
As you craft prompts for real applications, a key trade-off emerges: balancing brevity with effectiveness. When all factors are equal, a concise prompt is faster, cheaper, and easier to maintain than a longer prompt. This is especially relevant in web environments where latency and token limits matter. However, if your prompt is too minimal, the model may lack the context, instructions, or examples to produce high-quality results.
Evaluation-driven development (EDD) lets you systematically monitor and optimize this trade-off. It offers a repeatable, testable process for improving outputs in small and confident steps, catching regressions, and aligning model behavior with user and product expectations over time.
Think of it as test-driven development (TDD), adapted for the uncertainty of AI. Unlike deterministic unit tests, AI evaluations cannot be hard-coded because outputs, both well-formed and failing ones, can take unanticipated forms.
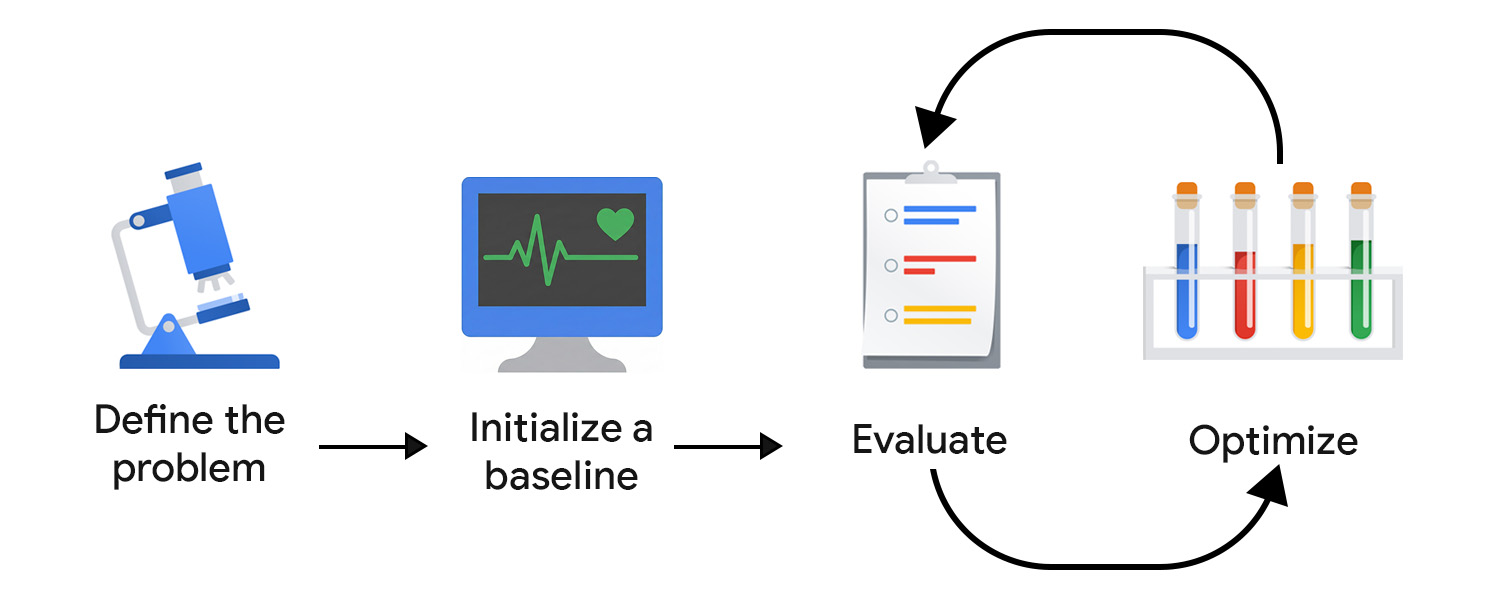
EDD also supports your discovery efforts. Just like writing tests helps clarify the behavior of a feature, defining evaluation criteria and reviewing model outputs forces you to confront lack of clarity and gradually add more detail and structure to open-ended or unfamiliar tasks.
Define the problem
You can frame your problem like an API contract, including the input type, the output format, and any additional constraints. For example:
- Input type: Blog post draft
- Output format: JSON array with 3 post titles
- Constraints: less than 128 characters, using a friendly tone
Then, collect example inputs. To ensure data diversity, you include both ideal examples and real, messy inputs. Think about variations and edge cases, such as posts with emoji, nested structure, and a lot of code snippets.
Initialize a baseline
Write your first prompt. Start with zero-shot and include clear instructions, output format, and a variable placeholder for the input content.
You'll increase the complexity of your system and work with additional components or prompting techniques to optimize your AI system. To ensure we use our time efficiently and optimize the right components, you need to set up an evaluation system.
Create your evaluation system
In TDD, you start writing tests once you know the requirements. With generative AI, there are no definitive outputs to test against, so you need to put more effort into crafting your evaluation loop.
You likely need multiple measurement tools to evaluate effectively.
Define your evaluation metrics
Evaluation metrics can be deterministic, meaning there is a known, correct answer. For example, you can check if the model returns valid JSON or outputs the correct number of items.
However, with AI, you'll spend most of your time dedicated to identifying and refining subjective, qualitative measurements. This includes output quality, usefulness, tone, and creativity. You may start with broader success goals, for how the output should meet your expectations. Eventually, you'll encounter specific, nuanced problems that help you better define your goals.
For example, say your title generator overuses certain phrases or patterns, leading to repetitive, robotic results. In that case, you should define new metrics to encourage variation and discourage overused structures or keywords. Over time, your core metrics will stabilize and you can track improvements.
This process can benefit from experts who understand what good looks like in your application's domain and can spot subtle failure modes. For example, if you're developing a writing assistant, pair up with a content producer or editor to ensure your evaluation is aligned with their worldview.
Choose your judges
Different evaluation criteria call for different evaluators:
- Code-based checks work well for deterministic or rule-based outputs. For example, you might scan titles for words you want to avoid, check character counts, or validate JSON structure. These are fast, repeatable, and perfect for fixed-output UI elements, such as buttons or form fields.
- Human feedback is essential for assessing more subjective qualities, including tone, clarity, or usefulness. Especially early on, reviewing model outputs yourself (or with domain experts) allows for rapid iteration. However, this approach doesn't scale well. Once you launch your application, you can also collect in-app signals, such as a star rating, but these tend to be noisy and lack the nuance needed for precise optimization.
- LLM-as-judge offers a scalable way to evaluate subjective criteria by using another AI model to score or critique outputs. It's faster than human review, but not without pitfalls: in a naive implementation, it can perpetuate and even reinforce the biases and knowledge gaps of the model.
Prioritize quality over quantity. In classic machine learning and predictive AI, it's a common practice to crowdsource data annotation. For generative AI, crowdsourced annotators often lack domain context. High-quality, context-rich evaluation matters more than scale.
Evaluate and optimize
The faster you can test and refine your prompts, the sooner you'll arrive at something that aligns with user expectations. You need to get into a habit of continuous optimization. Try an improvement, evaluate, and try something else.
Once in production, continue observing and evaluating the behavior of your users and your AI system. Then, analyze and transform this data into optimization steps.
Automate your evaluation pipeline
To reduce friction in your optimization efforts, you need operational infrastructure that automates evaluation, tracks changes, and connects development to production. This is commonly referred to as LLMOps. While there are platforms that can help with automation, you should design your ideal workflow before committing to a third-party solution.
Here are some key components to consider include:
- Versioning: Store prompts, evaluation metrics, and test inputs in version control. Treat them as code to ensure reproducibility and clear change history.
- Automated batch evaluations: Use workflows (such as GitHub Actions) to run evaluations on each prompt update and generate comparison reports.
- CI/CD for prompts: Gate deployments with automated checks, such as deterministic tests, LLM-as-judge scores, or guardrails, and block merges when quality regresses.
- Production logging and observability: Capture inputs, outputs, errors, latency, and token usage. Monitor for drift, unexpected patterns, or spikes in failures.
- Feedback ingestion: Collect user signals (thumbs, rewrites, abandonment) and turn recurring issues into new test cases.
- Experiment tracking: Track prompt versions, model configurations, and evaluation results.
Iterate with small, targeted changes
Prompt refinement typically begins with improving your prompt's language. This could mean making instructions more specific, clarifying intent, or removing ambiguities.
Be careful not to overfit. A common mistake is to add overly narrow rules to patch model issues. For example, if your title generator keeps producing titles that start with The Definitive Guide, it may be tempting to explicitly forbid this phrase. Instead, abstract the issue and adjust the higher-level instruction. This could mean you emphasize originality, variety, or a specific editorial style, so the model learns the underlying preference rather than a single exception.
Another pathway is experimenting with more prompting techniques and combining these efforts. When you choose a technique, ask yourself: is this task best solved through analogy (few-shot), step-by-step reasoning (chain-of-thought), or iterative refinement (self-reflection)?
When your system goes to production, your EDD flywheel shouldn't slow down. If anything, it should accelerate. If your system processes and logs user input, these should become your most valuable source of insight. Add recurring patterns to your evaluation suite, and continuously identify and implement the next best optimization steps.
Your takeaways
Evaluation-driven prompt development gives you a structured way to navigate the uncertainty of AI. By defining your problem clearly, building a tailored evaluation system, and iterating through small, targeted improvements, you create a feedback loop that steadily improves model outputs.
Resources
Here are some recommended readings if you want to implement LLM-as-judge:
- Compare LLM capability with summarization.
- Read Hamel Husain's guide to using LLM-as-a-Judge.
- Read the paper: A Survey on LLM-as-a-Judge.
If you're interested in further improving your prompts, read more about context-aware development. This is best done by a machine learning engineer.
Check your understanding
What is the primary goal of evaluation-driven development?
Why use larger models to evaluate a client-side system?
What is a potential pitfall of using LLM-as-a-judge for evaluation?
Which component is part of a recommended automated evaluation pipeline?
When choosing judges for your evaluation system, what is the main limitation of using human feedback?