
在利用 AI 构建应用之前,您必须选择托管该应用的平台。您的选择会影响 AI 系统的速度、成本、可伸缩性和可信度。您可以从以下选项中进行选择:
- 客户端 AI:直接在浏览器中运行。这意味着数据可以保留在用户设备上,保持私密性,并且不会产生网络延迟。不过,为了实现良好的性能,客户端 AI 需要高度具体、明确定义的应用场景。
- 服务器端 AI:在云端运行。它功能强大且可伸缩性高,但在延迟时间和费用方面成本更高。
每种方案都有利有弊,具体选择哪种设置取决于您的使用情形、团队技能和资源。例如,您可以提供在本地运行的总结工具,以便用户提出个人问题,而无需管理个人身份信息 (PII)。不过,客户支持代理可以使用基于云的模型来访问庞大的资源数据库,从而提供更有用的答案。
在本模块中,您将学习如何:
- 比较客户端 AI 和服务器端 AI 之间的权衡取舍。
- 根据您的使用场景和团队能力选择合适的平台。
- 设计混合系统,在客户端和服务器上提供 AI,以便随着产品的发展而发展。
查看选项
对于部署,请从两个主要方面考虑 AI 平台。您可以选择:
- 模型运行位置:是在客户端还是服务器端运行?
- 可自定义程度:您对模型的知识和功能有多大的控制权?如果您可以控制模型(即可以修改模型权重),则可以自定义其行为,以满足您的特定要求。
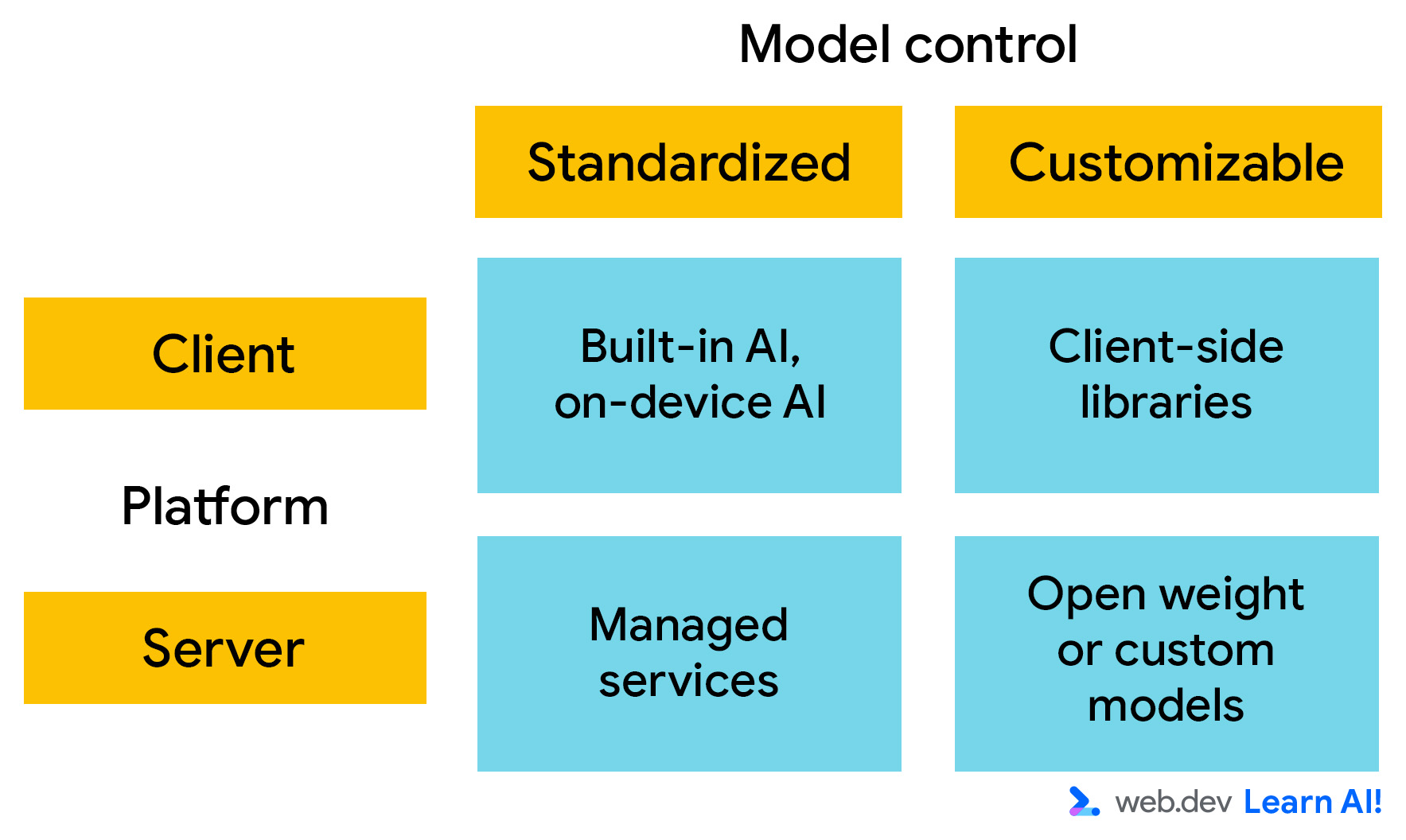
客户端 AI
客户端 AI 在浏览器中运行,计算在用户的设备上本地进行。您无需提供推理时计算,数据会保留在用户的设备上。这使得它快速、私密,适合轻量级互动体验。
不过,客户端模型通常很小,这可能会限制其功能和性能。它们最适合用于高度专业化的任务,例如检测有害内容或进行情感分析。这些任务通常是预测性 AI 任务,具有有限的输出空间。
主要有两种方案:
- 内置 AI:Google Chrome 和 Microsoft Edge 等浏览器正在集成 AI 模型。这些 API 可通过 JavaScript 调用进行访问,无需设置或托管。下载模型后,所有使用该模型的网站都可以调用它。
- 自定义模型:您可以使用 Transformers.js 和 MediaPipe 等客户端库将模型集成到应用中。这意味着您可以控制模型权重。不过,这也意味着您网站的每位用户都必须下载您的自定义模型。即使是最小的 AI 模型,对于网站而言也是很大的。
服务器端 AI
借助服务器端 AI,您的 Web 应用可以调用 API 将输入内容发送到 AI 模型并接收其输出内容。此设置支持更大、更复杂的模型,并且不受用户硬件的限制。
服务器端 AI 分为以下两类:
- 托管式服务:这些模型由第三方托管在数据中心内,例如 Gemini 3 和 GPT-5。模型所有者会提供一个 API 来访问该模型。这意味着,您只需进行最少的设置即可使用最先进的模型。这些模型非常适合快速原型设计、开放式对话和通用推理。 不过,在托管式服务上进行扩缩可能成本高昂。
- 自行托管的模型:您可以在自己的基础设施中或在受管理的容器(例如 Vertex AI 或 Hugging Face Inference)中部署开放权重模型,例如 Gemma 或 Llama。 这意味着您可以受益于模型创建者完成的预训练,但仍可控制模型、微调数据和性能。
选择初始平台
查看 AI 平台的架构特征并分析权衡取舍,以确定初始设置。
定义架构要求
每次做出决定时,您都必须做出妥协。不妨了解一下决定 AI 平台成本和价值的关键特征:
- 模型能力:模型在各种用户和任务中的表现,无需调优。这通常与模型大小相关。
- 可自定义程度:您可以对模型行为和架构进行微调、修改或控制的程度。
- 准确率:模型预测或生成结果的总体质量和可靠性。
- 隐私:用户数据保留在本地并受用户控制的程度。
- 固定成本:无论使用情况如何,运行 AI 系统所需的周期性支出,包括基础设施预配和维护。
- 每次请求的费用:每次传入请求的额外费用。
- 兼容性:该方法在浏览器、设备和环境中的适用范围,是否需要回退逻辑。
- 用户便利性:用户是否需要采取额外的步骤才能使用 AI 系统,例如下载模型。
- 开发者便利性:对于大多数开发者而言,在没有专业 AI 知识的情况下,部署、集成和维护模型有多么快速和轻松。
下表提供了一个示例,其中估算了每个平台在各项标准方面的表现(1 为最低,5 为最高)。
| 标准 | 客户 | 设备 | ||
| 内置 AI 或设备端 | 自定义模型 | 代管式服务 | 自主托管模式 | |
| 模型功率 |
为什么模型功率为 2 星?内置 AI 和设备端 AI 使用预加载的小型浏览器模型,这些模型针对狭窄的特定任务功能进行了优化,而不是开放式对话或推理。 |
为什么模型功率为 3 星?与内置 AI 相比,自定义客户端库的灵活性更高,但您仍会受到下载大小、内存限制和用户硬件的限制。 |
为什么模型功率为 4 星?借助托管服务和自行托管,您可以访问大型先进模型,这些模型能够进行复杂的推理、处理长上下文,并涵盖广泛的任务。 |
|
| 可自定义性 |
为什么可自定义性评分为 1 星?内置模型不允许访问模型权重或训练数据。自定义其行为的主要方式是通过提示工程 |
为什么可自定义性评分为 5 星?此选项可让您控制模型选择和权重。许多客户端库还支持模型微调和训练。 |
为什么可自定义性评分为 1 星?托管式服务可提供强大的模型,但对模型的内部行为的控制程度最低。自定义通常仅限于提示和输入上下文。 |
为什么可自定义性评分为 5 星?自托管模型可让您完全控制模型权重、训练数据、微调和部署配置。 |
| 准确率 |
为什么准确度只有 2 星?内置模型的准确率足以应对范围明确的任务,但模型大小和泛化能力有限,因此对于复杂或细致的输入,可靠性会降低。 |
为什么精确度为 3 星?在模型选择过程中,可以提高自定义客户端模型的准确率。不过,它仍然会受到模型大小、量化和客户端硬件可变性的限制。 |
为什么精确度为 5 星?托管服务通常具有相对较高的准确性,这得益于大型模型、广泛的训练数据和持续的提供商改进。 |
为什么准确度为 4 星?准确度可能很高,但取决于所选模型和调整力度。性能可能不如托管式服务。 |
| 网络延迟 |
为什么网络延迟的评分为 5 星?处理直接在用户设备上进行。 |
为什么网络延迟的评分为 2 星?需要往返服务器。 |
||
| 隐私权 |
为什么隐私保护方面获得 5 星评价?用户数据应默认保留在设备上,以最大限度减少数据泄露风险并简化隐私权合规工作。 |
为什么隐私保护方面的评分为 2 星?用户输入必须发送到外部服务器,这会增加数据泄露风险并提高合规性要求。不过,有一些特定的解决方案可以缓解隐私权问题,例如 Private AI Compute。 |
为什么隐私保护方面的星级为 3 星?数据仍受组织控制,但会离开用户的设备,因此需要采取安全处理和合规性措施。 |
|
| 固定费用 |
为什么固定费用的星级为 5 星?模型在用户现有设备上运行,因此无需支付额外基础设施费用。 |
为什么固定费用的星级为 5 星?大多数 API 都是按用量收费,因此没有固定费用。 |
为什么固定费用的星级为 2 星?固定成本包括基础设施、维护和运营开销。 |
|
| 每次请求费用 |
为什么“每次请求费用”指标的星级为 5 星?由于推理在用户设备上运行,因此无需按请求付费。 |
为什么为“每次请求费用”评 2 星?托管式服务通常按请求收费。扩缩费用可能会非常高,尤其是在流量非常大的情况下。 |
为什么“每次请求费用”的星级为 3 星?没有直接的单次请求费用;实际单次请求费用取决于基础设施利用率。 |
|
| 兼容性 |
为什么兼容性评分为 2 星?可用性因浏览器和设备而异,需要为不支持的环境提供回退。 |
为什么兼容性评分为 1 星?兼容性取决于硬件功能和运行时支持,因此在不同设备上的覆盖范围有限。 |
为什么兼容性评分为 5 星?服务器端平台广泛兼容,适合所有用户,因为推理是在服务器端进行的,客户端只使用 API。 |
|
| 用户便利性 |
为什么用户便利性为 3 星?内置 AI 通常在可用后可无缝使用,但需要先下载模型并获得浏览器支持。 |
为什么用户便利性方面的评分为 2 星?用户可能会因下载或硬件不受支持而遇到延迟。 |
为什么用户便利性为 4 星?无需下载或满足设备要求,可立即使用,提供顺畅的用户体验。不过,如果网络连接较弱,可能会出现延迟。 |
|
| 开发者便利性 |
为什么开发者便利性为 5 星?内置 AI 需要极少的设置、无需基础架构,并且对 AI 专业知识的要求不高,因此易于集成和维护。 |
为什么 2 星级便利性?需要管理模型、运行时、性能优化和设备兼容性。 |
为什么开发者便利性方面的评分为 4 星?托管式服务可简化部署和扩缩。不过,它们仍然需要 API 集成、费用管理和提示工程。 |
为什么开发者便利性评分为 1 星?自定义服务器端部署需要具备基础设施、模型管理、监控和优化方面的专业知识。 |
| 维护工作量 |
为什么维护工作评分为 4 星?浏览器会处理模型更新和优化,但开发者必须适应不断变化的可用性。 |
为什么维护工作量为 2 星?随着浏览器和设备的发展,需要不断更新模型、调整性能和改进兼容性。 |
为何维护工作评分为 5 星?维护由提供商负责。 |
为什么维护工作量为 2 星?需要持续维护,包括模型更新、基础设施管理、扩缩和安全性。 |
分析利弊权衡
为了说明决策过程,我们将向中型电子商务平台 Example Shoppe 添加另一项功能。您希望节省非工作时间的客户服务成本,因此决定构建一个 AI 赋能的助理,用于回答用户关于订单、退货和产品的问题。
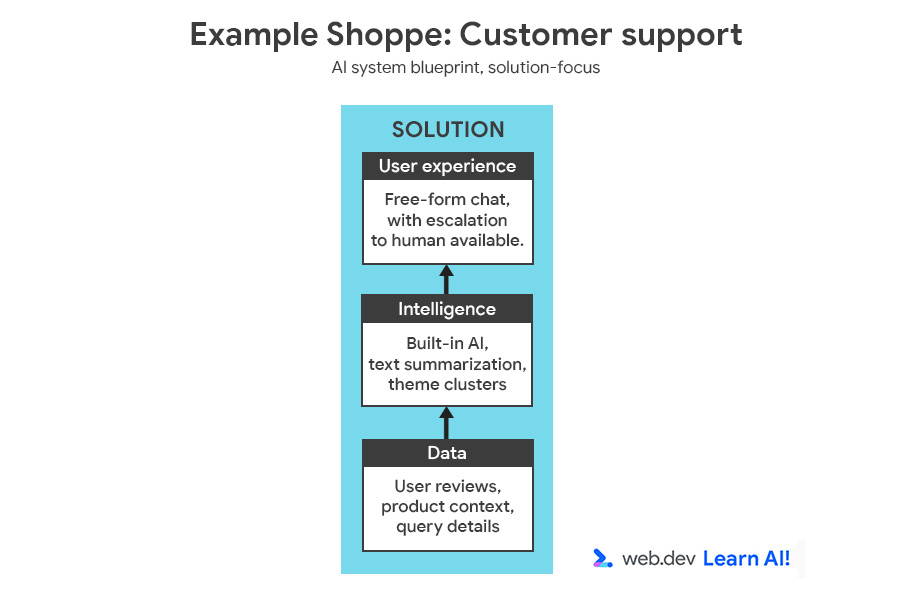
您可以查看完整的 AI 系统蓝图,其中包含机遇和解决方案。
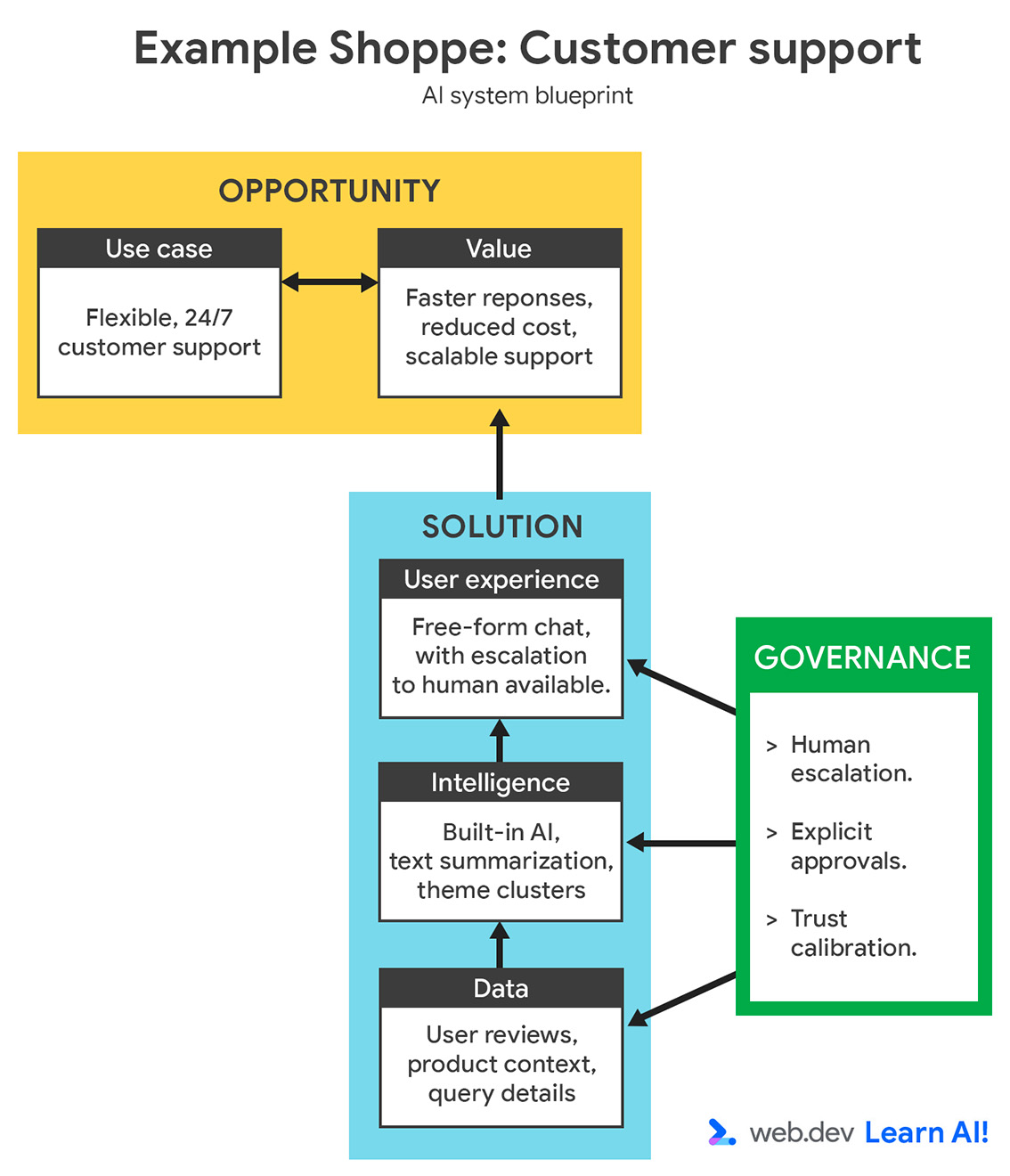{kind=link}
从两个角度分析该场景:用例要求和业务或团队限制。
| 要求 | 分析 | 标准 | 含义 |
| 高准确度和多功能性 | 用户会提出各种有关订单、商品和退货的复杂问题。 | 模型功率、准确率 | 需要大语言模型 (LLM)。 |
| 数据专业性 | 它需要回答与公司数据、产品和政策相关的问题。 | 可定制性 | 需要数据注入(例如 RAG),但不需要模型微调。 |
| 要求 | 分析 | 标准 | 含义 |
| 用户群 | 数十万用户。 | 可伸缩性、兼容性 | 需要能够处理高流量且可靠的架构。 |
| 发布后重点 | 团队将在版本 1 发布后转到其他项目。 | 维护工作量 | 需要一种只需极少日常维护的解决方案。 |
| 团队专业水准 | 经验丰富的 Web 开发者,但 AI/机器学习专业知识有限 | 开发者便利性 | 解决方案必须易于部署和集成,无需具备专业的 AI 技能。 |
现在,您已经确定了条件的优先级,接下来可以参考权衡估计表,确定哪个平台符合您的最高优先级条件:
| 优先考虑的条件 | 平台胜出方 |
| 模型功率 | 服务器端 |
| 可定制性 | 服务器端:自托管模式 |
| 开发者便利性 | 服务器端:受管理的 服务 |
| 维护工作量 | 服务器端:代管式服务 |
| 兼容性和可伸缩性 | 服务器端 |
从上述细分中可以看出,您应该使用服务器端 AI,最好是托管服务。这为复杂的客户问题提供了一个多功能模型。 通过将基础架构、模型质量和正常运行时间分流给提供商,最大限度地减少维护和开发工作量。
虽然可自定义程度有限,但对于模型工程经验有限的 Web 开发团队来说,这是一个值得的权衡。
检索增强生成 (RAG) 设置有助于在推理时为模型提供相关背景信息。
混合 AI
成熟的 AI 系统很少在单一平台上运行或使用单一模型。而是通过分配 AI 工作负载来优化权衡。
发现混合 AI 的机会
发布后,您应根据实际数据和反馈意见来完善要求。在我们的示例“Example Shoppe”中,您等待了几个月来分析结果,并发现以下情况:
- 大约 80% 的请求都是重复的(例如“我的订单在哪里?”、“我的订单在哪里?”、“我的订单在哪里?”)。“如何退货?”)。向代管式服务发送这些请求会产生大量开销和费用。
- 只有 20% 的请求需要更深入的推理和开放式互动对话。
轻量级本地模型可以对用户输入进行分类,并回答常规查询,例如“你们的退货政策是什么?”您可以将复杂、罕见或模棱两可的问题路由到服务器端模型。
通过实现服务器端和客户端 AI,您可以降低成本和延迟时间,同时在需要时保持对强大推理功能的访问。
分配工作负载
若要为 Example Shoppe 构建此混合系统,您应先定义默认系统。在这种情况下,最好从客户端开始。在以下两种情况下,应用应路由到服务器端 AI:
- 基于兼容性的回退:如果用户的设备或浏览器无法处理请求,则应回退到服务器
- 基于能力的升级:如果请求对于客户端模型来说过于复杂或开放式,则应根据预先确定的标准将其升级到更大的服务器端模型。您可以使用模型将请求分类为常见(在客户端执行任务)或不常见(将请求发送到服务器端系统)。例如,如果客户端模型确定问题与不常见的问题相关,例如以其他币种获得退款。
灵活性会带来更多复杂性
在两个平台之间分配工作负载可提高灵活性,但也会增加复杂性:
- 编排:两个执行环境意味着更多可移动的部件。您需要用于路由、重试和回退的逻辑。
- 版本控制:如果您在多个平台中使用同一模型,则该模型必须在两个环境中保持兼容。
- 提示工程和上下文工程:如果您在每个平台上使用不同的模型,则需要针对每个模型执行提示工程。
- 监控:日志和指标是分开的,需要额外的统一工作。
- 安全性:您需要维护两个攻击面。本地端点和云端点都需要强化。
这是另一个需要权衡的因素,供您参考。如果您的小团队正在构建非必要功能,则可能不想增加这种复杂性。
要点总结
预计平台选择会不断变化。从用例入手,与团队的经验和资源保持一致,并随着产品和 AI 成熟度的提高而不断迭代。您的任务是为用户找到速度、隐私保护和控制之间的最佳平衡点,然后灵活地进行构建。这样一来,您就可以适应不断变化的需求,并受益于未来的平台和模型更新。
资源
- 由于平台和模型选择相互依赖,因此请详细了解模型选择。
- 了解如何利用混合 AI 和客户端 AI 突破云端限制
检验您的掌握情况
为应用选择 AI 平台时,需要考虑的两个主要因素是什么?
何时最好为平台选择 Gemini Pro 等服务器端托管服务?
实现混合 AI 系统的主要优势是什么?