
Sztuczna inteligencja predykcyjna (lub analityczna) to zbiór algorytmów, które pomagają zrozumieć istniejące dane i przewidywać, co prawdopodobnie wydarzy się w przyszłości. Na podstawie wzorców historycznych modele AI do prognozowania uczą się różnych zadań analitycznych, które pomagają użytkownikom interpretować dane:
- Klasyfikacja: grupowanie elementów w wstępnie zdefiniowanych kategoriach na podstawie wzorców w danych. Na przykład sklep internetowy może klasyfikować użytkowników według zamiaru (badanie, zakup, zwroty), aby odpowiednio dostosowywać rekomendacje.
- Regresja: prognozowanie wartości liczbowych, takich jak współczynnik zaangażowania, czas trwania sesji lub prawdopodobieństwo konwersji.
- Rekomendacja: sugeruj produkty, które są najbardziej odpowiednie dla danego użytkownika lub kontekstu. Pomyśl o „użytkownicy podobni do Ciebie też oglądali” lub „rekomendowane samouczki na podstawie Twoich postępów”.
- Prognozowanie i wykrywanie anomalii: model przewiduje przyszłe zdarzenia, np. nagły wzrost ruchu, lub wykrywa nietypowe zachowania, np. anomalie płatności lub oszustwa.
Niektóre usługi są w całości oparte na predykcyjnej AI, np. narzędzia do odkrywania muzyki. W innych przypadkach predykcyjna AI ulepsza deterministyczne działanie, np. w witrynie streamingowej z spersonalizowanymi rekomendacjami. Prognozująca AI może też być potężnym narzędziem wewnętrznym: możesz jej używać do analizowania danych o produktach i użytkownikach, aby uzyskiwać statystyki i podejmować bardziej przemyślane działania.
Pętla predykcyjnej AI
Tworzenie predykcyjnego systemu AI przebiega w cyklu iteracyjnym: zdefiniuj możliwości, przygotuj dane, wytrenuj model, oceń model i wdroż model.
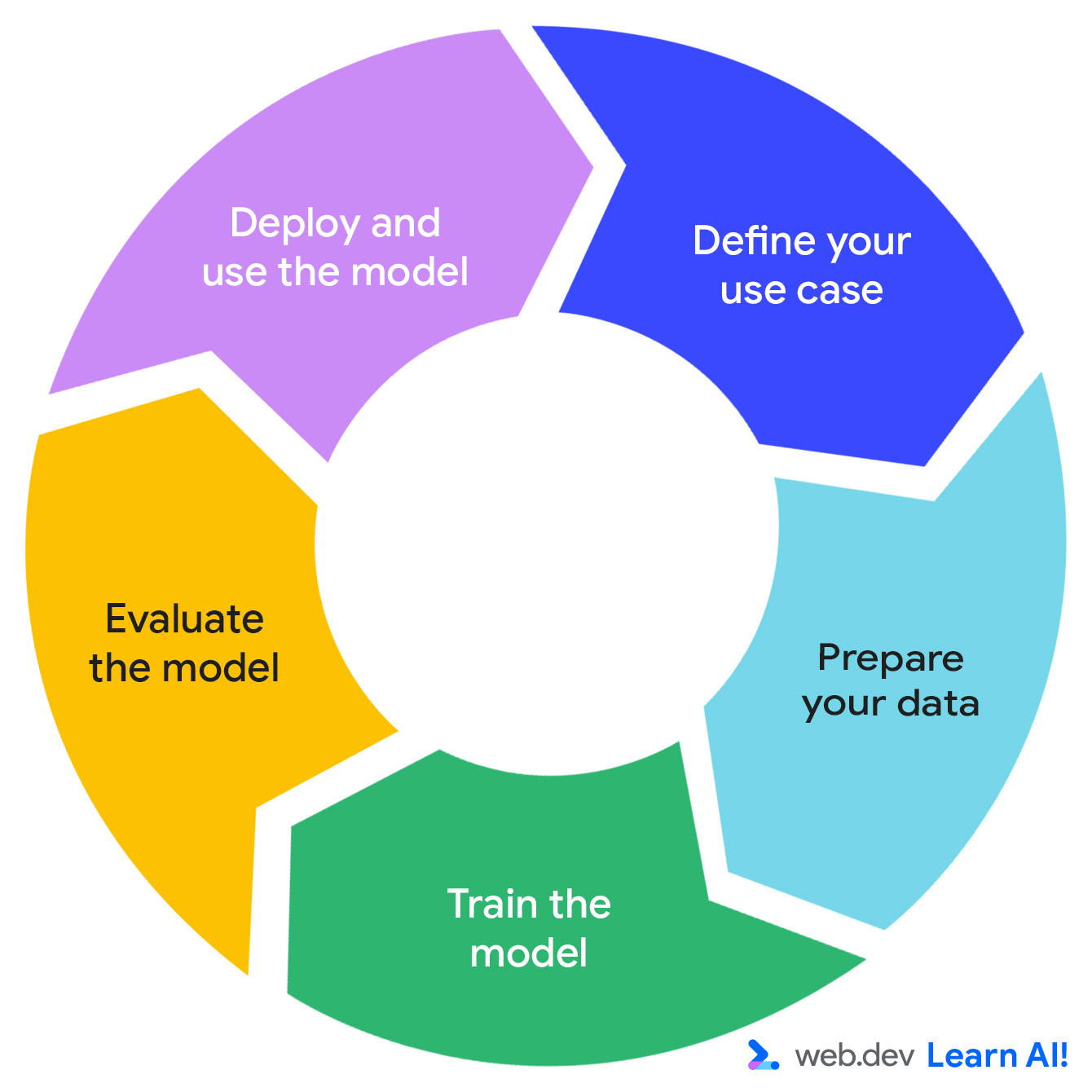
Wyobraź sobie, że pracujesz nad aplikacją zwiększającą produktywność opartą na subskrypcji o nazwie Do All The Things. Zbierasz już dane o użytkowaniu, takie jak wyświetlenia stron, długość sesji, korzystanie z funkcji i odnowienia subskrypcji. Teraz chcesz wyodrębnić z danych więcej przydatnych informacji. Oto jak przebiega podróż przez pętlę predykcyjnej AI.
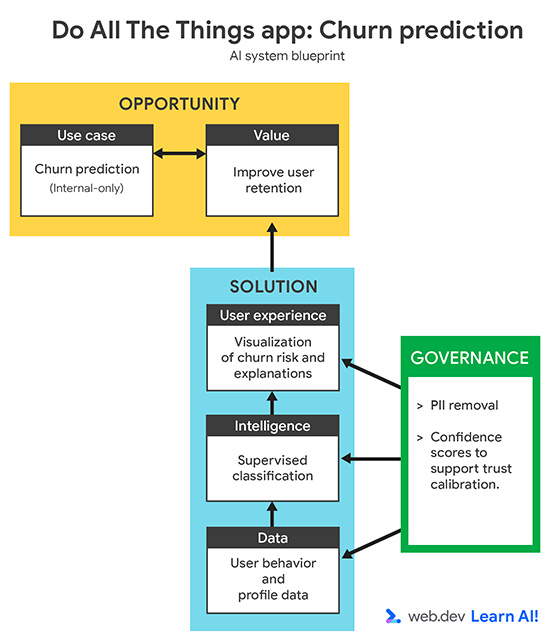
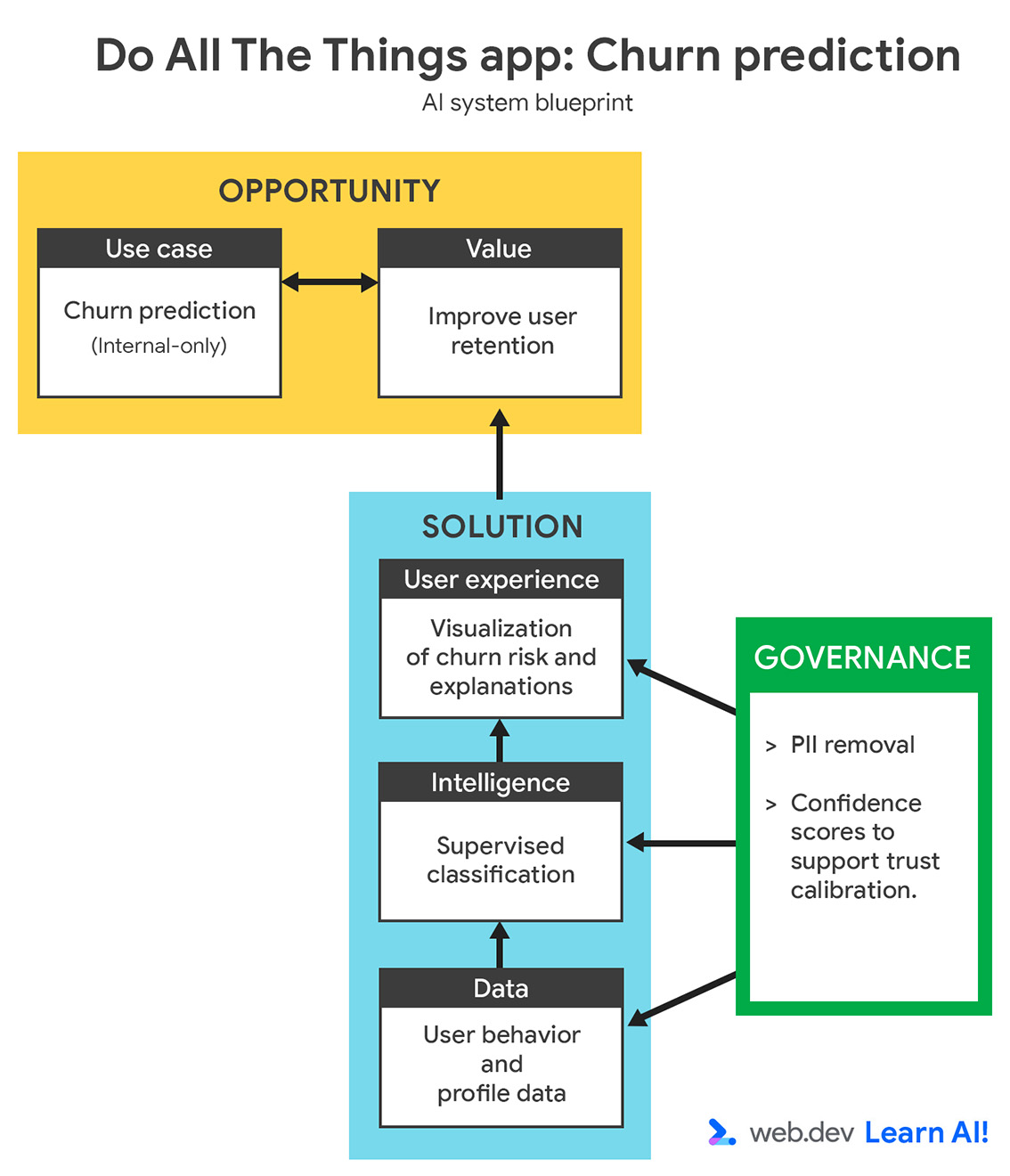
Określ swój przypadek użycia
{kind=link}
W ciągu ostatnich 3 miesięcy Twój współczynnik rezygnacji wzrósł. Zamiast reagować po anulowaniu subskrypcji przez użytkowników, chcesz używać predykcyjnej AI do identyfikowania użytkowników, którzy prawdopodobnie zrezygnują z usługi, zanim to zrobią. Celem jest dostarczanie zespołowi ds. sukcesu klienta wczesnych sygnałów, aby mógł on podejmować ukierunkowane, proaktywne działania mające na celu utrzymanie zagrożonych użytkowników.
Definiując przypadek użycia AI do prognozowania, zacznij od sprawdzenia, czy na pytanie można odpowiedzieć na podstawie danych. Mogą to być dane, które zostały już zebrane, lub dane, które można w realny sposób zebrać w przyszłości. Ten krok często wymaga współpracy z ekspertami w danej dziedzinie, np. z zespołami ds. sukcesu klienta, rozwoju lub marketingu, aby mieć pewność, że prognoza jest istotna i umożliwia podjęcie odpowiednich działań.
Dobra definicja problemu powinna zawierać:
- Cel: na jaki wynik biznesowy chcesz mieć wpływ? Na przykład chcesz zmniejszyć liczbę rezygnacji, włączając proaktywne działania.
- Dane wejściowe: z jakich sygnałów historycznych uczy się model? Na przykład podajesz wzorce użytkowania, typy planów i interakcje związane z pomocą.
- Dane wyjściowe: co wygeneruje model? Na przykład chcesz, aby model obliczał prawdopodobieństwo rezygnacji każdego użytkownika.
- Użytkownik: kto korzysta z prognozy lub na jej podstawie podejmuje działania? Te dane są przeznaczone na przykład dla menedżerów ds. sukcesów klientów.
- Kryteria sukcesu: jak mierzysz wpływ? Na przykład mierzysz wskaźnik utrzymania, aby sprawdzić, czy udało Ci się zmniejszyć liczbę rezygnacji.
Określając te szczegóły na początku, możesz uniknąć typowej pułapki: zbudowania modelu niestandardowego, który jest technicznie poprawny, ale nigdy nie jest używany.
Przygotowywanie danych
Aby dostarczyć modelowi przydatne sygnały uczenia, musisz oznaczyć dane historyczne idealnymi prognozami. Oznacz użytkowników etykietą Do All The Things jako „zrezygnowali” lub „nie zrezygnowali”.
Następnie we współpracy z zespołem ds. sukcesu klienta określ, które funkcje związane z zachowaniem są najbardziej istotne w przypadku prognozowania rezygnacji. Ogranicz zbiór danych do tych kluczowych cech i usuń niepotrzebne pola, aby model nie musiał przetwarzać szumu. Pamiętaj o ochronie danych. Usuwaj informacje umożliwiające identyfikację, takie jak imiona i nazwiska czy adresy e-mail, i przechowuj tylko zagregowane dane o zachowaniu.
Poniższa tabela zawiera fragment wynikowego zbioru danych:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | premium | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | okres próbny subskrypcji Google AI Pro | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | bezpłatnie | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | premium | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | okres próbny subskrypcji Google AI Pro | 4.2 | 2 | 1 | 3 | 1 |
Dzięki temu model otrzymuje czyste dane wejściowe w postaci liczb i kategorii (np. plan_type lub avg_session_time) oraz wyraźną etykietę docelową (churned). Kategorie należy przekształcić w niepowtarzalne identyfikatory liczbowe.
Na koniec podziel zbiór danych na 3 podzbiory:
- zbiór treningowy (zwykle około 70–80%) do uczenia modelu,
- Zbiór walidacyjny (czasami nazywany też zbiorem deweloperskim) do dostrajania hiperparametrów i zapobiegania przeuczeniu.
- Zbiór testowy, aby ocenić skuteczność modelu w przypadku całkowicie nowych danych.
Pomaga to modelowi uogólniać decyzje zamiast polegać na zapamiętanych przykładach historycznych.
Wytrenuj model
W przeciwieństwie do generatywnej AI, która często bazuje na dużych, wstępnie wytrenowanych modelach, większość systemów predykcyjnej AI korzysta z modeli trenowanych samodzielnie. Dzieje się tak, ponieważ zadania predykcyjne są ściśle powiązane z Twoim produktem i użytkownikami. Narzędzia takie jak scikit-learn (Python), AutoML (bez kodu lub z niewielką ilością kodu) czy TensorFlow.js (JavaScript) ułatwiają trenowanie i ocenianie modeli predykcyjnych bez konieczności zagłębiania się w matematykę.
W naszym przykładzie dotyczącym rezygnacji klientów przekazujemy oczyszczony zbiór treningowy do nadzorowanego algorytmu klasyfikacji, takiego jak regresja logistyczna lub sieć neuronowa. Wypróbuj kilka opcji, aby określić, która najlepiej pasuje do Twoich danych.
Model uczy się, które wzorce zachowań są powiązane z rezygnacją. Na koniec może przypisać każdemu użytkownikowi wynik prawdopodobieństwa. Na przykład istnieje 72% ryzyko, że użytkownik X anuluje subskrypcję w przyszłym miesiącu.
Po każdej iteracji trenowania oceń uzyskany model za pomocą zbioru walidacyjnego. Wydajność modelu można zwiększyć, dostosowując hiperparametry, ale także wprowadzając ukierunkowane ulepszenia w zbiorze danych.
Ocena modelu
Etykiety w zbiorze danych zawierają dane podstawowe, z którymi możesz porównać wyniki modelu. Kluczowe dane do śledzenia to:
- Precyzja: ilu użytkowników oznaczonych jako „utraceni” faktycznie zrezygnowało z usługi?
- Recall: ilu użytkowników, którzy zrezygnowali, zostało wykrytych przez model?
- Wynik F1: pojedyncza liczba, która równoważy precyzję i czułość. Jest przydatna, gdy chcesz uzyskać ogólną miarę dokładności bez nadmiernej optymalizacji jednego z tych parametrów kosztem drugiego.
Zbyt wiele fałszywych alarmów prowadzi do marnowania wysiłków na rzecz utrzymania klientów, a zbyt wiele fałszywych braków dopasowania – do utraty klientów. Odpowiedni kompromis zależy od priorytetów Twojej firmy. Na przykład Twoja firma może woleć mieć do czynienia z kilkoma fałszywymi alarmami, jeśli zwiększy to prawdopodobieństwo dotarcia do większej liczby użytkowników, zanim opuszczą oni witrynę.
Wdrażanie i utrzymywanie modelu
Po zweryfikowaniu możesz wdrożyć model za pomocą interfejsu API lub jako uproszczoną usługę po stronie klienta zintegrowaną z panelem analitycznym. Każdego dnia może oceniać użytkowników i aktualizować wizualizację ryzyka rezygnacji, co pozwala zespołowi określać priorytety w zakresie kontaktu z użytkownikami. Aby zachować dokładność i niezawodność, skorzystaj z tych wskazówek od zespołów ds. operacji związanych z uczeniem maszynowym (MLOps):
- Monitorowanie dryfu danych: wykrywanie zmian w zachowaniu użytkowników i sytuacji, w której dane treningowe przestają odzwierciedlać rzeczywistość.
- Na przykład po wprowadzeniu znaczących zmian w interfejsie użytkownicy mogą inaczej korzystać z funkcji, co spowoduje, że prognozy rezygnacji staną się mniej dokładne.
- Wyciąganie wniosków z błędów: identyfikuj typowe wzorce błędnych prognoz i dodawaj ukierunkowane przykłady, aby ulepszyć kolejny cykl trenowania.
- Na przykład model często oznacza zaawansowanych użytkowników jako osoby, które mogą zrezygnować z usługi, ponieważ otwierają oni wiele zgłoszeń. Po sprawdzeniu dodajesz nowe funkcje, które odróżniają rozwiązywanie problemów od wycofania się.
- Regularnie ponownie trenuj model: nawet jeśli skuteczność wydaje się stabilna, okresowo odświeżaj model, aby uwzględniać sezonowe trendy, aktualizacje produktów lub zmiany cen.
- Na przykład po wprowadzeniu abonamentów rocznych ponownie trenujesz model, ponieważ struktura cenowa zmienia zachowanie użytkowników przed odnowieniem subskrypcji.
Ten cykl życia jest podstawą predykcyjnej AI. Dzięki narzędziom takim jak MLflow i Weights & Biases możesz przeprowadzić ten proces bez specjalistycznej wiedzy z zakresu uczenia maszynowego.
Typowe problemy i sposoby ich rozwiązywania
Błędy będą się zdarzać, ale możesz się zabezpieczyć przed typowymi przyczynami, które mogą obniżyć skuteczność i zaufanie użytkowników:
- Dane niskiej jakości: jeśli dane wejściowe są zaszumione lub niekompletne, prognozy również będą takie. Aby temu zapobiec, wizualizuj i weryfikuj dane przed trenowaniem. Sprawdź, czy masz wymagane sygnały uczenia się i obsługuj brakujące wartości. Monitoruj jakość danych w środowisku produkcyjnym.
Nadmierne dopasowanie: model bardzo dobrze radzi sobie z danymi treningowymi, ale zawodzi w przypadku nowych danych. Aby temu zapobiec, używaj walidacji krzyżowej, regularyzacji i zbiorów danych testowych. Pomaga to modelowi uogólniać wyniki poza przykłady treningowe.
Dryf danych: zachowania i środowiska użytkowników się zmieniają, ale model nie. Aby temu zapobiec, zaplanuj ponowne trenowanie i dodaj monitorowanie, które wykryje, kiedy dokładność zacznie spadać.
Nieodpowiednie dane: ogólna dokładność nie zawsze odzwierciedla priorytety użytkowników. Czasami na przykład „koszt” konkretnego błędu ma większe znaczenie. W przypadku wykrywania oszustw pominięcie oszukańczego przypadku (wynik fałszywie negatywny) jest znacznie gorsze niż oznaczenie niewinnego przypadku (wynik fałszywie pozytywny). Aby temu zapobiec, dostosuj statystyki do rzeczywistych celów związanych z wykrywaniem oszustw.
Większość tych problemów nie jest poważna. Wdrażaj system stopniowo i rozwiązuj problemy, gdy się pojawią.
Kluczem do tego elastycznego podejścia jest możliwość obserwacji. Wersjonuj modele, rejestruj charakterystykę dokładności i narzędzia użyte do ich tworzenia, śledź wydajność w czasie i utrzymuj aktywny monitoring. Gdy coś się zmieni lub zepsuje, będziesz w stanie wykryć i naprawić problem, zanim zauważą go użytkownicy.
Wnioski
Predykcyjna AI przekształca Twoje dotychczasowe dane w prognozy, ujawniając, co prawdopodobnie wydarzy się w przyszłości i gdzie należy podjąć działania. Jest to najbardziej konkretna i mierzalna forma AI. Skup się na dobrze zdefiniowanych problemach, które można wyrazić za pomocą danych, wprowadzaj kolejne iteracje w miarę rozwoju produktu i monitoruj skuteczność na przestrzeni czasu.
W następnym module dowiesz się więcej o generatywnej AI, która pomaga tworzyć nowe treści na podstawie dostępnych danych.
Zasoby
Jeśli chcesz poznać matematyczne podstawy predykcyjnej AI, zapoznaj się z tymi materiałami:
- Szybkie szkolenia z uczenia maszynowego dotyczące klasyfikacji, regresji liniowej i regresji logistycznej.
- Autorka kursu, Janna Lipenkova, napisała więcej o temacie predykcyjnej AI w rozdziale 4 książki The Art of AI Product Development: Delivering Business Value (w języku angielskim).
- Artificial Intelligence: A Modern Approach (autorzy: Stuart Jonathan Russell i Peter Norvig). Książka została pierwotnie opublikowana w 1995 roku, a jej najnowsze wydanie ukazało się w 2021 roku. Jest to powszechnie nauczane w ramach programów inżynierii AI.
- Pattern Recognition and Machine Learning autorstwa Christophera M. Bishopa, który w bardzo kompleksowy i akademicki sposób podchodzi do uczenia się predykcyjnej AI.
Sprawdź swoją wiedzę
Jaka jest główna funkcja predykcyjnej AI?
Które zadanie polega na grupowaniu elementów w zdefiniowanych wcześniej kategoriach na podstawie wzorców?
Dlaczego w „pętli predykcyjnej AI” należy podzielić zbiór danych na zbiory do trenowania, walidacji i testowania?
Które dane równoważą precyzję i czułość, aby zapewnić ogólną miarę dokładności?
Czym jest dryf danych i jak go ograniczyć?