
Users loading your site a second time will use their HTTP cache, so make sure it works well.

This post is a companion to the Love your cache video, part of the Extended Content at Chrome Dev Summit 2020. Be sure to check out the video:
When users load your site a second time, their browser will use resources inside its HTTP cache to help make that load faster. But the standards for caching on the web date back to 1999, and they're defined pretty broadly—determining whether a file, like CSS or an image, might be fetched again from the network versus loaded from your cache is a bit of an inexact science.
In this post, I'll talk through a sensible, modern default for caching—one that actually does no caching at all. But that's just the default, and it's of course more nuanced than just "turning it off". Read on!
Goals
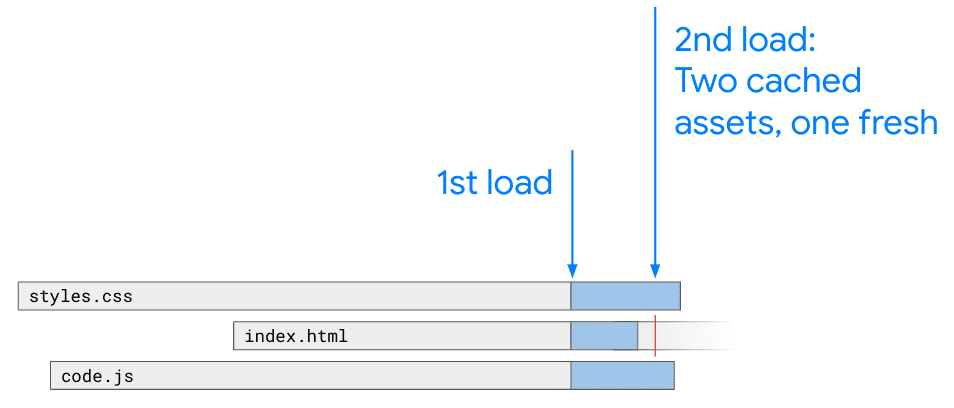
When a site is loaded for the 2nd time, you have two goals:
- Ensure that your users get the most up-to-date version available—if you've changed something, it should be reflected quickly
- Do #1 while fetching as little from the network as possible
In the broadest sense, you only want to send the smallest change to your clients when they load your site again. And structuring your site to ensure the most efficient distribution of any change is challenging (more on that below, and in the video).
Having said that, you also have other knobs when you consider caching—perhaps you've decided to let a user's browser HTTP cache hold onto your site for a long time so that no network requests are required to serve it at all. Or you've constructed a service worker that will serve a site entirely offline before checking if it's up-to-date. This is an extreme option, which is valid—and used for many offline-first app-like web experiences—but the web doesn't need to be at a cache-only extreme, or even a completely network-only extreme.
Background
As web developers, we're all accustomed to the idea of having a "stale cache". But we know, almost instinctively, the tools available to solve this: do a "hard refresh", or open an incognito window, or use some combination of your browser's developer tools to clear a site's data.
Regular users out there on the internet don't have that same luxury. So while we have some core goals of ensuring our users have a great time with their 2nd load, it's also really important to make sure they don't have a bad time or get stuck. (Check out the video if you'd like to hear me talk about how we nearly got the web.dev/live site stuck!)
For a bit of background, a really common reason for "stale cache" is actually
the 1999-era default for caching. It relies on the Last-Modified header:
Every file you load is kept for an additional 10% of its current lifetime, as
your browser sees it. For example, if index.html was created a month ago,
it'll be cached by your browser for about another three days.
This was a well-intentioned idea back in the day, but given the tightly integrated nature of today's websites this default behavior means it's possible to get into a state where a user has files designed for different releases of your website (e.g., the JS from Tuesday's release, and the CSS from Friday's release), all because those files were not updated at exactly the same time.
The well-lit path
A modern default for caching is to actually do no caching at all, and use CDNs to bring your content close to your users. Every time a user loads your site, they'll go to the network to see whether it's up-to-date. This request will have low latency, as it'll be provided by a CDN geographically close to each end user.
You can configure your web host to respond to web requests with this header:
Cache-Control: max-age=0,must-revalidate,public
This basically says; the file is valid for no time at all, and you must validate it from the network before you can use it again (otherwise it's only "suggested").
This validation process is relatively cheap in terms of bytes transferred—if a large image file hasn't changed, your browser will receive a small 304 response—but it costs latency as a user must still go to the network to find out. And this is the primary downside of this approach. It can work really well for folks on fast connections in the 1st world, and where your CDN of choice has great coverage, but not for those folks who might be on slower mobile connections or using poor infrastructure.
Regardless, this is a modern approach that is the default on a popular CDN, Netlify, but can be configured on nearly any CDN. For Firebase Hosting, you can include this header in the hosting section of your firebase.json file:
"headers": [
// Be sure to put this last, to not override other headers
{
"source": "**",
"headers": [ {
"key": "Cache-Control",
"value": "max-age=0,must-revalidate,public"
}
}
]
So while I still suggest this as a sensible default, it's only that—the default! Read on to find out how to step in and upgrade the defaults.
Fingerprinted URLs
By including a hash of the file's content in the name of assets, images, and so
on served on your site, you can ensure that these files will always have unique
content—this will result in files named sitecode.af12de.js for example. When
your server responds to requests for these files, you can safely instruct your
end-user's browsers to cache them for a long time by configuring them with this
header:
Cache-Control: max-age=31536000,immutable
This value is a year, in seconds. And according to the spec, this is effectively equal to "forever".
Importantly, don't generate these hashes by hand—it's too much manual work! You can use tools like Webpack, Rollup and so on to help you out with this. Be sure to read more about them on Tooling Report.
Remember that it's not just JavaScript that can benefit from fingerprinted URLs; assets like icons, CSS and other immutable data files can also be named this way. (And be sure to watch the video above to learn a bit more about code splitting, which lets you ship less code whenever your site changes.)
Regardless of how your site approaches caching, these sorts of fingerprinted files are incredibly valuable to any site you might build. Most sites just aren't changing on every release.
Of course, we can't rename our 'friendly', user-facing pages this way: renaming
your index.html file to index.abcd12.html—that's infeasible, you can't tell
users to go to a new URL every time they load your site! These 'friendly' URLs
can't be renamed and cached in this way, which leads me on to a possible middle
ground.
The middle ground
There's obviously room for a middle ground when it comes to caching. I've presented two extreme options; cache never, or cache forever. And there will be a number of files which you might like to cache for a time, such as the "friendly" URLs I mentioned above.
If you do want to cache these "friendly" URLs and their HTML, it's worth considering what dependencies they include, how they may be cached, and how caching their URLs for a time might affect you. Let's look at a HTML page which includes an image like this:
<img src="/images/foo.jpeg" loading="lazy" />
If you update or change your site by deleting or changing this lazy-loaded
image, users who view a cached version of your HTML might get an incorrect or
missing image—because they've still cached the original /images/foo.jpeg when
they revisit your site.
If you're careful, this might not affect you. But broadly it's important to remember that your site—when cached by your end users—no longer just exists on your servers. Rather, it may exist in pieces inside the caches of your end user's browsers.
In general, most guides out there on caching will talk about this kind of setting—do you want to cache for an hour, several hours, and so on. To set this kind of cache up, use a header like this (which caches for 3600 seconds, or one hour):
Cache-Control: max-age=3600,immutable,public
One last point. If you're creating timely content which typically might only be accessed by users once—like news articles!—my opinion is that these should never be cached, and you should use our sensible default above. I think we often overestimate the value of caching over a user's desire to always see the latest and greatest content, such as a critical update on a news story or current event.
Non-HTML options
Aside from HTML, some other options for files that live in the middle ground include:
In general, look for assets that don't affect others
- For example: avoid CSS, as it causes changes in how your HTML is rendered
Large images that are used as part of timely articles
- Your users probably aren't going to visit any single article more than a handful of times, so don't cache photos or hero images forever and waste storage
An asset which represents something that itself has lifetime
- JSON data about the weather might only be published every hour, so you can cache the previous result for an hour—it won't change in your window
- Builds of an open-source project might be rate-limited, so cache a build status image until it's possible that the status might change
Summary
When users load your site a second time, you've already had a vote of confidence—they want to come back and get more of what you're offering. At this point, it's not always just about bringing that load time down, and you have a bunch of options available to you to ensure that your browser does only the work it needs to deliver both a fast and an up-to-date experience.
Caching is not a new concept on the web, but perhaps it needs a sensible default—consider using one and strongly opting-in to better caching strategies when you need them. Thanks for reading!
See also
For a general guide on the HTTP cache, check out Prevent unnecessary network requests with the HTTP Cache.