article> zagnieżdżonym w elemencie <main>.
Element <article> reprezentuje kompletną lub samodzielną sekcję treści, którą można w zasadzie ponownie wykorzystać niezależnie. Pomyśl o artykule tak jak o artykule w gazecie. W druku artykuł o Jacindzie Ardern, premier Nowej Zelandii, może się pojawić tylko w jednej sekcji, np. w wiadomościach ze świata. W witrynie gazety ten sam artykuł może się pojawić na stronie głównej, w sekcji polityka, w sekcji wiadomości z Oceanii lub Azji i Pacyfiku, a w zależności od tematu wiadomości – być może także w sekcji sport, styl życia lub technologia. Artykuł może się też pojawić w innych witrynach, np. Pocket lub Yahoo News.
<section>
Element <section> służy do obejmowania ogólnych, samodzielnych sekcji dokumentu, gdy nie ma bardziej szczegółowego elementu semantycznego. Sekcje powinny mieć nagłówek, z kilkoma wyjątkami.
Wracając do przykładu z Jacindą Ardern, na stronie głównej gazety baner będzie zawierać nazwę gazety, a następnie pojedynczy element <main>, podzielony na kilka elementów <section>, z których każdy będzie mieć nagłówek, np. „Wiadomości ze świata” i „Polityka”. W każdej sekcji znajdziesz serię elementów <article>. W każdym elemencie <article> możesz też znaleźć co najmniej 1 element <section>. Jeśli spojrzysz na tę stronę, cała część „Nagłówki i sekcje” to element <article>. Ten element <article> jest następnie podzielony na kilka elementów <section>, w tym site header, site footer i struktura dokumentu. Sam artykuł ma nagłówek, podobnie jak każda z sekcji.
Element <section> nie jest punktem orientacyjnym, chyba że ma nazwę na potrzeby ułatwień dostępu. Jeśli ma nazwę na potrzeby ułatwień dostępu, domyślna rola to region. Role punktów orientacyjnych należy stosować oszczędnie, aby identyfikować większe ogólne sekcje dokumentu. Używanie zbyt wielu ról punktów orientacyjnych może powodować "szum" w czytnikach ekranu, co utrudnia zrozumienie ogólnego układu strony. Jeśli element <main> zawiera 2 lub 3 ważne podsekcje, może być korzystne dodanie nazwy na potrzeby ułatwień dostępu do każdego elementu <section>.
Nagłówki: <h1>-<h6>
Istnieje 6 elementów nagłówka sekcji: <h1>, <h2>, <h3>, <h4>, <h5>, i <h6>. Każdy z nich reprezentuje jeden z 6 poziomów nagłówków sekcji. <h1> to najwyższy lub najważniejszy poziom sekcji, a <h6> – najniższy.
Gdy nagłówek jest zagnieżdżony w banerze dokumentu <header>, jest to nagłówek aplikacji lub witryny. Gdy jest zagnieżdżony w elemencie <main>, niezależnie od tego, czy jest zagnieżdżony w elemencie <header> w elemencie <main>, jest to nagłówek tej strony, a nie całej witryny. Gdy jest zagnieżdżony w elemencie <article> lub <section>, jest to nagłówek tej podsekcji strony.
Zalecamy używanie poziomów nagłówków podobnie jak w edytorze tekstu: zaczynając od elementu <h1> jako głównego nagłówka, z elementem <h2> jako nagłówkami podsekcji, a z elementem <h3> – jeśli te podsekcje mają sekcje. Unikaj pomijania poziomów nagłówków. Tutaj znajdziesz dobry artykuł o nagłówkach sekcji.
Niektórzy użytkownicy czytników ekranu korzystają z nagłówków, aby zrozumieć treść strony. Pierwotnie nagłówki miały służyć do tworzenia zarysu dokumentu, tak jak MS Word czy Dokumenty Google mogą tworzyć zarys na podstawie nagłówków, ale przeglądarki nigdy nie wdrożyły tej struktury. Przeglądarki wyświetlają zagnieżdżone nagłówki w coraz mniejszych rozmiarach czcionek, jak pokazano w poniższym przykładzie, ale nie obsługują tworzenia zarysów.
Masz teraz wystarczającą wiedzę, aby utworzyć zarys witryny MachineLearningWorkshop.com:
Tworzenie zarysu elementu <body> w MLW.com
To jest zarys widocznej treści witryny warsztatów z uczenia maszynowego:
Ponieważ żadna treść nie jest samodzielna, kompletna, element <section> jest bardziej odpowiedni niż <article>. Każda sekcja ma nagłówek, ale żadna nie zasługuje na element <footer>.
Nie trzeba chyba dodawać, że nie należy używać nagłówków do pogrubiania ani powiększania tekstu. Zamiast tego użyj CSS. Jeśli chcesz wyróżnić tekst, możesz też użyć elementów semantycznych. Omówimy to i wypełnimy większość treści strony, gdy będziemy omawiać podstawy tekstu, po dokładniejszym zapoznaniu się z atrybutami.
Sprawdź swoją wiedzę
Sprawdź swoją wiedzę na temat nagłówków i sekcji.
Który element służy do umieszczania obszaru witryny, który zawiera logo lub tytuł witryny oraz główną nawigację?
<heading><header><title>Ile elementów <main> jest dozwolonych na stronie?