

Einführung
Media Source Extensions (MSE)
bieten erweiterte Pufferungs- und Wiedergabesteuerung für die HTML5-Elemente <audio> und
<video>. Sie wurden ursprünglich entwickelt, um
videobasierte Player mit Dynamic Adaptive Streaming over HTTP (DASH)
zu unterstützen. Im Folgenden sehen wir uns an, wie sie für Audio verwendet werden können, insbesondere für die
lückenlose Wiedergabe.
Sie haben wahrscheinlich schon ein Musikalbum gehört, bei dem die Songs nahtlos ineinander übergingen. Vielleicht hören Sie gerade eines. Künstler erstellen diese lückenlose Wiedergabe sowohl aus künstlerischen Gründen als auch als Artefakt von Schallplatten und CDs, bei denen Audio als ein kontinuierlicher Stream aufgezeichnet wurde. Aufgrund der Funktionsweise moderner Audiocodecs wie MP3 und AAC geht diese nahtlose Hörerfahrung heute leider oft verloren.
Wir gehen unten auf die Details ein, aber beginnen wir mit einer Demonstration. Unten sehen Sie die ersten 30 Sekunden des hervorragenden Films Sintel, aufgeteilt in fünf separate MP3 Dateien und mit MSE wieder zusammengesetzt. Die roten Linien zeigen Lücken an, die bei der Erstellung (Codierung) der einzelnen MP3-Dateien entstanden sind. An diesen Stellen hören Sie Störungen.
Igitt! Das ist keine gute Erfahrung. Wir können es besser machen. Mit etwas mehr Aufwand können wir mit genau denselben MP3-Dateien aus der obigen Demo MSE verwenden, um diese störenden Lücken zu entfernen. Die grünen Linien in der nächsten Demo zeigen, wo die Dateien zusammengefügt und die Lücken entfernt wurden. In Chrome 38 und höher wird die Wiedergabe nahtlos erfolgen.
Es gibt verschiedene Möglichkeiten, lückenlose Inhalte zu erstellen. Für diese Demo konzentrieren wir uns auf die Art von Dateien, die ein normaler Nutzer möglicherweise hat. Dabei wurde jede Datei separat codiert, ohne Rücksicht auf die Audiosegmente davor oder danach.
Grundlegende Einrichtung
Zuerst gehen wir zurück und behandeln die grundlegende Einrichtung einer MediaSource-Instanz.
Media Source Extensions sind, wie der Name schon sagt, nur Erweiterungen der vorhandenen Media-Elemente. Unten weisen wir dem Attribut „source“ eines Audioelements eine
Object URL, die unsere MediaSource Instanz darstellt, zu. Das ist genauso, wie Sie eine Standard-URL festlegen würden.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
Sobald das MediaSource Objekt verbunden ist, wird eine Initialisierung durchgeführt
und schließlich ein sourceopen Ereignis ausgelöst. An diesem Punkt können wir ein
SourceBuffer erstellen. Im
obigen Beispiel erstellen wir einen audio/mpeg-Puffer, der unsere MP3-Segmente parsen und
decodieren kann. Es gibt mehrere
andere Typen.
Ungewöhnliche Wellenformen
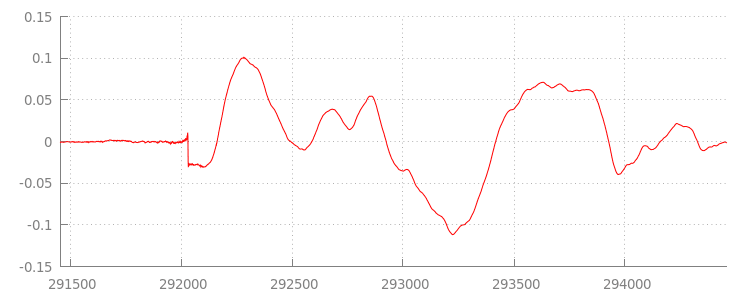
Wir kommen gleich zum Code zurück, aber sehen wir uns jetzt die Datei genauer an, die wir gerade angehängt haben, insbesondere das Ende. Unten sehen Sie ein Diagramm der letzten 3.000 Samples, gemittelt über beide Kanäle des Tracks sintel_0.mp3. Jedes Pixel auf der roten Linie ist ein
Gleitkomma-Sample
im Bereich von [-1.0, 1.0].

Was ist mit all diesen Null-Samples (Stille) los? Sie sind auf Komprimierungsartefakte zurückzuführen, die bei der Codierung entstanden sind. Fast jeder Encoder fügt eine Art Padding hinzu. In diesem Fall hat LAME genau 576 Padding-Samples am Ende der Datei hinzugefügt.
Neben dem Padding am Ende wurde jeder Datei auch am Anfang Padding hinzugefügt. Wenn wir uns den Track sintel_1.mp3 ansehen, sehen wir weitere 576 Samples Padding am Anfang. Die Menge
des Paddings variiert je nach Encoder und Inhalt, aber wir kennen die genauen Werte anhand von
metadata, die in jeder Datei enthalten sind.
Die Abschnitte mit Stille am Anfang und Ende jeder Datei verursachen die Störungen zwischen den Segmenten in der vorherigen Demo. Um eine lückenlose Wiedergabe zu erreichen, müssen wir diese Abschnitte mit Stille entfernen. Glücklicherweise ist das mit MediaSource ganz einfach. Unten ändern wir unsere Methode onAudioLoaded(), um ein
Append-Fenster und einen Zeitstempel
Offset zu verwenden, um diese Stille zu entfernen.
Beispielcode
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Eine nahtlose Wellenform
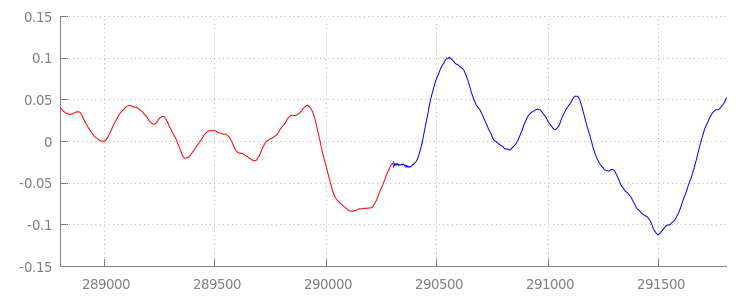
Sehen wir uns an, was unser neuer Code bewirkt hat, indem wir uns die Wellenform noch einmal ansehen, nachdem wir unsere Append-Fenster angewendet haben. Unten sehen Sie, dass der Abschnitt mit Stille am Ende von sintel_0.mp3 (rot) und der Abschnitt mit Stille am Anfang von sintel_1.mp3 (blau) entfernt wurden. So entsteht ein nahtloser Übergang zwischen den Segmenten.
Fazit
Damit haben wir alle fünf Segmente nahtlos zu einem zusammengefügt und sind am Ende unserer Demo angelangt. Bevor wir uns verabschieden, haben Sie vielleicht bemerkt, dass unsere Methode onAudioLoaded() keine Container oder Codecs berücksichtigt.
Das bedeutet, dass alle diese Techniken unabhängig vom Container- oder Codec-Typ funktionieren. Unten können Sie die ursprüngliche Demo mit fragmentiertem MP4-Format anstelle von MP3 wiedergeben, das für DASH geeignet ist.
Weitere Informationen finden Sie in den Anhängen unten. Dort wird die Erstellung lückenloser Inhalte und das Parsen von Metadaten genauer beschrieben. Sie können sich auch
gapless.js ansehen, um
den Code dieser Demo genauer zu betrachten.
Vielen Dank, dass Sie sich die Zeit zum Lesen dieser E-Mail genommen haben.
Anhang A: Lückenlose Inhalte erstellen
Es kann schwierig sein, lückenlose Inhalte richtig zu erstellen. Unten sehen Sie, wie die in dieser Demo verwendeten Sintel-Medien erstellt wurden. Zuerst benötigen Sie eine Kopie des verlustfreien FLAC-Soundtracks für Sintel. Der SHA1 ist unten aufgeführt. Für die Tools benötigen Sie FFmpeg, MP4Box, LAME und eine OSX-Installation mit afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Zuerst teilen wir die ersten 31, 5 Sekunden des Tracks 1-Snow_Fight.flac auf. Außerdem möchten wir ab der 28.Sekunde einen 2,5 Sekunden langen Fade-out hinzufügen, um Klicks nach dem Ende der Wiedergabe zu vermeiden. Mit der folgenden FFmpeg-Befehlszeile können wir all das erreichen und die Ergebnisse in sintel.flac speichern.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Als Nächstes teilen wir die Datei in fünf Wave
Dateien mit jeweils 6,5 Sekunden auf.Wave ist am einfachsten zu verwenden, da fast jeder Encoder
die Aufnahme unterstützt. Auch das können wir genau mit FFmpeg tun. Danach haben wir folgende Dateien: sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav und sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
Erstellen wir nun die MP3-Dateien. LAME bietet mehrere Optionen zum Erstellen lückenloser Inhalte. Wenn Sie die Kontrolle über die Inhalte haben, können Sie --nogap mit einer Batch-Codierung aller Dateien verwenden, um Padding zwischen den Segmenten ganz zu vermeiden.
Für diese Demo möchten wir jedoch Padding verwenden. Daher verwenden wir eine standardmäßige VBR-Codierung der Wave-Dateien in hoher Qualität.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
Das ist alles, was zum Erstellen der MP3-Dateien erforderlich ist. Sehen wir uns nun die Erstellung der fragmentierten MP4-Dateien an. Wir folgen den Anweisungen von Apple zum Erstellen von Medien, die für iTunes gemastert wurden. Unten konvertieren wir die Wave-Dateien gemäß den Anweisungen in CAF-Zwischendateien CAF, bevor wir sie mit den empfohlenen Parametern als AAC in einem MP4 Container codieren.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Wir haben jetzt mehrere M4A-Dateien, die wir entsprechend
fragmentieren
müssen, bevor sie mit
MediaSourceverwendet werden können. Für unsere Zwecke verwenden wir eine Fragmentgröße von einer Sekunde. MP4Box schreibt jede fragmentierte MP4-Datei als sintel_#_dashinit.mp4 zusammen mit einem MPEG-DASH-Manifest (sintel_#_dash.mpd), das verworfen werden kann.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
Jetzt weißt du Bescheid. Wir haben jetzt fragmentierte MP4- und MP3-Dateien mit den richtigen Metadaten, die für die lückenlose Wiedergabe erforderlich sind. Weitere Informationen dazu, wie diese Metadaten aussehen, finden Sie in Anhang B.
Anhang B: Lückenlose Metadaten parsen
Wie beim Erstellen lückenloser Inhalte kann auch das Parsen der lückenlosen Metadaten schwierig sein, da es keine Standardmethode für die Speicherung gibt. Unten sehen Sie, wie die beiden häufigsten Encoder, LAME und iTunes, ihre lückenlosen Metadaten speichern. Zuerst richten wir einige Hilfsmethoden und eine Gliederung für die oben verwendete Methode ParseGaplessData() ein.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Wir beginnen mit dem Metadatenformat von Apple iTunes, da es am einfachsten zu parsen und zu erklären ist. In MP3- und M4A-Dateien schreiben iTunes (und afconvert) einen kurzen Abschnitt in ASCII, wie hier:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Dieser wird in einem ID3-Tag im MP3-Container und in einem Metadaten-Atom im MP4-Container geschrieben. Für unsere Zwecke können wir das erste Token 0000000 ignorieren. Die nächsten drei Tokens sind das Padding am Anfang, das Padding am Ende und die Gesamtzahl der Samples ohne Padding. Wenn wir jeden dieser Werte durch die Samplerate des Audios dividieren, erhalten wir die Dauer für jeden Wert.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
Die meisten Open-Source-MP3-Encoder speichern die lückenlosen Metadaten in einem speziellen Xing-Header , der in einem stummen MPEG-Frame platziert wird. Da er stumm ist, geben Decoder, die den Xing-Header nicht verstehen, einfach Stille wieder. Leider ist dieses Tag nicht immer vorhanden und hat eine Reihe optionaler Felder. Für diese Demo haben wir die Kontrolle über die Medien, aber in der Praxis sind einige zusätzliche Sensibilitätsprüfungen erforderlich, um zu wissen, wann lückenlose Metadaten tatsächlich verfügbar sind.
Zuerst parsen wir die Gesamtzahl der Samples. Der Einfachheit halber lesen wir diesen Wert aus
dem Xing-Header, er könnte aber auch aus dem normalen
MPEG-Audio-Header erstellt werden.
Xing-Header können mit einem Xing- oder Info-Tag gekennzeichnet werden. Genau 4 Byte nach diesem Tag befinden sich 32 Bit, die die Gesamtzahl der Frames in der Datei darstellen. Wenn wir diesen Wert mit der Anzahl der Samples pro Frame multiplizieren, erhalten wir die Gesamtzahl der Samples in der Datei.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Nachdem wir die Gesamtzahl der Samples haben, können wir die Anzahl der Padding-Samples lesen. Je nach Encoder kann dieser Wert unter einem LAME- oder Lavf-Tag geschrieben werden, das im Xing-Header verschachtelt ist. Genau 17 Byte nach diesem Header befinden sich 3 Byte, die das Padding am Anfang und am Ende mit jeweils 12 Bit darstellen.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Damit haben wir eine vollständige Funktion zum Parsen der meisten lückenlosen Inhalte. Es gibt jedoch viele Sonderfälle. Daher ist Vorsicht geboten, bevor Sie ähnlichen Code in der Produktion verwenden.
Anhang C: Garbage Collection
Der Speicher, der zu SourceBuffer-Instanzen gehört, wird aktiv gemäß Inhaltstyp, plattformspezifischen Limits und der aktuellen Wiedergabeposition freigegeben. In Chrome wird der Speicher zuerst aus bereits wiedergegebenen Puffern freigegeben.
Wenn die Arbeitsspeichernutzung jedoch die plattformspezifischen Limits überschreitet, wird Arbeitsspeicher aus nicht wiedergegebenen Puffern entfernt.
Wenn die Wiedergabe aufgrund von freigegebenem Speicher eine Lücke in der Zeitachse erreicht, kann es zu Störungen kommen, wenn die Lücke klein genug ist, oder die Wiedergabe kann ganz anhalten, wenn die Lücke zu groß ist. Beides ist keine gute Nutzererfahrung. Daher ist es wichtig, nicht zu viele Daten auf einmal anzuhängen und nicht mehr benötigte Bereiche manuell aus der Zeitachse der Medien zu entfernen.
Bereiche können mit der
remove()
Methode für jeden SourceBuffer entfernt werden. Diese Methode verwendet einen [start, end] Bereich in Sekunden.
Ähnlich wie bei appendBuffer() löst jede remove()-Methode nach Abschluss ein updateend-Ereignis aus. Andere Entfernungen oder Anhänge sollten erst nach dem Auslösen des Ereignisses erfolgen.
Auf einem Desktop-Computer mit Chrome können Sie ungefähr 12 MB Audioinhalte und 150 MB Videoinhalte gleichzeitig im Speicher behalten. Sie sollten sich nicht auf diese Werte für andere Browser oder Plattformen verlassen. Sie sind beispielsweise mit Sicherheit nicht repräsentativ für Mobilgeräte.
Die automatische Speicherbereinigung wirkt sich nur auf Daten aus, die SourceBuffers hinzugefügt wurden. Es gibt keine Limits für die Menge an Daten, die Sie in JavaScript-Variablen puffern können. Sie können dieselben Daten bei Bedarf auch an derselben Position wieder anhängen.